Environment Scaling for Agentic RL (中文版)
目录
为什么需要环境?
经典的监督微调把固定数据集当作 ground truth:模仿这些轨迹、预测这些标签。但一旦你想要一个必须在多轮中行动的智能体——敲一条 shell 命令、读报错、恢复、再试——而且世界的状态会因为智能体的动作而改变,这套就不够用了。静态数据集无法表达这一点:它只记录了一条轨迹,而不是智能体可能采取的所有动作所带来的后果。
正因如此,整个领域从”扩展静态数据”转向了一些人所说的 era of experience(经验时代):让智能体通过与环境交互来生成自己的轨迹,再用一个 verifier 给这些轨迹打分。产出训练信号的是环境,而不是数据集。最近的两篇综述正好刻画了这一转变——一篇围绕以环境为中心的循环来组织(Huang et al., 2025),另一篇围绕自演化(self-evolving)智能体(Gao et al., 2026)。
问题出在供给侧。Agentic 任务的 benchmark 是为评测而建的:几十到几百个手写、可执行、带 verifier 的任务。这足以衡量一个模型,却远不足以用 RL 去训练一个模型——RL “hungry for environments”,会很快把任务消耗光(Gandhi et al., 2026)。你没法为每个领域再手工标注上千个任务。于是问题变成:我们能不能把环境生成出来?
一个有用的重新表述:环境扮演两个角色。它是一个评测容器(跑一个策略、得到一个分数),并且——如果你能规模化地制造它——还是一个训练经验生成器。下文几乎所有工作,都是在让第二个角色变得便宜、可靠、可验证。
洞见 — 我们怎么知道”扩展”是否奏效? 从一开始就把一个区分记在心里:in-domain 分数(模型在它训练时所接触的合成任务上做得多好)vs. transfer(它在一个从未训练过、由人工精心构造的 benchmark 上做得多好)。前者很容易刷高;后者才是你真正在意的。我们会在 开放挑战 里回到这一点——而且已经有证据表明二者会显著背离。
要点。 环境之所以成为核心对象,是因为 RL 需要可验证的交互式经验,而其规模是手工构造的 benchmark 提供不了的。
环境的解剖
在扩展环境之前,我们得先就”环境到底是什么”达成一致。剥离掉具体领域,每个 agent environment 都有相同的五个部分:
- Task specification(任务说明) — 智能体要完成什么(一条自然语言指令,通常还附带智能体看不到的特权 ground truth)。
- State backend(状态后端) — 真正持有并改变状态的东西:容器的文件系统与进程、一个 SQL 数据库、或一组 mock services。
- Tool / action interface(工具/动作接口) — 智能体如何行动:shell 命令、带类型的 API/工具调用(越来越多地通过 Model Context Protocol (MCP) 暴露)、或发给用户的文本。
- Verifier / reward(验证器/奖励) — 一个检查最终(或中间)状态并返回标量的函数。正是这一部分让数据可训练。
- Agent scaffold(智能体脚手架) — 中介整个循环的 harness:它把历史喂给模型、解析模型的动作、在后端执行、并把得到的观测追加回去。
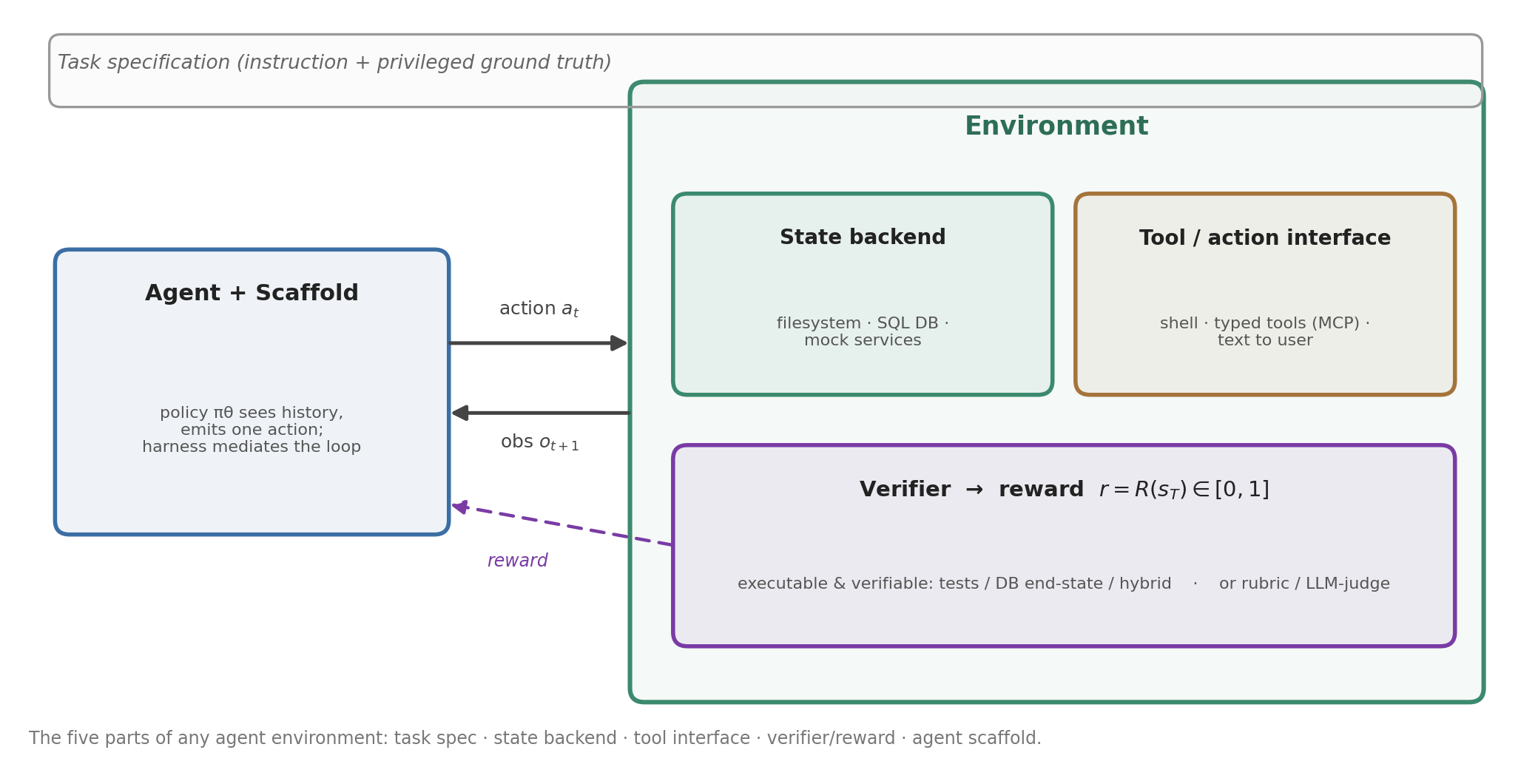 图 1. 智能体通过一个固定的 scaffold 行动;环境持有状态、暴露工具,并在每个 episode 结束时给出由 verifier 定义的奖励。
图 1. 智能体通过一个固定的 scaffold 行动;环境持有状态、暴露工具,并在每个 episode 结束时给出由 verifier 定义的奖励。
一点最小的形式化会有帮助。多数单智能体设定是一个部分可观测 MDP:在第 \(t\) 步,智能体看到观测 \(o_t\)、发出动作 \(a_t\)、世界按 \(s_{t+1}\sim T(\cdot\mid s_t,a_t)\) 转移,episode 结束时 verifier 返回奖励 \(r=R(s_T)\in[0,1]\)。策略 \(\pi_\theta(a_t\mid o_{\le t},a_{<t})\) 以整段历史为条件,因为 scaffold 把历史都保留在上下文里。
这个单智能体图景有一个重要的推广。在客服这类设定里,用户也是世界中的一个行动者——他们也能采取动作(例如”重启你的手机”)。此时正确的模型是一个带两个控制者(智能体与(被模拟的)用户)、作用在共享状态上的 decentralized POMDP (Dec-POMDP)。这种 dual-control(双控) 设定正是 τ²-bench (Barres et al., 2025) 所形式化的,它比通常那种用户只负责提供信息的 single-control benchmark 严格更难。
把 verifier 的区分讲清楚是值得的,因为它几乎驱动了后面所有的设计选择:
- Verifiable reward(可验证奖励) — 成功由执行某种确定性的东西来判定:这些测试通过了吗?数据库是否匹配预期末态?这类奖励便宜、客观、难以钻空子。
- Non-verifiable reward(不可验证奖励) — 质量是一种判断(这个解释好不好?),通常用 LLM-as-judge 或 rubric 来近似。写起来更便宜,也更容易被 hack。
整个”可扩展 RL 环境”的纲领,都建立在尽量贴近 executable + verifiable(可执行 + 可验证) 之上。当一个目标无法用执行来检查时,系统就退回到 rubric 或基于 judge 的验证——并继承它的脆弱性(见 设计选择的分类)。
两个贯穿全文的例子。 我们会带着这两个例子走完全文:
- E1 — 终端(仿 TerminalBench 2.0 风格)。 智能体被丢进一个 Linux 容器,里面有个 web 服务起不来(配置坏了或权限错误)。目标:让它正常提供服务。State backend: 文件系统 + 进程。Verifier: 一个 held-out 的
pytest,检查服务是否响应。- E2 — 零售退货(仿 τ²-bench 风格)。 一位顾客想退货。智能体必须遵守一份成文的退货政策、调用工具查订单并发起退款、把后端数据库带到正确末态——同时与一个被模拟的用户对话。State backend: SQL 数据库。Verifier: 数据库末态 + 政策/沟通检查。
要点。 每个环境都是 task spec + state backend + tool interface + verifier + scaffold。Verifier——以及它是否可执行——是最要紧的部分。
核心流水线
这是全文的核心。在终端智能体、SWE 智能体和工具使用智能体上,那些扩展环境的系统都在实例化同一套配方。名字各异,骨架不变。
