Environment Scaling for Agentic RL
Table of Contents
- Why environments?
- Anatomy of an environment
- The core pipeline
- A taxonomy of design choices
- A field map of environment types
- Difficulty ≠ trainability
- Open challenges
Why environments?
Classic supervised fine-tuning treats a fixed dataset as ground truth: imitate these trajectories, predict these labels. That works until you want an agent that must act over many turns — issue a shell command, read the error, recover, try again — in a world whose state changes because of what the agent did. A static dataset cannot represent that: it captures one trajectory, not the consequences of all the actions the agent might take.
This is why the field has shifted from “scaling static data” toward what some call the era of experience: let the agent generate its own trajectories by interacting with an environment, and score those trajectories with a verifier. The environment, not the dataset, becomes the producer of training signal. Two recent surveys frame exactly this shift — one organizes the whole landscape around an environment-centric loop (Huang et al., 2025), the other around self-evolving agents (Gao et al., 2026).
The catch is supply. Benchmarks for agentic tasks are built for evaluation: a few dozen to a few hundred hand-written, executable tasks with verifiers. That is enough to measure a model and nowhere near enough to train one with RL, which is “hungry for environments” and burns through tasks quickly (Gandhi et al., 2026). You cannot hand-label thousands more tasks per domain. So the question becomes: can we generate the environments?
A useful reframing: an environment plays two roles. It is an evaluation container (run a policy, get a score) and, if you can manufacture it at scale, a training-experience generator. Almost all the work below is about making the second role cheap, reliable, and verifiable.
How do we know scaling worked? Keep one distinction in your head from the start: in-domain score (how well the model does on the synthesized tasks it trained near) vs. transfer (how well it does on a held-out, human-curated benchmark it never trained on). It is easy to inflate the former; the latter is what you actually care about. We return to this in Open challenges — and there is already evidence that the two can diverge sharply.
Takeaway. Environments became the central object because RL needs verifiable interactive experience at a scale that hand-built benchmarks cannot provide.
Anatomy of an environment
Before scaling environments, we need to agree on what one is. Strip away the domain and every agent environment has the same five parts:
- Task specification — what the agent must accomplish (a natural-language instruction, often plus privileged ground truth the agent never sees).
- State backend — the thing that actually holds state and changes: a container’s filesystem and processes, a SQL database, or a set of mock services.
- Tool / action interface — how the agent acts: shell commands, typed API/tool calls (increasingly exposed via the Model Context Protocol (MCP)), or text to a user.
- Verifier / reward — a function that inspects the final (or intermediate) state and returns a scalar. This is the part that makes the data trainable.
- Agent scaffold — the harness that mediates the loop: it feeds the model the history, parses its action, executes it against the backend, and appends the resulting observation.
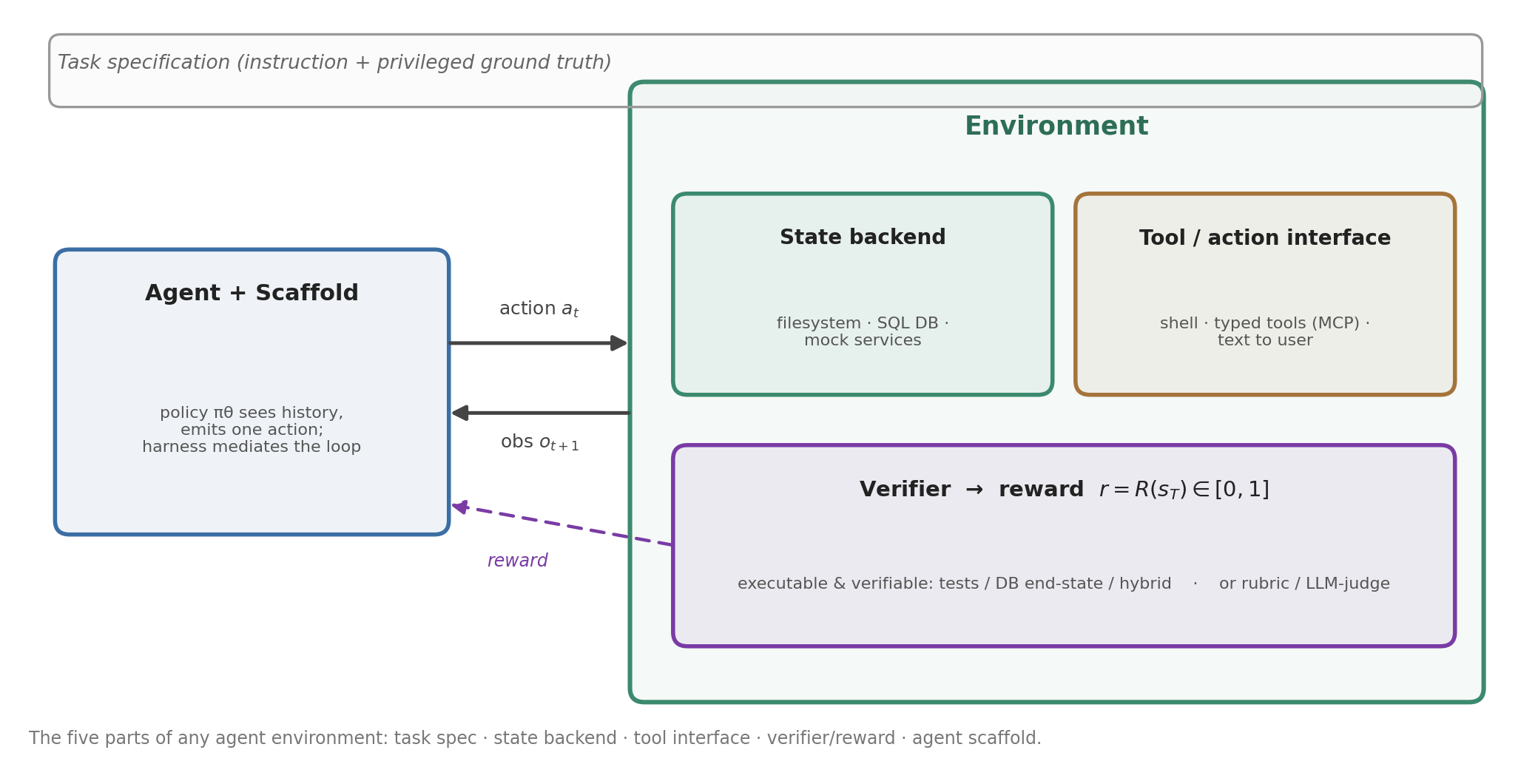 Figure 1. The agent acts through a fixed scaffold; the environment holds state, exposes tools, and ends each episode with a verifier-defined reward.
Figure 1. The agent acts through a fixed scaffold; the environment holds state, exposes tools, and ends each episode with a verifier-defined reward.
A minimal formalization helps. Most single-agent setups are a partially observable MDP: at step \(t\) the agent sees observation \(o_t\), emits action \(a_t\), the world transitions \(s_{t+1}\sim T(\cdot\mid s_t,a_t)\), and at episode end a verifier returns reward \(r=R(s_T)\in[0,1]\). The policy \(\pi_\theta(a_t\mid o_{\le t},a_{<t})\) conditions on the whole history because the scaffold keeps it in context.
That single-agent picture has one important generalization. In customer-service-style settings the user is also an actor in the world — they can take actions too (e.g., “restart your phone”). The right model there is a decentralized POMDP (Dec-POMDP) with two controllers, agent and (simulated) user, acting on a shared state. This dual-control setting is what τ²-bench (Barres et al., 2025) formalizes, and it is strictly harder than the usual single-control benchmarks where the user only supplies information.