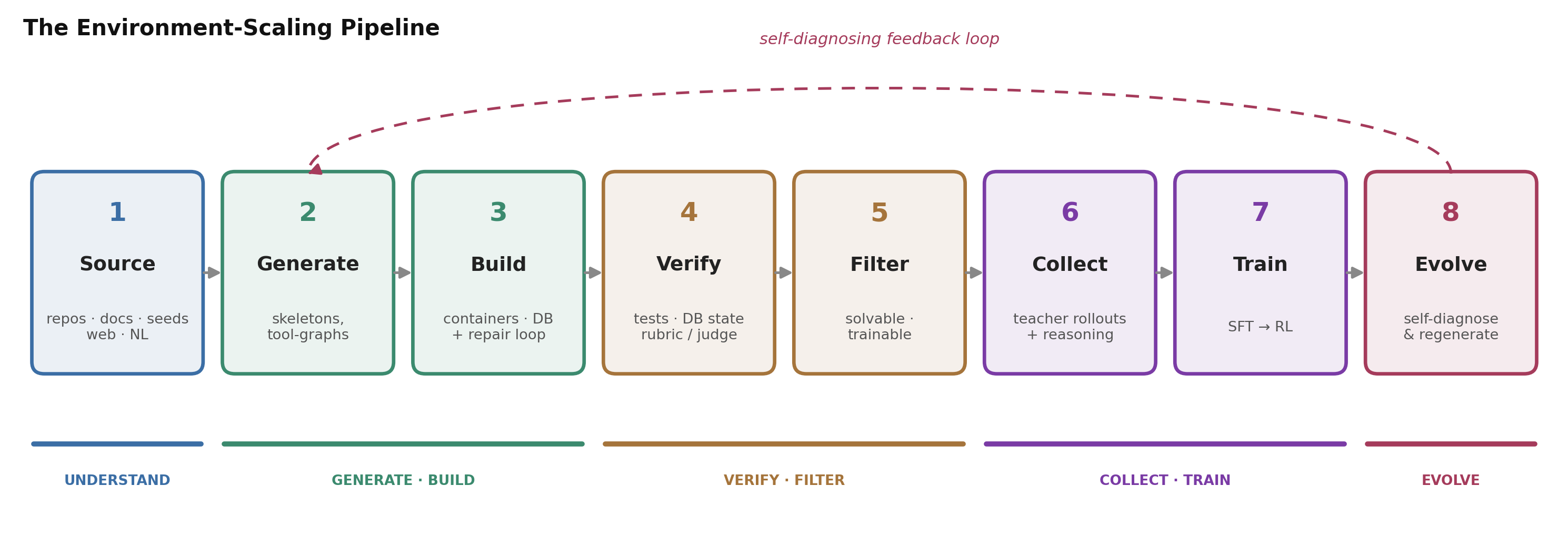 图 2. 反复出现的八步流水线。第 2–5 步是”配方生成器”——研究贡献集中在这里;第 6–7 步把它变成一个训练好的模型;第 8 步闭环。下面逐步走一遍,并在 E1(终端)和 E2(零售退货)上实例化。
图 2. 反复出现的八步流水线。第 2–5 步是”配方生成器”——研究贡献集中在这里;第 6–7 步把它变成一个训练好的模型;第 8 步闭环。下面逐步走一遍,并在 E1(终端)和 E2(零售退货)上实例化。
Step 1 — Source / Understand(来源 / 理解)
一切都始于某个结构来源。文献里的选择其实出奇地少:
- 一份代码仓库语料(SWE-smith, Yang et al., 2025;R2E-Gym, Jain et al., 2025),
- 一批工具文档页面(AutoForge, Cai et al., 2025),
- 用来挖主题的现有任务集(EnvScaler, Song et al., 2026),
- 少量场景种子(scenario seeds)(AgentWorldModel (AWM), Wang et al., 2026),
- 实时 web 资源(Agent-World, Dong et al., 2026;EnvFactory, Xu et al., 2026),
- 甚至只是一条自然语言请求(ClawEnvKit, Li et al., 2026)。
这一步的任务,是把来源转化为一个生成目标:一份要覆盖的技能、领域、工具生态或主题清单。E1: 抽样任务类别(文件操作、权限、服务、日志解析)和难度等级。E2: 识别该领域的意图(退货、换货、改地址)以及读写订单数据库的工具。
权衡。 来源越丰富、越”真实”,任务就越逼真——但你对该来源存在与否的依赖也越大。从抽象种子生成(AWM)最大化规模与独立性;挖真实仓库或 web(SWE-smith、Agent-World)最大化真实性。
Step 2 — Generate(生成环境与任务)
现在合成具体任务。四种模式占主导:
- Skeleton → scenario 分解。 先搭一个环境骨架(它的状态变量、规则、工具),再在上面实例化场景(一个具体初始状态 + 目标)。EnvScaler 的
SkelBuilder/ScenGenerator是最清楚的例子;它从状态出发推导出有挑战性的任务,而不是回放工具序列。 - Tool-graph 随机游走。 把工具看成一张图,只要一个工具的输出能喂给另一个的输入就连一条边,然后做随机游走得到连贯的多步任务。这一配方源自 AgentScaler (Fang et al., 2025),并被 AutoForge 复用(还通过加”reasoning nodes”把任务变难)。
- Environment-first 反转。 不是先写任务再造环境,而是拿一个能用的系统去把它弄坏。SWE-smith 安装一个仓库,然后通过修改代码直到一个原本通过的测试失败,为每个仓库合成成百上千个 bug——这个”坏掉的状态”就是任务。
- Topology-aware 采样。 随机游走的一个改良:在选取某个工具前先解析它的输入依赖,从而产出合法的非线性链(EnvFactory)。
E1: 生成器写出一个任务(”nginx 服务返回 502”)外加特权 ground truth,做法是扰动一个已知良好的容器。E2: 它在数据库里实例化一个订单、选一个退货意图、写出用户目标——τ²-bench 的任务生成器以组合方式做这件事,拼装出可验证的原子子任务。
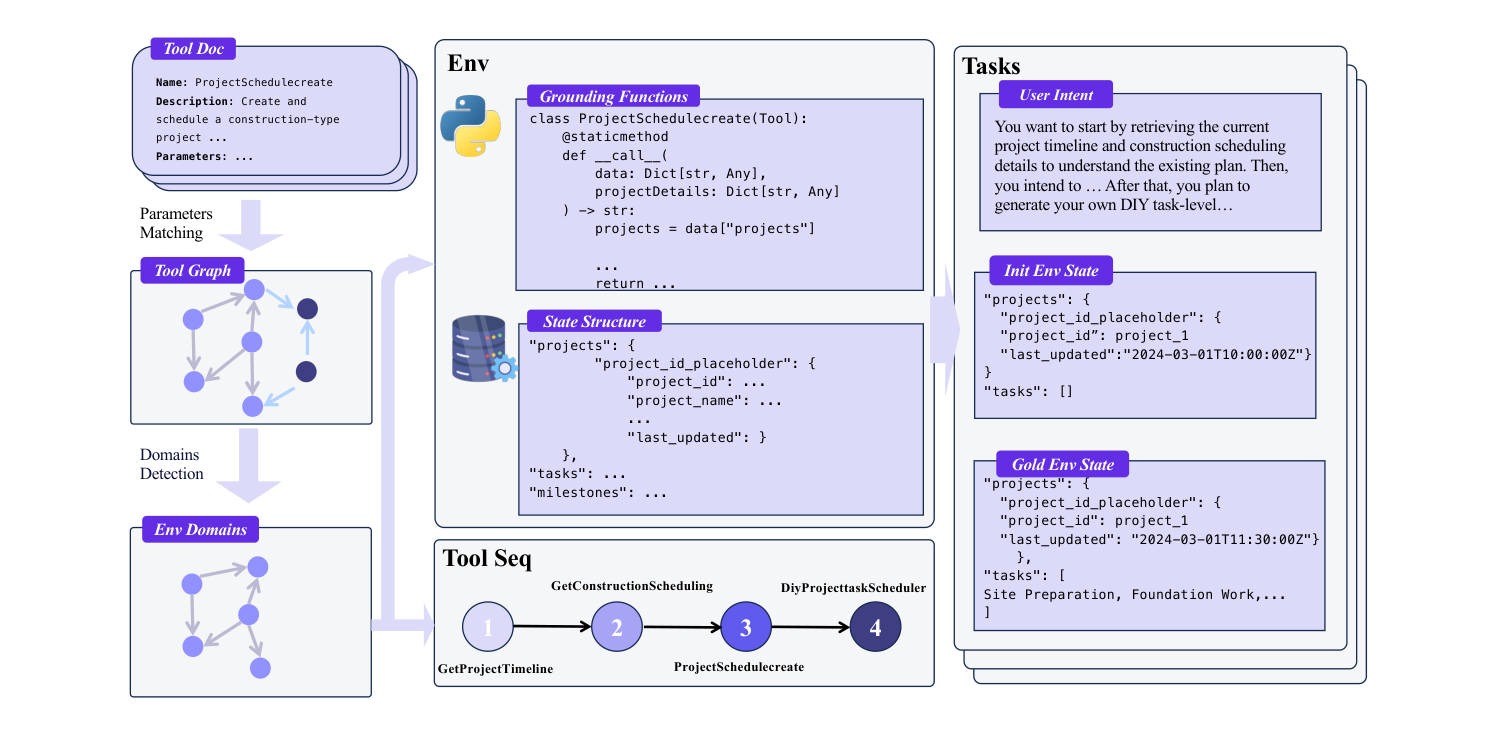 图 3. “tool-graph → database environment” 配方:解析工具文档、构建工具依赖图、划分领域、把每个工具物化为操作数据库的代码,然后在图上游走得到可验证的任务。(图片来源:Fang et al., 2025)
图 3. “tool-graph → database environment” 配方:解析工具文档、构建工具依赖图、划分领域、把每个工具物化为操作数据库的代码,然后在图上游走得到可验证的任务。(图片来源:Fang et al., 2025)
洞见 — “扰动一个能用的系统”。 一些最逼真的任务并非来自”创建一个含这些行的文件”,而是来自:先立起一个健康的系统、注入一个受控的故障、再让智能体去诊断并修复它(Endless Terminals、SWE-smith)。那个原本的健康检查就成了现成的 verifier。
Step 3 — Build(构建并使其可执行)
任务描述在它能跑起来之前毫无用处。这一步产出真正的产物:容器定义(Docker/Apptainer)、数据库 schema + 种子数据、可执行的工具代码、以及一个初始状态检查。通用的诀窍是一个 LLM 带修复循环:生成代码、尝试构建并运行、把任何构建/测试报错喂回给模型、最多重试 \(k\) 次;永远构建不起来的就丢掉。AWM 报告这种自我纠错让 >85% 的环境一次就能构建成功(平均约 1.1 次尝试)。
E1: 组装那个含坏掉服务的容器,并附一个先决测试,确认它在起点确实是坏的。E2: 生成 SQL schema 和合成数据行,使该订单真实存在、任务可解。
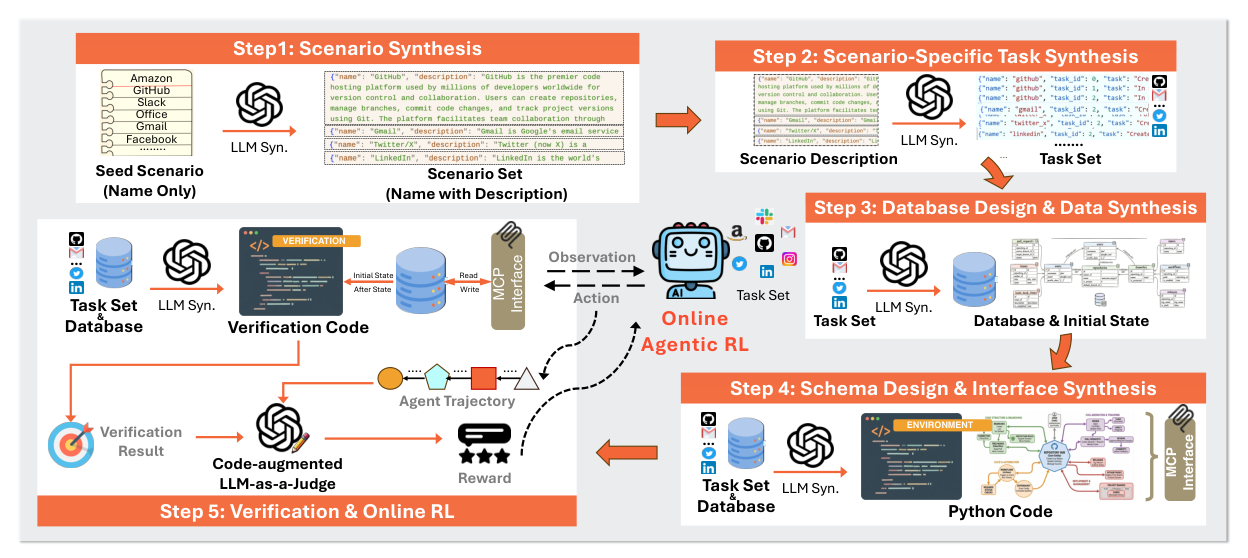 图 4. 一个有代表性的构建流水线:scenario → task → database design → schema/interface 合成 → verification,每一阶段都由 LLM 生成,并配有基于执行的自我纠错。(图片来源:Wang et al., 2026)
图 4. 一个有代表性的构建流水线:scenario → task → database design → schema/interface 合成 → verification,每一阶段都由 LLM 生成,并配有基于执行的自我纠错。(图片来源:Wang et al., 2026)
Step 4 — Verify(验证)
Verifier 是”可训练”成败之处,它的形态也是各领域之间最大的差别(我们会在 环境类型全景图 里梳理)。主要的几类:
- 文件系统 / 执行测试 — 针对文件、进程、输出的
pytest式断言(终端、SWE)。E1 属于这一类。 - 数据库末态比对 — 把后端存储与预期末态做 diff。便宜且确定;工具使用的主力(AgentScaler、AWM)。E2 属于这一类。
- Hybrid(执行式 + 免执行)verifier — 把跑测试与一个读取轨迹的学习型模型结合起来;对 test-time 选择很有用(R2E-Gym)。
- Rubric / LLM-as-judge — 用于抗拒确定性检查的目标(例如 E2 的沟通部分),并设门控:必须先通过一个结构性检查,才给任何 rubric 分。