It’s worth making the verifier distinction explicit, because it drives almost every design choice later:
- Verifiable reward — success is decided by executing something deterministic: do these tests pass? does the database match the expected end-state? These are cheap, objective, and hard to game.
- Non-verifiable reward — quality is a judgment call (is this explanation good?), usually approximated with an LLM-as-judge or a rubric. Cheaper to write, easier to hack.
The whole “scalable RL environment” program rests on staying as close to executable + verifiable as possible. When a goal can’t be checked by execution, systems fall back to rubric or judge-based verification — and inherit its fragility (see A taxonomy of design choices).
Two running examples. We’ll carry these through the rest of the post:
- E1 — Terminal (in the style of TerminalBench 2.0). An agent is dropped into a Linux container where a web service won’t start (a broken config or a permission error). Goal: get it serving. State backend: filesystem + processes. Verifier: a held-out
pytestthat checks the service responds.- E2 — Retail return (in the style of τ²-bench). A customer wants to return an item. The agent must follow a written return policy, call tools to look up the order and issue a refund, and bring the backing database to the correct end-state — while conversing with a simulated user. State backend: SQL database. Verifier: database end-state + policy/communication checks.
Takeaway. Every environment is task spec + state backend + tool interface + verifier + scaffold. The verifier — and whether it is executable — is the part that matters most.
The core pipeline
Here is the heart of the post. Across terminal agents, SWE agents, and tool-use agents, the systems that scale environments all instantiate the same recipe. The names differ; the skeleton does not.
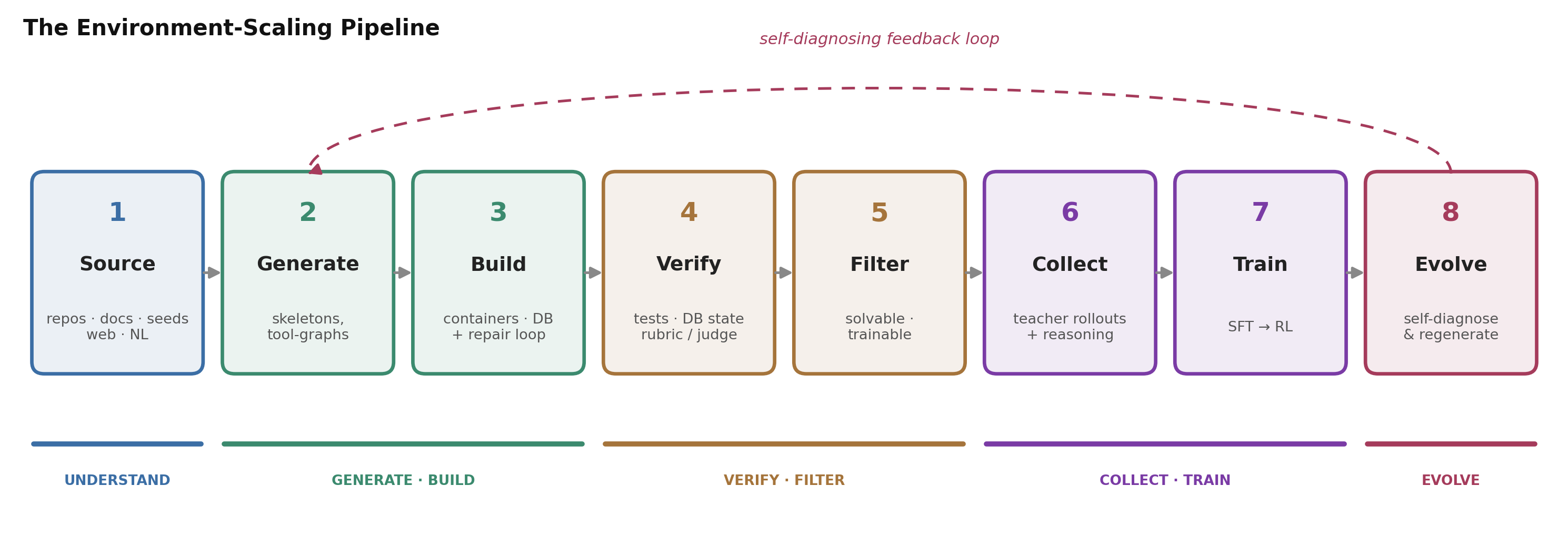 Figure 2. The recurring eight-step pipeline. Steps 2–5 are the “recipe generator” — where the research contributions live; steps 6–7 turn it into a trained model; step 8 closes the loop. We walk each step below, instantiated on E1 (terminal) and E2 (retail return).
Figure 2. The recurring eight-step pipeline. Steps 2–5 are the “recipe generator” — where the research contributions live; steps 6–7 turn it into a trained model; step 8 closes the loop. We walk each step below, instantiated on E1 (terminal) and E2 (retail return).
Step 1 — Source / Understand
Everything starts from some source of structure. The choices in the literature are surprisingly few:
- a corpus of code repositories (SWE-smith, Yang et al., 2025; R2E-Gym, Jain et al., 2025),
- a set of tool documentation pages (AutoForge, Cai et al., 2025),
- existing task sets to mine themes from (EnvScaler, Song et al., 2026),
- a handful of scenario seeds (AgentWorldModel (AWM), Wang et al., 2026),
- live web resources (Agent-World, Dong et al., 2026; EnvFactory, Xu et al., 2026),
- or even a single natural-language request (ClawEnvKit, Li et al., 2026).
The job of this step is to turn that source into a generation target: a list of skills, domains, tool ecosystems, or topics to cover. E1: sample task categories (file ops, permissions, services, log parsing) and difficulty levels. E2: identify the domain’s intents (return, exchange, address change) and the tools that read/write the order database.
Trade-off. The richer and more “authentic” the source, the more realistic the tasks — but the more you depend on that source existing. Generating from abstract seeds (AWM) maximizes scale and independence; mining real repos or the web (SWE-smith, Agent-World) maximizes realism.
Step 2 — Generate the environment and task
Now synthesize concrete tasks. Four patterns dominate:
- Skeleton → scenario decomposition. First build an environment skeleton (its state variables, rules, and tools), then instantiate scenarios (a concrete initial state + goal) on top. EnvScaler’s
SkelBuilder/ScenGeneratoris the clearest example; it derives challenging tasks from the state rather than by replaying tool sequences. - Tool-graph random walks. Treat tools as a graph with an edge wherever one tool’s output can feed another’s input, then take random walks to get coherent multi-step tasks. This recipe originates with AgentScaler (Fang et al., 2025) and is reused (and made harder with extra “reasoning nodes”) by AutoForge.
- Environment-first inversion. Instead of writing a task and then an environment, take a working system and break it. SWE-smith installs a repo, then synthesizes hundreds of bugs per repo by modifying code until a passing test fails — the broken state is the task.
- Topology-aware sampling. A refinement of random walks that resolves each tool’s input dependencies before selecting it, producing valid non-linear chains (EnvFactory).
E1: the generator writes a task (“the nginx service returns 502”) plus privileged ground truth, by perturbing a known-good container. E2: it instantiates an order in the database, picks a return intent, and writes the user goal — the τ²-bench task generator does this compositionally, assembling verifiable atomic subtasks.