洞见 — generator–verifier 不对称。 容易验证的领域往往难以生成好任务,反之亦然。一个干净的数据库末态极易检查,但任务必须被精心构造才能有这样的末态;而一个开放式的”解释这个 bug”任务极易提出,却很难打分。留意一个系统是在这笔交易的哪一侧付代价。
Step 5 — Filter(筛选)
生成是有噪声的——大多数候选要么坏掉、要么平凡、要么对学习无用——所以筛选是把一堆原始生成任务变成可用训练池的地方。四个筛子反复出现,大致按此顺序:
- Solvable(可解) — 一个强模型能取得非零成功率。Endless Terminals 从一个前沿模型采样 n = 16 个解,只保留 pass@16 > 0 的任务,仅这一步就砍掉大约一半通过了构建阶段的任务。SWE-smith 用另一种方式做同样的切割:一个合成 bug 只有在其 patch 真的让至少一个原本通过的测试失败(即一个 Fail-to-Pass 实例)时才保留,并加一个短的运行时上限,把病态任务丢掉。
- Non-trivial(非平凡) — 不是所有模型都能一次答对;人人一招制胜的任务没有信号。
- Non-contaminated(无污染) — 不是评测 benchmark 的近似重复(多数系统只做粗糙处理;见 开放挑战)。
- Trainable(可训练) — 任务对当前策略能产生可用梯度。这是最微妙的筛子,单独成节,难度 ≠ 可训练性。
还有一个更早发生(Step 3)的 build/validity 门,但属于同一个”损耗”故事:构建不起来的容器、跑不起来的 verifier、初始状态检查失败的任务,都被扔掉。AgentWorldModel 的修复循环让 >85% 的环境一次构建成功(平均约 1.1 次尝试);R2E-Gym 预先筛到小范围的 bug-fix commit(≤5 个非测试文件、≤100 行),让下游环境根本可复现。
洞见 — 筛选是一笔隐藏的效率税。 这条流水线本质上是生成即丢弃:你花钱让一个前沿模型提议任务、构建容器、采样 rollout——然后把其中大部分丢掉(构建失败 → 不可解 → 平凡 → 不可训练)。Endless Terminals 那约 50% 的 solvability 切割很典型,而且会与更早的构建损耗叠加,于是每个生成候选最终有效产出的可用训练任务可能很低。这是一个反对盲目过度生成、支持把生成导向更可能通过筛选的任务的隐性论据——这条线,领域才刚开始拉。
E1/E2: 丢掉 teacher 解了 0/16(现在太难)或 16/16(已经掌握)的任务,保留居中的那些。
Step 6 — Collect(收集轨迹)
现在在存活下来的环境上跑一个强 teacher,每个任务采样多次解答尝试,保留成功的那些(rejection sampling),辅以轻度去重,并对每个任务设一个”几条轨迹”的上限,免得简单、过度出现的任务主导数据。几个系统都做的漂亮一招,是把这一套轨迹当作双用途(dual-use):既作 SFT 数据(Step 7),又作 RL 的 bootstrapping 信号——EnvFactory 和 AutoForge 都在一次合成里同时做这两件事。
关于 teacher 的两个选择,比初看起来更要紧:
- 能力是天花板。 学生最多只能被蒸馏到 teacher 真正能解的程度;在真正难的任务上,弱 teacher 干脆产不出任何可学的成功轨迹。这就是为什么这些流水线倾向用前沿模型(o3、GPT-5、Claude、强开源 MoE)当 solver。
- reasoning trace 的可得性。 你通常想蒸馏 teacher 的过程,而不只是最终动作——R2E-Gym 发现把显式思维链保留在轨迹里有实质帮助(去掉 trace 时 SWE-bench Verified 上约 34.4% vs 30.4%)。但闭源与开源 teacher 在这点上差别很大:许多闭源前沿 API 不暴露其隐藏的 thinking token(你拿到答案和工具调用,拿不到 chain-of-thought),而一些开源的 “thinking” 模型会吐出可捕获、可训练的显式 reasoning。所以 teacher 的选择是一笔真实的权衡——原始能力 vs. 能否拿到 reasoning trace——值得刻意选择,而不是默认用最强的闭源 API。
无论用哪个 teacher,轨迹都会被序列化成 scaffold 的精确动作格式,使同一份数据对 SFT 和 RL 都一致。
E1/E2: teacher 成功的终端修复(连同它关于 nginx 为什么 502 的推理)和零售退货对话,构成轨迹池。
Step 7 — Train(训练)
训练是把一堆轨迹和环境变成一个模型的地方。近乎通用的配方是 SFT warm-start,然后 RL——但有意思的问题是SFT 做多少、何时切换、以及为什么要 warm-start。
- SFT 是干什么的(以及不是干什么的)。 warm-start 的职责很窄:让小模型可靠地(a)输出 scaffold 的动作/观测格式,并(b)获得足够的基础能力,能产出一些成功 rollout。它是一个就绪门槛,而非精度目标——SFT 到格式达标且 rollout 成功率非零,就停。SFT 过头往往会固化策略、压垮 RL 所需的探索;SFT 不足(尤其对最小 scaffold 下的小模型)会让策略停在地板上、没有 reward variance,于是 RL 无从发力。
- 然后 RL。 从 SFT 检查点出发,用一个稀疏的、由 verifier 定义的 episode 奖励(无中间 shaping)来跑 RL。具体的优化器各不相同——PPO、GRPO、以及环境级的变体都在用——但算法在这里很少是贡献所在;奖励保持二值/稀疏,真正的工程功夫花在降方差、以及别让一个抖动的被模拟用户或一个坏环境主导更新(例如屏蔽那些因被模拟用户行为不当而失败的 episode)。表 1 列了各系统分别用什么训练,这里就不啰嗦了。
- 为什么 warm-start 对 transfer 重要。 Endless Terminals 给出了最尖锐的版本:当基座模型先被 SFT 进 scaffold 后,在合成终端任务上跑 RL 向人工 benchmark 的迁移会好得多;冷启动的 RL 几乎挪不动一个小模型。
E1/E2: 把小模型 SFT 到能稳定产出格式良好的 shell 会话 / 工具调用对话、确认它解出非零比例,再切到在同一批容器和数据库上跑 RL。
Step 8 — Evolve(可选:演化)
一次性的流水线会把信号留在桌上。经过一轮训练后,你比生成时知道得多得多:智能体还在哪些技能上失败、哪些任务给出了干净的学习信号、哪些是在浪费算力。演化这一步把这种事后认识变成下一批环境——让 pipeline(图 2)成为一个真正的回路而非一条直线。这是这个领域最年轻、最活跃的部分,所以值得拆开看看”把信号喂回去”到底是什么意思。
有三类诊断信号,按提取难度递增:
- Inference 级信号 — 智能体在哪儿失败了。 按技能聚类的失败、以及失败模式(在同一命令上打转、耗尽回合预算、过早终止)。这类信号便宜且稳健,驱动覆盖修复(为服务不足的技能多生成)和针对失败的生成。
- Training 级信号 — 某个任务族是否教会了什么。 全零或全一奖励任务的比例、每任务的 reward/advantage 方差、entropy 与 KL 轨迹。一个产不出 reward variance 的族就产不出梯度(这正是 难度 ≠ 可训练性 那一点,在这里被当作控制旋钮),应当被调简单、分解成子目标、或丢弃。
- Transfer 级信号 — 合成版本是否太容易。 合成开发任务上的表现与 held-out benchmark 之间的差距,会标记出哪些技能的合成版本是被简化的漫画。
两个系统把这一点做实了。Agent-World 跑一个显式的自演化竞技场(arena):每轮 RL 后重新采样一组 held-out 任务,一个自动诊断智能体给最弱的环境排序并给出生成指引,针对性任务被合成出来、训练继续——在连续几轮里获得单调收益(甚至能帮到一个不同的基座模型)。GenEnv 更进一步,把环境生成器本身做成一个会学习的玩家:智能体与一个 LLM 环境模拟器作为一个两人课程博弈共同演化,模拟器因产出智能体大约解一半的任务而获奖励(关于这个 50% 的甜点,详见 难度 ≠ 可训练性)。整个领域的弧线很清楚——从一次性合成 → 诊断并再生成 → 完整的 agent–环境协同演化——尽管最后一步目前多半还是愿景。
要点。 扩展环境就是 Generate → Build → Verify → Filter → Collect → Train →(Evolve)。第 2–5 步是研究贡献集中的地方;第 6–7 步日益标准化(但 teacher 选择与 SFT→RL 的交接仍值得用心);第 8 步——用训练信号闭环——是开放前沿。
为了把配方落地,下面用同样的八步视角横扫主要系统——它们从什么出发、怎么验证、怎么训练:
| 系统 | 领域 | 来源(step 1) | Verifier(step 4) | 训练(step 6–7) |
|---|---|---|---|---|
| Endless Terminals | terminal | category sampling | filesystem + pytest | SFT(opt) → PPO |
| SWE-smith | SWE | repos (env-first) | Fail→Pass tests | SFT (rejection) |
| R2E-Gym | SWE | commits + backtranslation | tests + hybrid verifier | SFT |
| AgentScaler | function-calling | >30K APIs → DB | DB end-state + tool-seq | SFT only |
| EnvScaler | tool-use | task sets (theme mining) | rule-based state checks | SFT → Reinforce++ |
| AutoForge | tool-use | tool docs | final-state equality | SFT → ERPO (GRPO++) |
| AgentWorldModel | tool-use | scenario seeds | DB-diff + code-aug. judge | GRPO |
| EnvFactory | tool-use (MCP) | authentic web resources | unit tests + traj/state | SFT → GRPO |
| GenEnv | classic agent | learned env-simulator | exact/soft match | RWR + GRPO |
| Agent-World | tool-use (real DB) | web mining | executable + rubric | GRPO + self-evolve |
表 1. 以流水线为对比透镜。注意各列几乎彼此独立——一个系统的来源、verifier、训练器在很大程度上是可分离的选择,这正是下一节把它们读作轴(axes)的原因。
(Benchmark——τ²-bench、ARE/Gaia2——在此刻意略去;它们是评测目标,而非生成器。我们会在 *环境类型全景图 里回到它们。)*
设计选择的分类
表 1 暗示了一件有用的事:一个系统的来源、verifier、训练器在很大程度上是相互独立的选择。这正是不用死记十五个系统也能读懂整个领域的钥匙。几乎每个设计决策都落在三大轴族之一上,它们与组织环境扩展综述的 Generation → Execution → Feedback (GEF) 循环 相对应(Huang et al., 2025)。
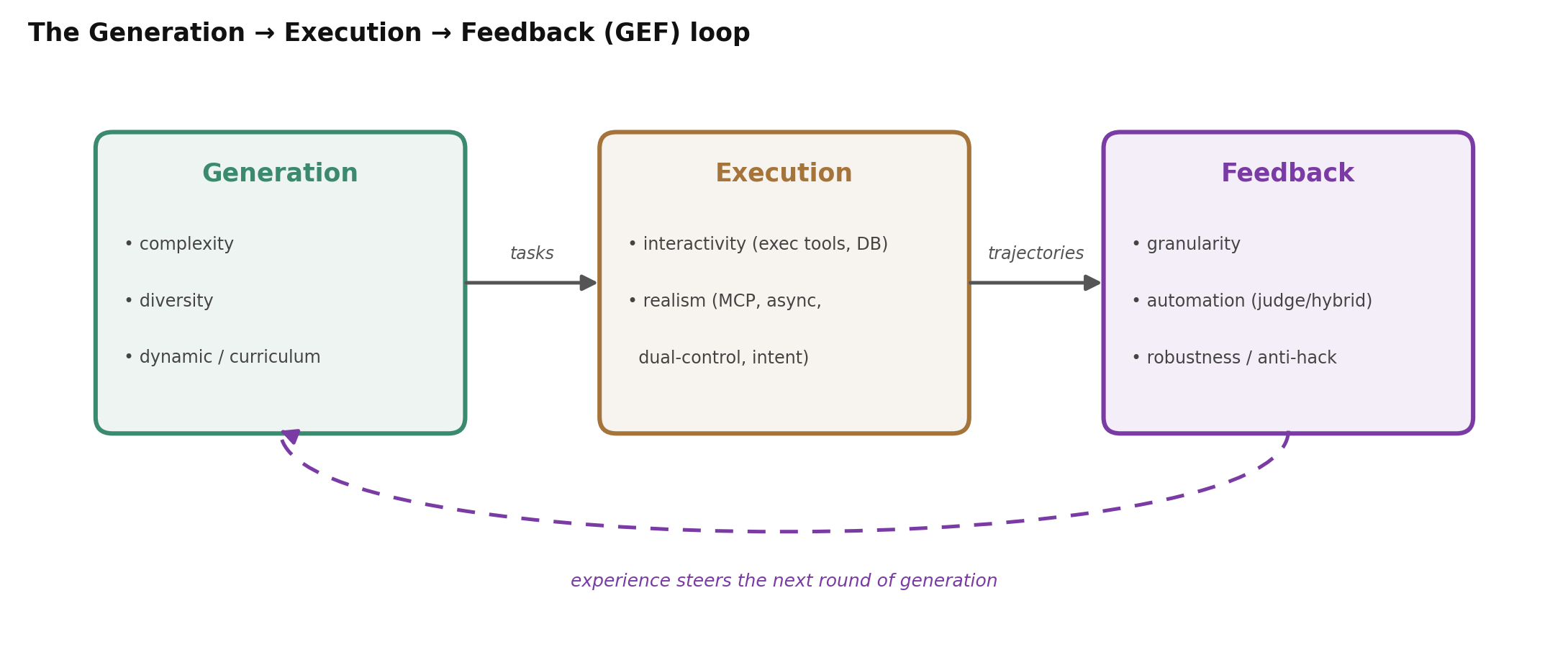 图 5. 把各方法读作三条轴上的位置:任务如何被生成、如何被执行、其结果如何变成反馈。
图 5. 把各方法读作三条轴上的位置:任务如何被生成、如何被执行、其结果如何变成反馈。
生成
- Complexity scaling(复杂度扩展) — 让单个任务在结构上更难。AutoForge 通过给它的工具依赖 DAG 加 reasoning nodes 来抬高难度;τ²-bench 用组合的原子子任务数量来控制难度。
- Diversity scaling(多样性扩展) — 覆盖更多环境/领域。AgentScaler 把 30K+ 个 API 划分成 1,000+ 个领域;AgentWorldModel 合成 1,000 个 SQL 支撑的环境;Agent-World 从 web 挖出上千个主题。
- Dynamic scaling(动态扩展) — 让难度适配当前智能体。GenEnv 的课程瞄准约 50% 的成功带;Agent-World 的 arena 围绕智能体的弱点再生成任务。
洞见 — 更多样 ≠ 更好。 AgentWorldModel 和 Agent-World 都报告了边际递减:环境数量在初期帮助陡增、随后趋平(Agent-World 的 4 域平均从 0→几百个环境大约翻倍,然后进入平台期)。过了某个点,加哪些任务比加多少更重要——这个伏笔我们会在 难度 ≠ 可训练性 里兑现。
| 生成子轴 | 它扩展什么 | 代表性做法 |
|---|---|---|
| Complexity | 单任务难度 | reasoning-node DAG(AutoForge);组合子任务(τ²-bench) |
| Diversity | 环境/领域的广度 | API→领域划分(AgentScaler);1,000 个 SQL 环境(AWM);web 主题(Agent-World) |
| Dynamic | 相对智能体的难度 | ~50% 成功率课程(GenEnv);自演化 arena(Agent-World) |