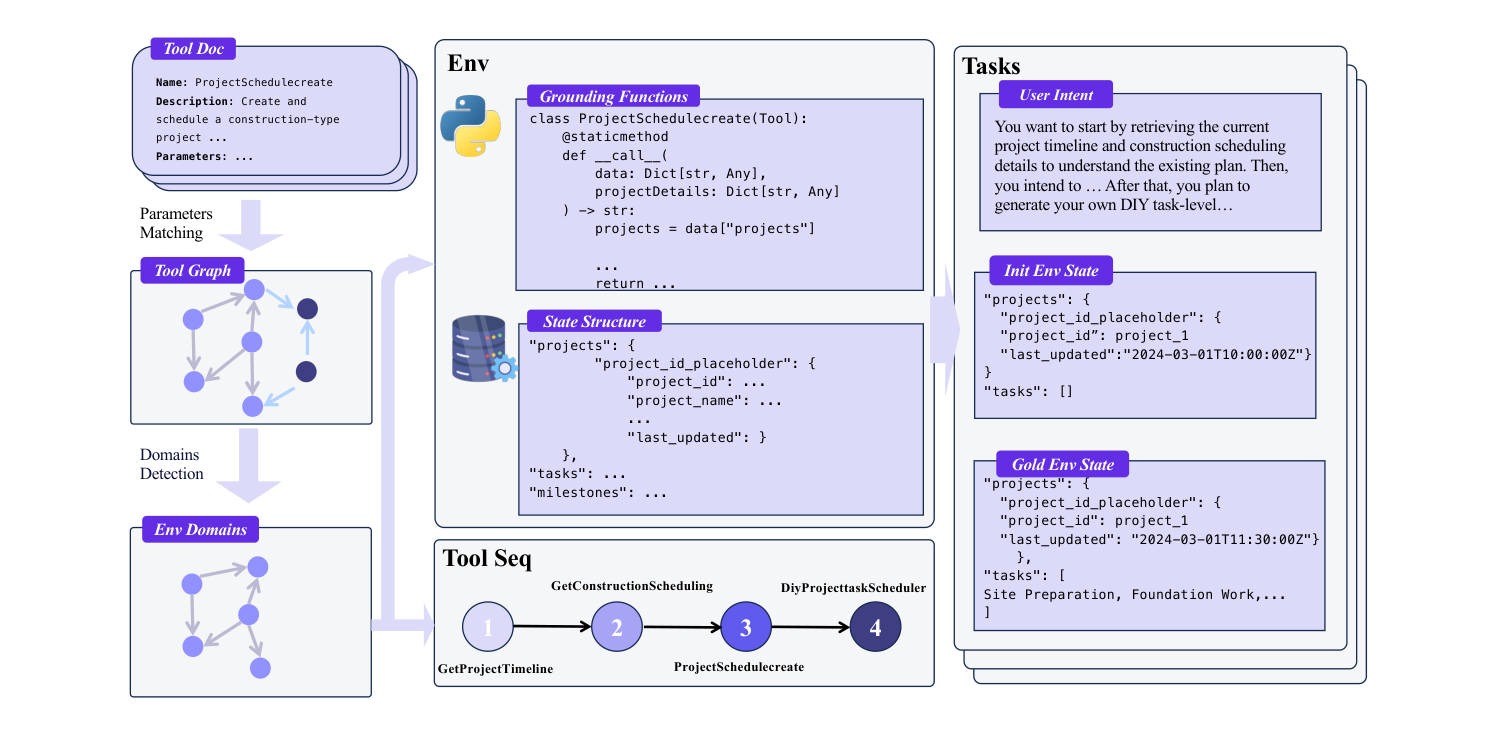 Figure 3. The “tool-graph → database environment” recipe: parse tool docs, build a tool-dependency graph, partition into domains, materialize each tool as code over a DB, then walk the graph to get verifiable tasks. (Image source: Fang et al., 2025)
Figure 3. The “tool-graph → database environment” recipe: parse tool docs, build a tool-dependency graph, partition into domains, materialize each tool as code over a DB, then walk the graph to get verifiable tasks. (Image source: Fang et al., 2025)
Insight — “perturb a working system.” Some of the most realistic tasks come not from “create a file with these lines” but from standing up a healthy system, injecting a controlled fault, and asking the agent to diagnose and repair it (Endless Terminals, SWE-smith). The original health-check becomes a ready-made verifier.