表 2. 生成轴。
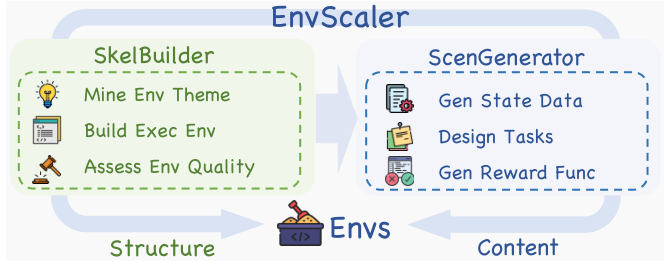 图 6. 程序化生成的一个具体例子:SkelBuilder 挖一个主题并构建一个可执行的环境骨架(结构),然后 ScenGenerator 从其状态推导出任务和奖励函数(内容)。(图片来源:Song et al., 2026)
图 6. 程序化生成的一个具体例子:SkelBuilder 挖一个主题并构建一个可执行的环境骨架(结构),然后 ScenGenerator 从其状态推导出任务和奖励函数(内容)。(图片来源:Song et al., 2026)
执行
- Interactivity(交互性) — 给智能体真正可执行的工具,而不是一个会幻觉的模拟器。几乎所有人都收敛到的实用诀窍是把数据库当作环境:把每个工具建模为对一个后端存储的读/写,从而让状态转移一致且便宜(AgentScaler、AgentWorldModel)。
- Realism(真实性) — 缩小到部署的差距。这是最新工作发力的地方:通过 MCP 暴露带类型的工具;异步、事件驱动的世界,时间在智能体思考时照样流逝(ARE/Gaia2, Froger et al., 2025);会对世界采取动作的 dual-control 用户(τ²-bench);以及用含蓄、模糊的意图取代逐步指令(EnvFactory)。
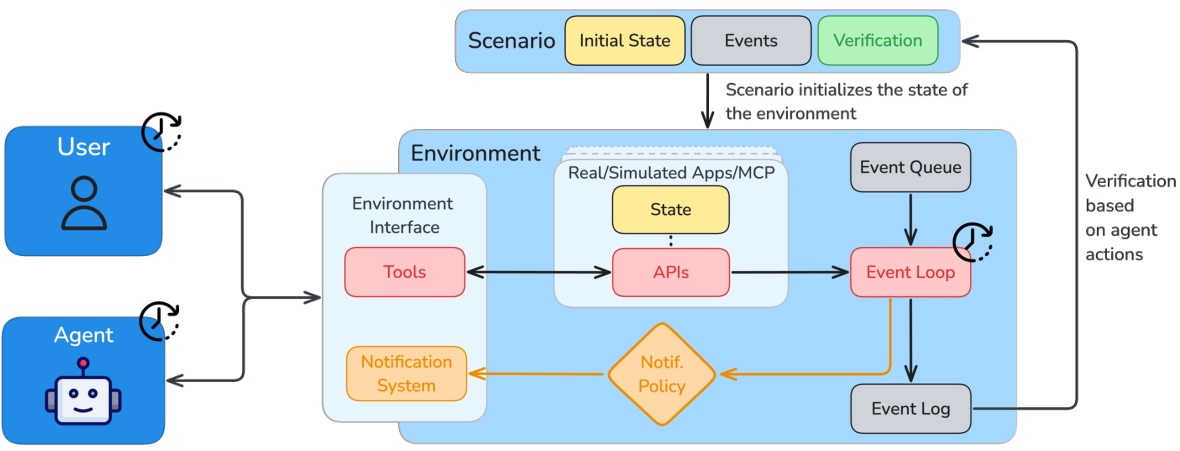 图 7. 执行轴上高真实性的一端:ARE 把世界建模为一个异步、时间驱动的事件循环——环境会在智能体思考时持续推进,不同于多数系统假设的同步、回合制世界。(图片来源:Froger et al., 2025)
图 7. 执行轴上高真实性的一端:ARE 把世界建模为一个异步、时间驱动的事件循环——环境会在智能体思考时持续推进,不同于多数系统假设的同步、回合制世界。(图片来源:Froger et al., 2025)
洞见 — 真实性不等于难度。 一个反复出现的综述观察:简单环境里的复杂任务往往不如复杂环境里的简单任务教得多。把任务拉长很容易;让世界表现得像真实世界(异步、噪声、一个会改主意的用户)才是真正暴露智能体弱点的东西。
反馈
- Granularity(粒度) — 二值成功 → 数值/部分得分 → rubric 打分。末态相等给出干净的 0/1(AutoForge);一份状态校验函数清单给出一个比例(EnvScaler);一个 rubric judge 处理模糊目标(ClawEnvKit)。
- Automation(自动化) — verifier 怎么搭:朴素的 LLM-as-judge、一个先跑检查再打分的代码增强(code-augmented) judge(AgentWorldModel)、或用于 test-time 选择的执行式与免执行 verifier 的 hybrid(R2E-Gym)。
- Robustness(鲁棒性) — 让奖励保持诚实。ARE 不得不给自己的 verifier 打补丁来抵御 RL 奖励 hacking;R2E-Gym 发现免执行 verifier 会盯着智能体的推理风格而非 patch;AutoForge 会屏蔽那些因被模拟用户行为不当而失败的 episode。
洞见 — generator–verifier 不对称。 这是这个领域最深的张力。易验证的领域(一个数据库末态)难以生成好任务;而任务易提出的领域(”解释这次故障”)难以验证。每个系统都在这笔交易的某一侧付代价,而前沿想法是让 generator 与 verifier 协同演化,而不是固定一个、指望另一个跟得上。
| 反馈维度 | 谱系 | 代表性做法 |
|---|---|---|
| Granularity | 二值 → 数值 → rubric | 末态 0/1(AutoForge);清单比例(EnvScaler);rubric(ClawEnvKit) |
| Automation | LLM-judge → code-augmented → hybrid | 代码增强 judge(AWM);执行式+免执行 hybrid(R2E-Gym) |
| Robustness | 抗 hacking、抗噪 | verifier 打补丁(ARE);屏蔽被模拟用户错误(AutoForge) |
表 3. 反馈 / verifier 轴。
要点。 在三条轴上各选一个点,你本质上就指定了一个环境扩展系统。多数”新”系统都是新的组合,外加在某一条轴上的一个尖锐想法。
环境类型全景图
从方法退一步,看它们实际产出的环境,菜单其实很短。尽管流水线千差万别,被合成的环境大致落在约五类里,而真正区分它们的,是 verifier 的形态。
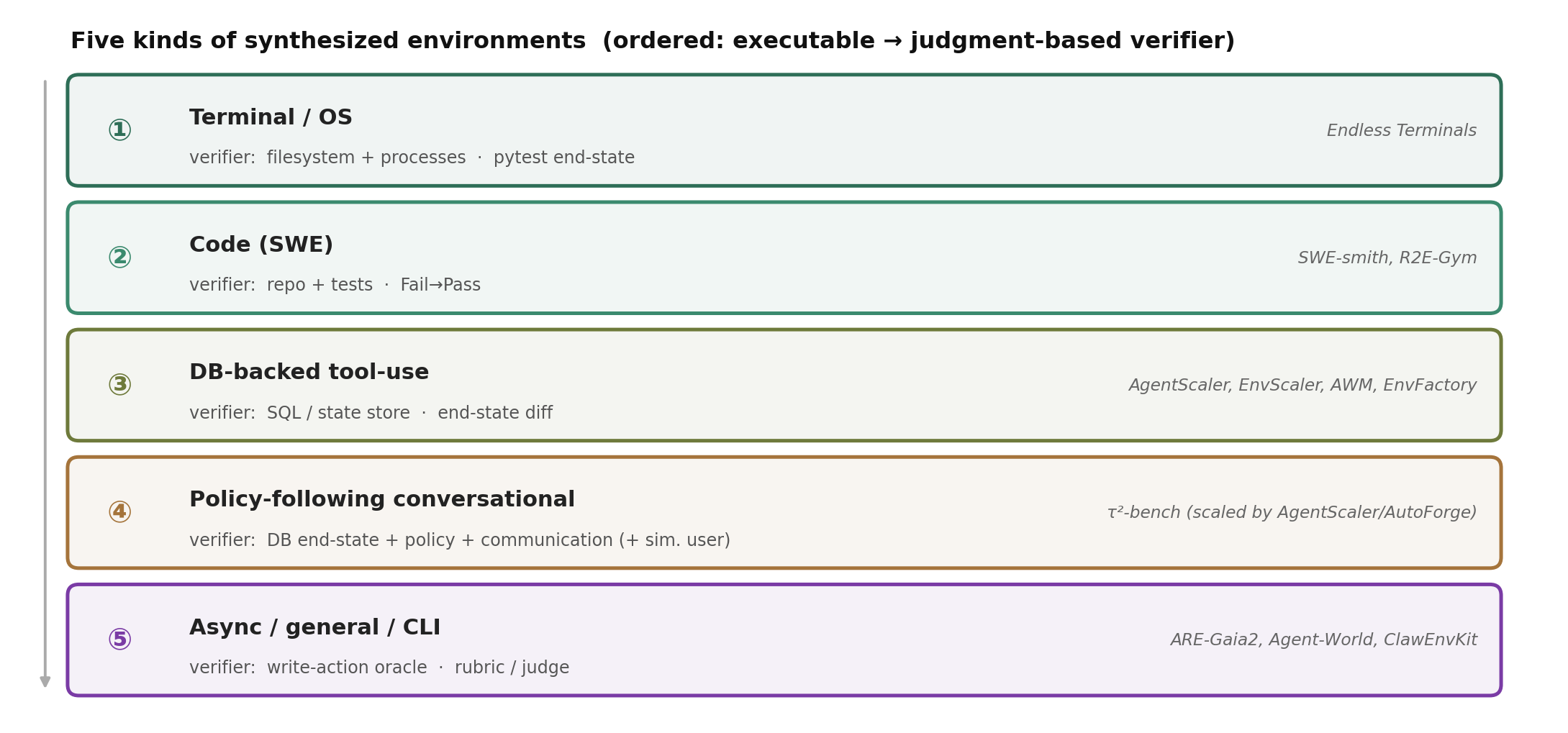 图 8. 反复出现的五类环境。各领域之间的差别,更多在于成功如何被检查,而不在于任务如何被生成。
图 8. 反复出现的五类环境。各领域之间的差别,更多在于成功如何被检查,而不在于任务如何被生成。
| 类型 | 状态后端 & verifier | 代表系统 |
|---|---|---|
| ① Terminal / OS | 文件系统 + 进程;pytest 式末态 | Endless Terminals |
| ② Code(SWE) | 仓库 + 测试;Fail→Pass | SWE-smith、R2E-Gym |
| ③ DB-backed tool-use | SQL/状态存储;末态 diff | AgentScaler、EnvScaler、AWM、EnvFactory |
| ④ 遵循政策的对话式 | 数据库末态 + 政策 + 沟通(+ 被模拟用户) | τ²-bench(+ AgentScaler/AutoForge 作为扩展器) |
| ⑤ Async / general / CLI | write-action oracle / rubric | ARE/Gaia2、Agent-World、ClawEnvKit |
其中两类值得单独拎出来,因为它们研究得最多,而且各自都有一套成熟的评测 benchmark,是合成工作在暗中追逐的目标。
代码智能体与工具调用
代码智能体(SWE)设定是 “environment-first” 思路最干净的例子。你不是先写一个编码任务再造沙盒;而是拿一个真实仓库、让它可执行、并让它的测试来定义成功。SWE-smith 安装一个仓库,然后通过修改代码直到一个原本通过的测试失败,为每个仓库合成成百上千个 bug——那个坏掉的状态就是任务,那个测试就是verifier。R2E-Gym 则挖真实的 bug-fix commit 并回译(backtranslate)出问题描述,把 Fail→Pass 测试注入到 prompt 里,使合成的 issue 精确。