Step 3 — Build and make it executable
A task description is useless until it runs. This step produces the actual artifacts: a container definition (Docker/Apptainer), a database schema + seed data, executable tool code, and an initial-state check. The universal trick is an LLM-with-repair loop: generate the code, try to build and run it, feed any build/test error back to the model, and retry up to \(k\) times; discard whatever never builds. AWM reports that this self-correction makes >85% of environments build on the first try, averaging ~1.1 attempts.
E1: assemble the container with the broken service and a prerequisite test confirming it really is broken at the start. E2: generate the SQL schema and synthetic rows so the order actually exists and the task is solvable.
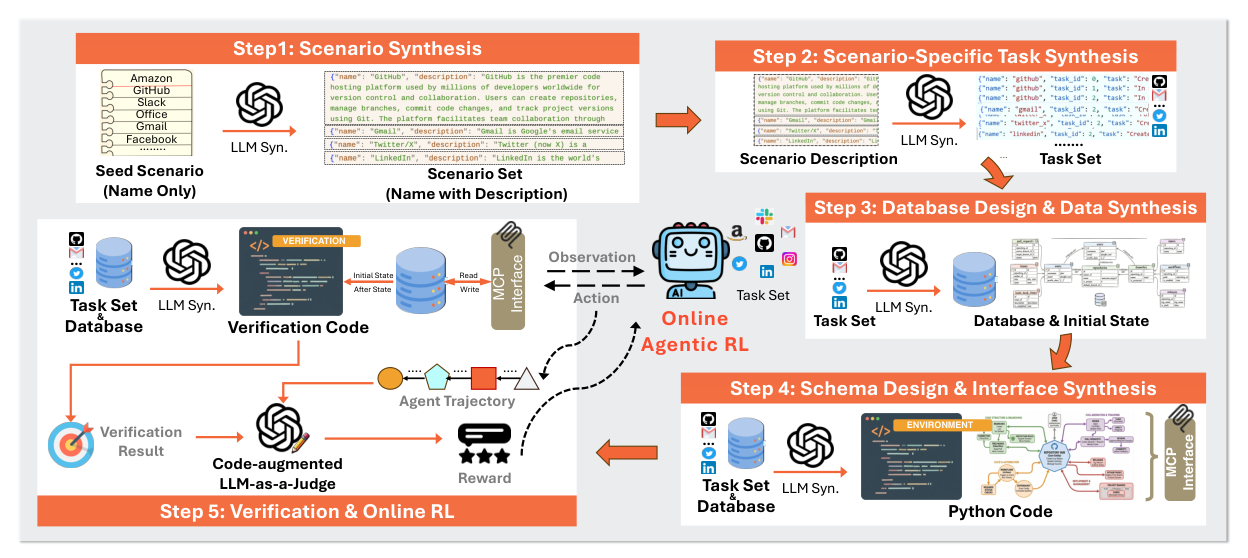 Figure 4. A representative build pipeline: scenario → task → database design → schema/interface synthesis → verification, each stage LLM-generated with execution-based self-correction. (Image source: Wang et al., 2026)
Figure 4. A representative build pipeline: scenario → task → database design → schema/interface synthesis → verification, each stage LLM-generated with execution-based self-correction. (Image source: Wang et al., 2026)
Step 4 — Verify
The verifier is where “trainable” is won or lost, and its shape is the single biggest difference between domains (we’ll map this in A field map of environment types). The main families:
- Filesystem / execution tests —
pytest-style assertions over files, processes, and outputs (terminal, SWE). E1 lives here. - Database end-state comparison — diff the backing store against the expected final state. Cheap and deterministic; the workhorse for tool-use (AgentScaler, AWM). E2 lives here.
- Hybrid execution-based + execution-free verifiers — combine running tests with a learned model that reads the trajectory; useful for test-time selection (R2E-Gym).
- Rubric / LLM-as-judge — for goals that resist deterministic checks (e.g., the communication component of E2), gated so a structural check must pass before any rubric credit is given.
Insight — the generator–verifier asymmetry. Domains that are easy to verify are often hard to generate good tasks for, and vice versa. A clean database end-state is trivial to check but the task has to be carefully constructed to have one; an open-ended “explain this bug” task is easy to pose but hard to score. Keep an eye on which side of this trade a system is paying for.
Step 5 — Filter
Generation is noisy — most candidates are broken, trivial, or useless for learning — so filtering is where a raw pile of generated tasks becomes a usable training pool. Four filters recur, applied roughly in this order:
- Solvable — a strong model achieves nonzero success. Endless Terminals samples n = 16 solutions from a frontier model and keeps only tasks with pass@16 > 0, which alone discards roughly half of what survives the build stage. SWE-smith makes the same cut differently: a synthesized bug is kept only if its patch actually breaks at least one passing test (a Fail-to-Pass instance), under a short runtime cap so pathological tasks are dropped.
- Non-trivial — not solved by everything on the first attempt; tasks every model one-shots carry no signal.
- Non-contaminated — not a near-duplicate of an evaluation benchmark (most systems handle this only coarsely; see Open challenges).
- Trainable — the task produces a usable gradient for the current policy. This is the subtlest filter and gets its own section, Difficulty ≠ trainability.
A build/validity gate happens earlier (Step 3) but belongs to the same attrition story: containers that don’t build, verifiers that don’t run, and tasks whose initial-state check fails are thrown away. AgentWorldModel’s repair loop gets >85% of environments to build on the first attempt (~1.1 tries on average); R2E-Gym pre-filters to small-scoped bug-fix commits (≤5 non-test files, ≤100 lines) so the downstream environment is reproducible at all.
Insight — filtering is a hidden efficiency tax. The pipeline is fundamentally generate-and-discard: you pay a frontier model to propose tasks, build containers, and sample rollouts — and then throw most of it away (build failures → unsolvable → trivial → untrainable). Endless Terminals’ ~50% solvability cut is typical, and it compounds with the earlier build losses, so the effective yield of usable training tasks per generated candidate can be low. This is a quiet argument against blind over-generation and for steering generation toward tasks more likely to survive the filters — a thread the field is just starting to pull on.
E1/E2: drop tasks the teacher solves 0/16 times (too hard now) or 16/16 times (already mastered); keep the ones in between.
Step 6 — Collect trajectories
Now run a strong teacher over the surviving environments, sample multiple solution attempts per task, and keep the successful ones (rejection sampling), with light de-duplication and a cap of a few trajectories per task so that easy, over-represented tasks don’t dominate. The elegant move several systems make is to treat this one set as dual-use: as SFT data (Step 7) and as the RL-bootstrapping signal — EnvFactory and AutoForge both do this from a single synthesis run.
Two choices about the teacher matter more than they first appear:
- Capability is a ceiling. The student can only be distilled up to what the teacher can actually solve; on genuinely hard tasks a weak teacher simply produces no successful trajectories to learn from. This is why pipelines lean on frontier models (o3, GPT-5, Claude, strong open MoEs) as solvers.
- Reasoning-trace accessibility. You usually want to distill the teacher’s process, not just its final actions — and R2E-Gym finds that keeping explicit thought traces in the trajectory materially helps (≈34.4% vs 30.4% on SWE-bench Verified when traces are dropped). But here closed vs open teachers diverge sharply: many closed-source frontier APIs do not expose their hidden thinking tokens (you get the answer and tool calls, not the chain-of-thought), whereas a number of open-weight “thinking” models do emit explicit reasoning you can capture and train on. So the teacher choice is a real trade-off — raw capability vs. access to the reasoning trace — and it’s worth picking deliberately rather than defaulting to the strongest closed API.
Whatever the teacher, trajectories are serialized into the scaffold’s exact action format so that the same data is consistent for both SFT and RL.