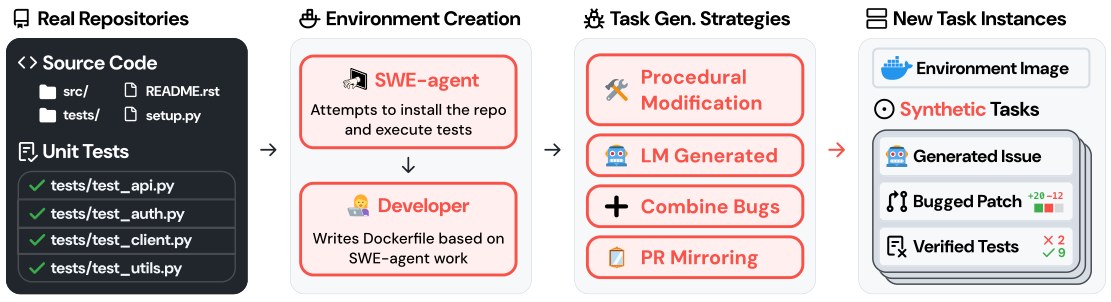 图 9. Environment-first 思路:从一个真实仓库及其通过的测试出发、造一个可执行环境,然后合成许多 bug 任务(程序化改写、LM 重写、PR 镜像),其 verifier 就是”测试现在失败了”。(图片来源:Yang et al., 2025)
图 9. Environment-first 思路:从一个真实仓库及其通过的测试出发、造一个可执行环境,然后合成许多 bug 任务(程序化改写、LM 重写、PR 镜像),其 verifier 就是”测试现在失败了”。(图片来源:Yang et al., 2025)
这个领域如此高产的原因,是验证基本免费且可信:跑测试就行。它被衡量所对标的现有 benchmark——SWE-bench / SWE-bench Verified,以及面向训练的 SWE-Gym——正是这些合成器想要迁移过去的 eval-only 目标。(R2E-Gym 的执行式 + 免执行 hybrid verifier 甚至兼作一个 test-time 选择器,把开源权重 SWE 智能体在 SWE-bench Verified 上推过了 50%。)
遵循政策的智能体
第二个簇是在一份成文政策(policy)下的对话式工具使用——我们称之为遵循政策(policy-following)(亦即constitution-constrained)的智能体。典型场景是客服:智能体拿到一本规则手册(”这是退货政策”)、一组操作客户数据库的带类型工具、以及一个被模拟用户,必须在不违反政策的前提下满足用户请求,并把数据库带到正确末态。τ²-bench (Barres et al., 2025) 是参照 benchmark,并加入了 dual-control(用户也能对世界采取动作)。
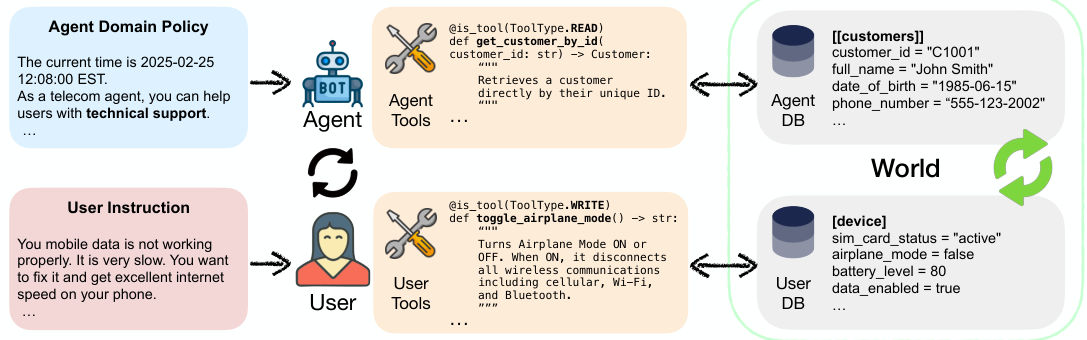 图 10. 一个遵循政策(”constitution”)的智能体:它读一份成文领域政策、调用操作数据库的带类型工具来服务用户,并且——在 dual-control 设定里——智能体与(被模拟的)用户都能对一个共享世界状态采取动作。(图片来源:Barres et al., 2025)
图 10. 一个遵循政策(”constitution”)的智能体:它读一份成文领域政策、调用操作数据库的带类型工具来服务用户,并且——在 dual-control 设定里——智能体与(被模拟的)用户都能对一个共享世界状态采取动作。(图片来源:Barres et al., 2025)
让这一类与众不同的,是一个乘性(multiplicative)verifier:成功要求同时满足(i)正确的写动作、(ii)向用户传达了正确信息、(iii)正确的数据库末态——而其中沟通部分抗拒确定性检查,于是 rubric/judge 验证又溜了回来。针对这一族的环境扩展器(AgentScaler、AutoForge、EnvScaler、EnvFactory)本质上是在大规模制造更多 τ-bench-/ACEBench-/BFCL 风格的任务,并因此继承了它最难的问题:一个抖动的被模拟用户能把一个本来正确的 episode 拖垮(于是有了 AutoForge 的 user-error 屏蔽,详见 设计选择的分类)。
另外三类,简述
① Terminal/OS(Endless Terminals)用 pytest 式断言对文件系统与进程状态验证——是代码之外最接近”ground truth”的东西。③ DB-backed tool-use(AgentScaler、AWM、EnvScaler、EnvFactory)是宽阔的中间地带:一个 SQL/状态存储的 diff 就是 verifier,这也是它最拥挤、最可扩展的原因。⑤ Async / general 平台(ARE/Gaia2、Agent-World、ClawEnvKit)在真实性与复用性上发力,用一组 oracle 的写动作(带时序/因果)或声明式检查函数来验证。
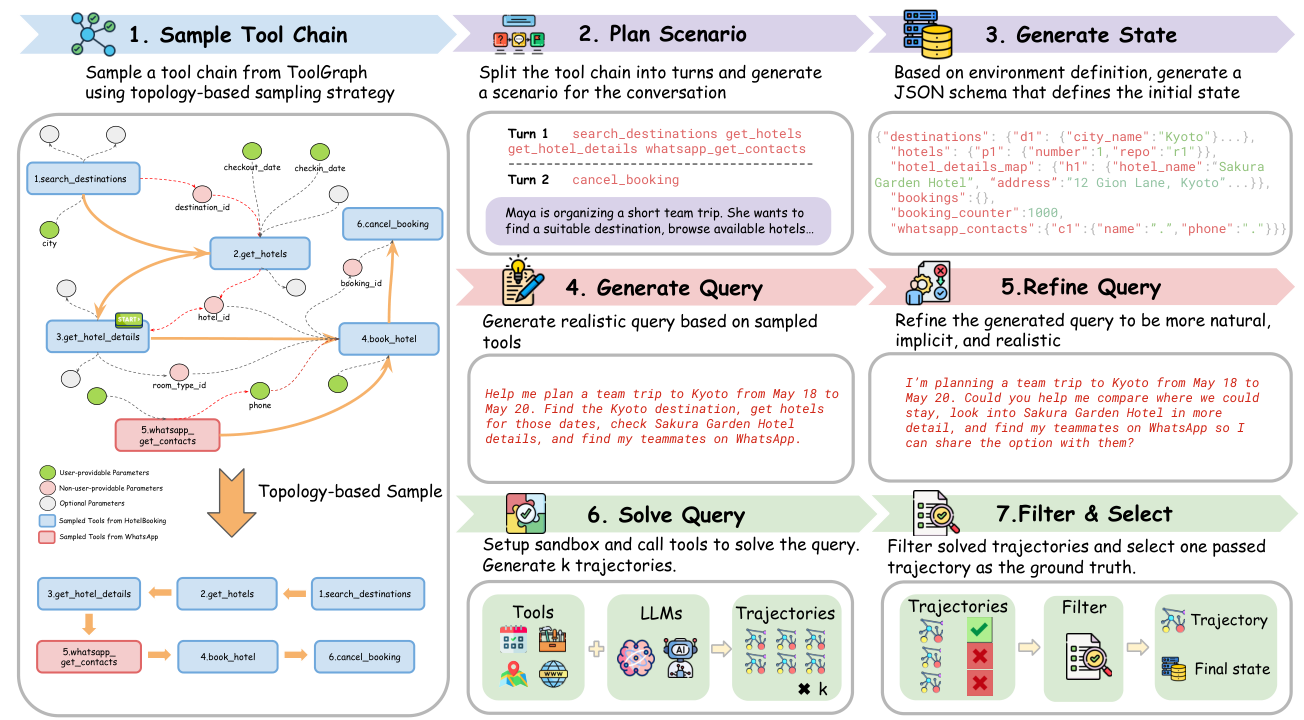 图 11. 在 DB-backed tool-use 这一族里,近期工作在数据真实性上发力:EnvFactory 通过解析依赖来采样工具链(topology-aware),再把生成的 query 精修成含蓄、模糊、像真实人类请求的样子,而不是逐步指令。(图片来源:Xu et al., 2026)
图 11. 在 DB-backed tool-use 这一族里,近期工作在数据真实性上发力:EnvFactory 通过解析依赖来采样工具链(topology-aware),再把生成的 query 精修成含蓄、模糊、像真实人类请求的样子,而不是逐步指令。(图片来源:Xu et al., 2026)
关于谱系的说明。 有两项工作充当了其余工作所依赖的枢纽:τ²-bench(对话族的设计模板 + 评测目标)和 AgentScaler(2026 年的 tool-use 系统都由其衍生的 “tool-graph → database environment” 配方)。如果在读其余之前只读两篇背景论文,就读这两篇。
要点。 环境类型其实只有一小撮;一旦你知道 verifier 的形态(文件系统、测试、数据库末态、政策+沟通、或 write-action oracle),你就大体知道了是什么让那个领域好扩展或难扩展。
难度 ≠ 可训练性
这是整个领域里最有用、也最常被弄错的一个想法。当你筛选生成的任务时(流水线的 Filter 步),最显然的旋钮是难度:把平凡的扔掉、留下难的。这是个错误。真正支配学习的量不是难度,而是可训练性(trainability)——一个任务能否对当前策略产生可用的梯度。
直觉只需一行代数。对一个在当前策略下成功概率为 \(\hat{p}\) 的任务,一次基于结果奖励的 RL 更新,其信号来自奖励的方差;对二值结果而言,方差是 \(\hat{p}(1-\hat{p})\)——在 \(\hat{p}=0.5\) 处最大、在两端都为零。一个策略总是失败(\(\hat{p}=0\))的任务和一个它总是解出(\(\hat{p}=1\))的任务都毫无贡献:像 GRPO 这样的 group-relative 方法在各次 rollout 上看到相同的奖励,于是 advantage——以及梯度——恰好为零。
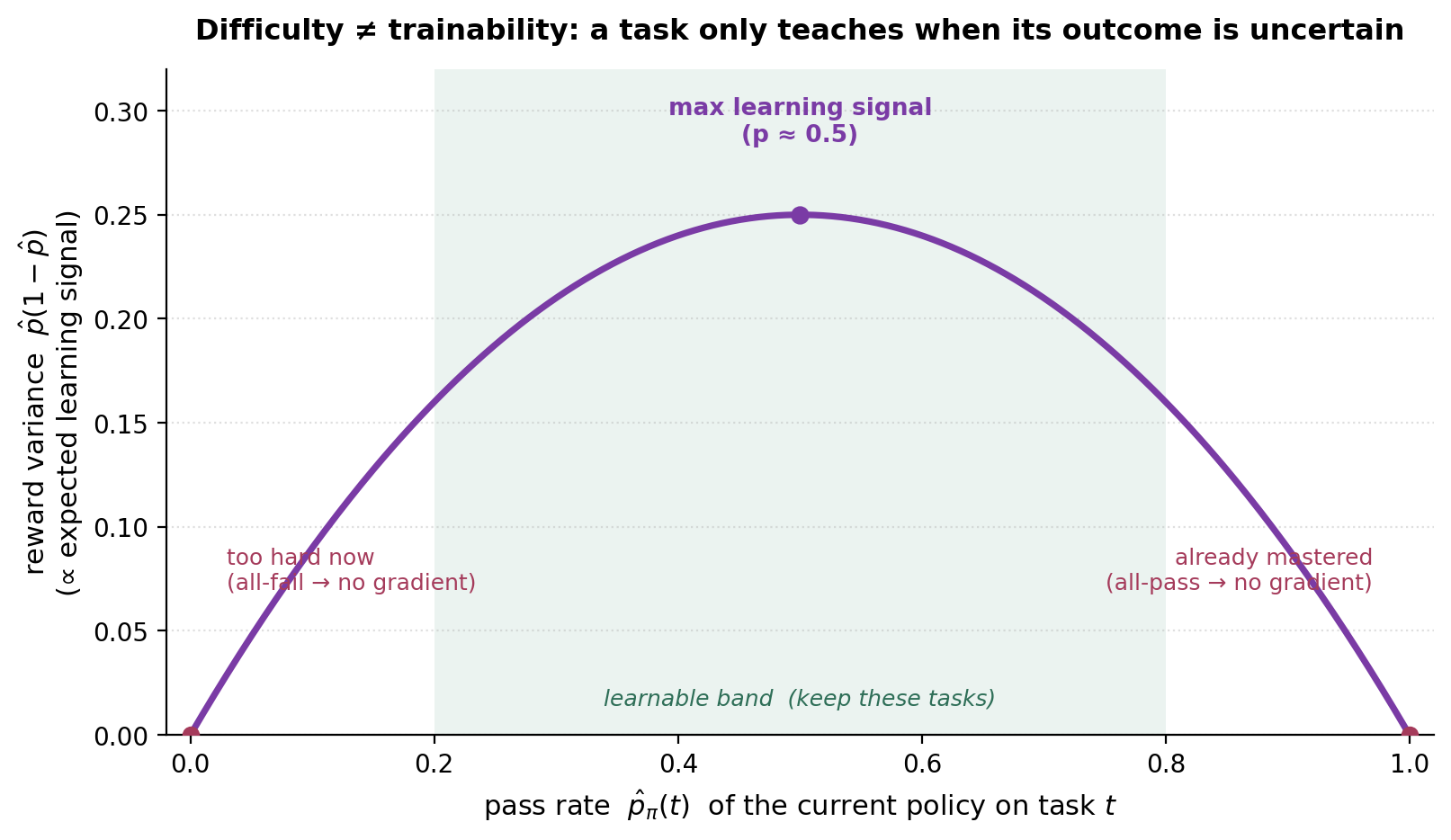 图 12. 任务只有在结果不确定时才教得动。难度是 x 轴;学习信号是这条曲线。
图 12. 任务只有在结果不确定时才教得动。难度是 x 轴;学习信号是这条曲线。
这重新定义了筛选。正确的规则不是”留下难的任务”,而是留下落在可学习带(learnable band)里的任务 \(p_{\text{low}} \le \hat{p}_\pi(t) \le p_{\text{high}}\)——而且因为这个带是相对当前策略 \(\pi\) 定义的,它必须随策略改进而重新评估。集合中有两项结果把这点做实了:
- GenEnv 把这个带变成给一个环境生成器的奖励:它用 \(R_{\text{env}}(\hat p)=\exp(-\beta(\hat p-\alpha)^2)\) 奖励生成器,在目标成功率 \(\alpha\approx0.5\) 处取峰值,甚至证明了期望梯度范数平方 \(\propto \hat p(1-\hat p)\)。于是智能体的成功率会朝那个带自组织——一个涌现的课程,非常符合学习理论里的 zone of proximal development(最近发展区) 思想。
- SWE-smith 给出了说明同一点的反面结果:一个任务的难度评级能预测它可解与否,却预测不了它对下游训练有多大帮助——难度和训练价值就是两条不同的轴。
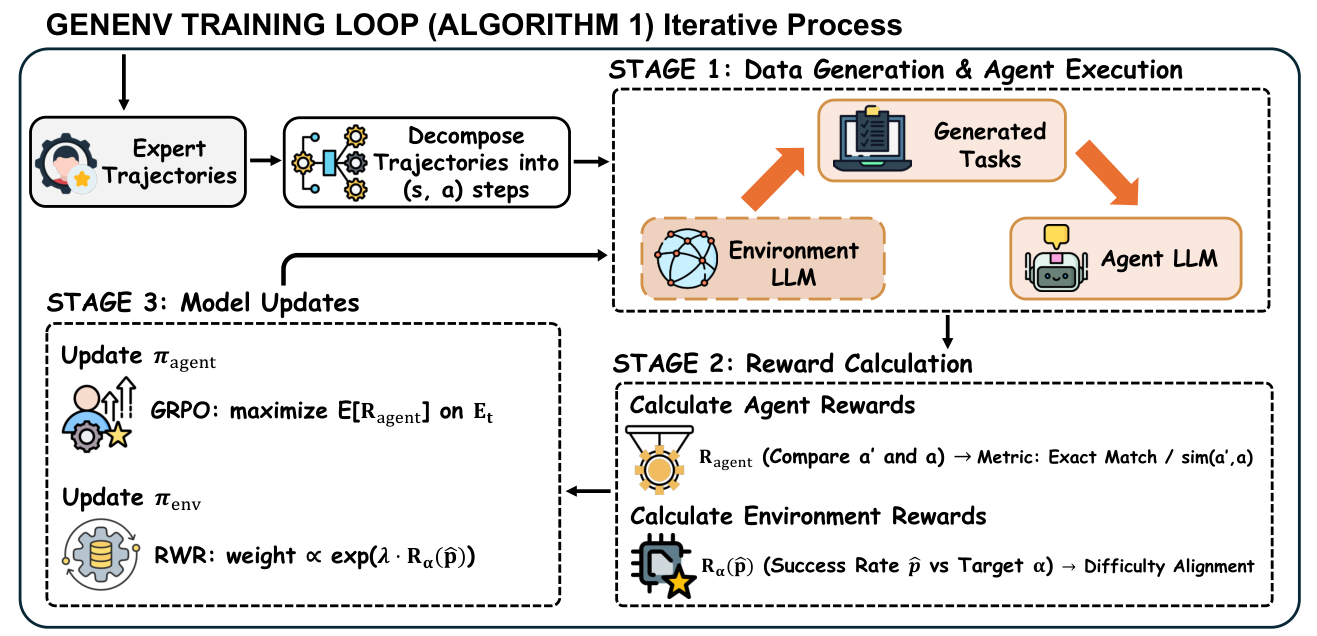 图 13. 把可学习带变成一个控制信号:一个环境策略生成任务、智能体去尝试、环境因命中目标成功率(α≈0.5)而获奖励——于是二者协同演化、课程自然涌现。(图片来源:Guo et al., 2025)
图 13. 把可学习带变成一个控制信号:一个环境策略生成任务、智能体去尝试、环境因命中目标成功率(α≈0.5)而获奖励——于是二者协同演化、课程自然涌现。(图片来源:Guo et al., 2025)
洞见 — 按学习信号筛,而不是按原始难度筛。 “太难”和”太容易”因为同一个原因失败(没有 reward variance),尽管它们感觉是相反的。多数流水线只按可解性筛;把可训练性当作一等的、相对策略的信号来处理,仍然少见——而这恰是流水线”演化”步获得其控制旋钮的地方。
要点。 可解 ≠ 有用。值得训练的任务,是当前策略大约解一半的那些;而那个目标会随智能体学习而移动。
开放挑战
这套配方有效,但它还年轻,而且它的若干承重假设比结果看上去更摇晃。这里是我会投以怀疑目光的地方。
验证才是真正的瓶颈。 一切都建立在一个可信的奖励之上,而 generator–verifier 不对称(上文)意味着我们随时离”无法生成的任务”或”无法检查的任务”只有一步之遥。更糟的是,学习型 verifier 会被hack:ARE 不得不给自己的 verifier 打补丁来抵御 RL 漏洞,R2E-Gym 也表明免执行 verifier 会奖励推理风格而非正确性。把可靠验证扩展到真正不可验证的领域(这份研究摘要好不好?)是压在大多数问题之下的开放难题。
污染被监管不足。 如果你生成的训练任务与你的评测 benchmark 相像,你就可能彻底骗了自己。然而多数系统只对泄漏做粗糙处理——排除少数仓库(SWE-smith、R2E-Gym)或依赖发布日期的时间先后(Endless Terminals)。合成任务与 held-out benchmark 之间的语义/嵌入层面重叠很少被度量。作为一个领域,我们大多是假设没有泄漏,而不是去检查它。
in-domain 收益 ≠ transfer。 这是让你保持诚实的那一条。在合成开发集上刷出大数字很容易;真正要紧的是向人工 benchmark 的迁移,而二者会显著背离——Endless Terminals 看到强劲的开发集收益,而向 TerminalBench 2.0 的迁移却很低,除非模型先做了 SFT warm-start。
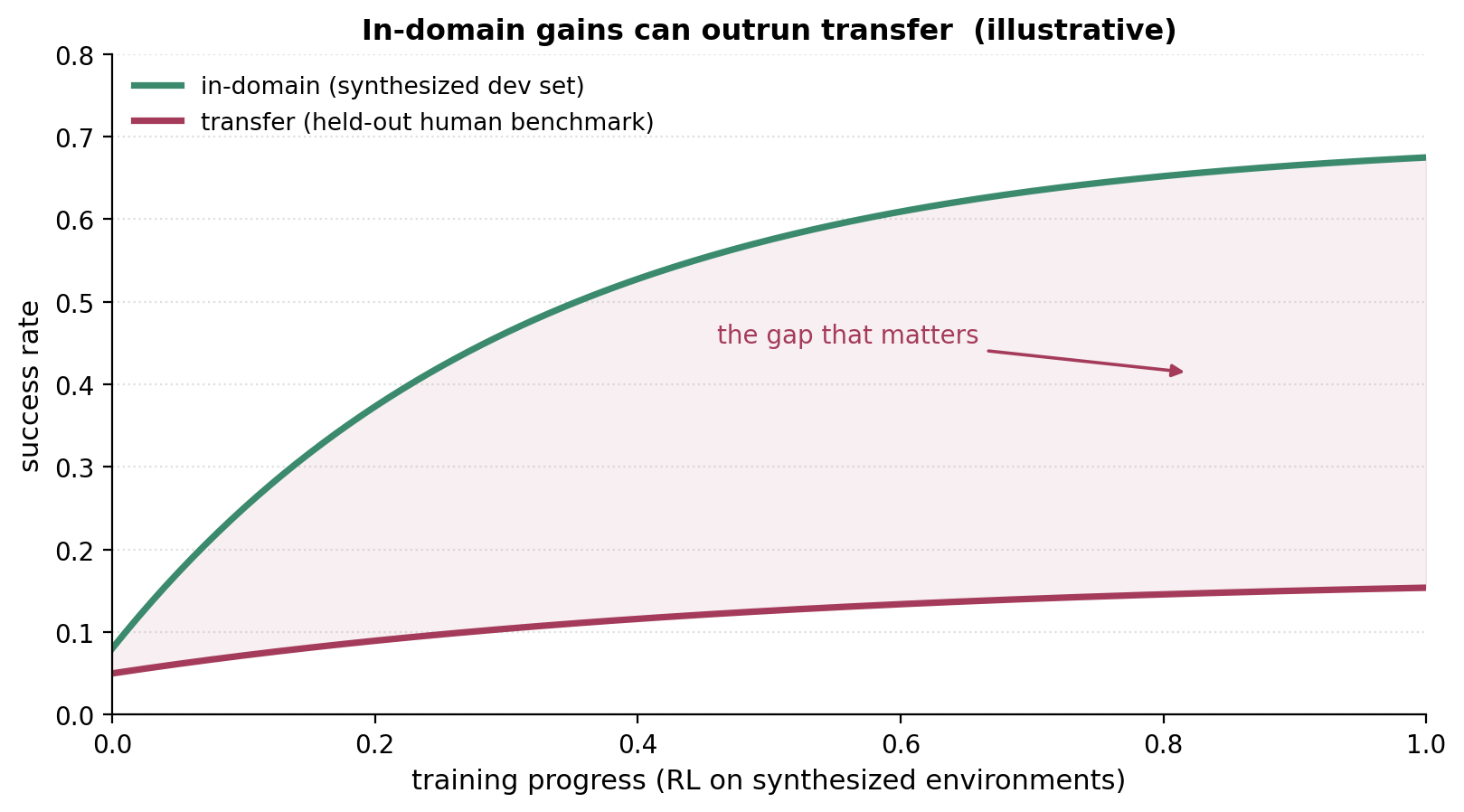 图 14. 容易挪动的那个数字(in-domain)和真正要紧的那个数字(transfer)不是同一个数字。
图 14. 容易挪动的那个数字(in-domain)和真正要紧的那个数字(transfer)不是同一个数字。
多样性边际递减。 加上第 900 个通用环境收益甚微(上文的多样性轴);领域开始怀疑,瞄准生成胜过单纯扩大生成——但那是留给续篇的故事。
前沿:协同演化与真实性。 真正自演化的 agent–环境回路(GenEnv、Agent-World)仍处早期,多半只跑了寥寥几个宏轮次。而且多数环境仍是同步且 ReAct 式的;真实部署是异步、事件驱动、多行动者的(ARE/Gaia2 是那个证明此事有多难的例外)。弥合 synthetic↔real 的真实性差距——真实的工具语义、鉴权、限流、schema 漂移——在很大程度上未解决;为 RL rollout 运行成千上万个容器的纯粹成本/基础设施负担同样未解决。
要点。 诚实的记分牌:验证、污染、迁移,是当今环境扩展结果最可能被夸大的三处。
致谢 / 来源:标注「图片来源」的图复制自所引论文;其余图均为原创。
如何引用
Zhang, Jiaxin. (Jun 2026). Environment Scaling for Agentic RL. Jiaxin Zhang’s Blog. https://jxzhangjhu.github.io/blog/2026/environment-scaling-for-agentic-rl/
或使用 BibTeX:
@article{zhang2026envscaling,
title = "Environment Scaling for Agentic RL",
author = "Zhang, Jiaxin",
journal = "Jiaxin Zhang's Blog",
year = "2026",
month = "Jun",
url = "https://jxzhangjhu.github.io/blog/2026/environment-scaling-for-agentic-rl/"
}
参考文献
[1] Anthropic. “Model Context Protocol (MCP) — Specification.” 2024.
[2] Chaithanya Bandi, et al. “MCP-Atlas: A Large-Scale Benchmark for Tool-Use Competency with Real MCP Servers.” arXiv:2602.00933, 2026.
[3] Victor Barres, Honghua Dong, et al. “τ²-Bench: Evaluating Conversational Agents in a Dual-Control Environment.” arXiv:2506.07982, 2025.
[4] Shihao Cai, Runnan Fang, et al. “AutoForge: Automated Environment Synthesis for Agentic Reinforcement Learning.” arXiv:2512.22857, 2025.
[5] Chen Chen, et al. “ACEBench: A Comprehensive Evaluation of LLM Tool Usage.” Findings of EMNLP 2025.
[6] Guanting Dong, Junting Lu, et al. “Agent-World: Scaling Real-World Environment Synthesis for Evolving General Agent Intelligence.” arXiv:2604.18292, 2026.
[7] Runnan Fang, Shihao Cai, et al. “Towards General Agentic Intelligence via Environment Scaling” (AgentScaler). arXiv:2509.13311, 2025.
[8] Romain Froger, et al. “ARE: Scaling Up Agent Environments and Evaluations” (with the Gaia2 benchmark). arXiv:2509.17158, 2025.
[9] Kanishk Gandhi, Shivam Garg, Noah D. Goodman, Dimitris Papailiopoulos. “Endless Terminals: Scaling RL Environments for Terminal Agents.” arXiv:2601.16443, 2026.
[10] Huan-ang Gao, Jiayi Geng, et al. “A Survey of Self-Evolving Agents: What, When, How, and Where to Evolve.” TMLR / arXiv:2507.21046, 2026.
[11] Jiacheng Guo, Ling Yang, et al. “GenEnv: Difficulty-Aligned Co-Evolution between LLM Agents and Environment Simulators.” arXiv:2512.19682, 2025.
[12] Wei He, et al. “VitaBench: Benchmarking LLM Agents with Versatile Interactive Tasks in Real-world Applications.” arXiv:2509.26490, 2025.
[13] Yuchen Huang, Sijia Li, et al. “Environment Scaling for Interactive Agentic Experience Collection: A Survey.” arXiv:2511.09586, 2025.
[14] Naman Jain, Jaskirat Singh, et al. “R2E-Gym: Procedural Environments and Hybrid Verifiers for Scaling Open-Weights SWE Agents.” arXiv:2504.07164, 2025.
[15] Carlos E. Jimenez, John Yang, et al. “SWE-bench: Can Language Models Resolve Real-World GitHub Issues?” arXiv:2310.06770, 2024.
[16] Xirui Li, Ming Li, et al. “ClawEnvKit: Automatic Environment Generation for Claw-like Agents.” arXiv:2604.18543, 2026.
[17] Ziyang Luo, et al. “MCP-Universe: Benchmarking Large Language Models with Real-World Model Context Protocol Servers.” arXiv:2508.14704, 2025.
[18] NovaSky-AI (Berkeley Sky Computing Lab). “SkyRL: A Modular Full-stack RL Library for LLMs.” GitHub, 2025.
[19] Jiayi Pan, Xingyao Wang, et al. “Training Software Engineering Agents and Verifiers with SWE-Gym.” arXiv:2412.21139, 2024.
[20] Shishir G. Patil, et al. “The Berkeley Function Calling Leaderboard (BFCL): From Tool Use to Agentic Evaluation of Large Language Models.” ICML / arXiv:2501.14249, 2025.
[21] Xiaoshuai Song, Haofei Chang, et al. “EnvScaler: Scaling Tool-Interactive Environments for LLM Agent via Programmatic Synthesis.” arXiv:2601.05808, 2026.
[22] The Terminal-Bench Team. “Terminal-Bench: A Benchmark for AI Agents in Terminal Environments.” 2025.
[23] verl-project. “verl / HybridFlow: A Flexible and Efficient RL Post-Training Framework.” GitHub.
[24] Zhaoyang Wang, Canwen Xu, et al. “Agent World Model: Infinity Synthetic Environments for Agentic Reinforcement Learning.” ICML / arXiv:2602.10090, 2026.
[25] Minrui Xu, Zilin Wang, et al. “EnvFactory: Scaling Tool-Use Agents via Executable Environments Synthesis and Robust RL.” arXiv:2605.18703, 2026.
[26] John Yang, Kilian Lieret, et al. “SWE-smith: Scaling Data for Software Engineering Agents.” arXiv:2504.21798, 2025.
[27] Shunyu Yao, Noah Shinn, et al. “τ-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains.” arXiv:2406.12045, 2024.