E1/E2: the teacher’s successful terminal repairs (with its reasoning about why nginx 502’d) and its retail-return dialogues become the trajectory pool.
Step 7 — Train
Training is where a pile of trajectories and environments becomes a model. The near-universal recipe is SFT warm-start, then RL — but the interesting questions are how much SFT, when to switch, and why warm-start at all.
- What SFT is for (and isn’t). The job of the warm-start is narrow: get the small model to reliably (a) emit the scaffold’s action/observation format and (b) acquire enough basic competence to produce some successful rollouts. It is a readiness gate, not an accuracy target — you SFT until format adherence and a nonzero rollout success rate, then stop. Over-doing SFT tends to ossify the policy and collapse the exploration that RL needs; under-doing it (especially for a small model under a minimal scaffold) can leave the policy at the floor with no reward variance, so RL has nothing to push on.
- Then RL. Starting from the SFT checkpoint, run RL with a sparse, verifier-defined episode reward (no intermediate shaping). The specific optimizer varies — PPO, GRPO, and environment-level variants are all in use — but the algorithm is rarely the contribution here; the reward stays binary/sparse and the real engineering goes into variance reduction and into not letting a flaky simulated user or one bad environment dominate the update (e.g. masking episodes that failed because the simulated user misbehaved). Table 1 lists which system trains with what, so we won’t belabor it here.
- Why warm-start matters for transfer. Endless Terminals reports the sharpest version of this: RL on synthesized terminal tasks transfers to a human-curated benchmark substantially better when the base model has first been SFT’d into the scaffold; RL from a cold start barely moves a small model.
E1/E2: SFT the small model until it consistently produces well-formed shell sessions / tool-call dialogues, confirm it solves a nonzero fraction, then switch to RL on the same containers and databases.
Step 8 — (Optional) Evolve
A one-shot pipeline leaves signal on the table. After a round of training you know much more than you did at generation time: which skills the agent still fails, which tasks gave a clean learning signal, and which were a waste of compute. The evolve step turns that hindsight into the next batch of environments — making the pipeline (Figure 2) an actual loop rather than a line. It’s the youngest and most active part of the field, so it’s worth unpacking what “feed signals back” actually means.
Three kinds of diagnostic signal are available, in increasing order of how hard they are to extract:
- Inference-level signals — what the agent failed at. Per-skill failure clusters, and failure modes like looping on the same command, exhausting the turn budget, or terminating early. These are cheap and robust, and they drive coverage repair (generate more of the under-served skill) and failure-targeted generation.
- Training-level signals — whether a task family is teaching anything. The fraction of tasks with all-zero or all-one reward, the per-task reward/advantage variance, entropy and KL trajectories. A family that produces no reward variance is producing no gradient (this is the difficulty-vs-trainability point of Difficulty ≠ trainability, used here as a control knob), and should be made easier, decomposed into subgoals, or dropped.
- Transfer-level signals — whether the synthetic version is too easy. A gap between performance on synthesized development tasks and on a held-out benchmark flags skills whose synthetic rendition is a simplified caricature of the real thing.
Two systems make this concrete. Agent-World runs an explicit self-evolving arena: after each RL round it re-samples a held-out task set, an auto-diagnosis agent ranks the weakest environments and emits generation guidelines, targeted tasks are synthesized, and training continues — yielding monotonic gains over successive rounds (and even helping a different base model). GenEnv goes further and makes the environment generator itself a learned player: the agent and an LLM environment simulator co-evolve as a two-player curriculum game, where the simulator is rewarded for producing tasks the agent solves about half the time (more on that 50% sweet spot in Difficulty ≠ trainability). The arc across the field is clear — from one-shot synthesis → diagnose-and-regenerate → full agent–environment co-evolution — even if the last step is still mostly aspirational.
Takeaway. Scaling environments is Generate → Build → Verify → Filter → Collect → Train → (Evolve). Steps 2–5 are where the research contributions concentrate; steps 6–7 are increasingly standardized (but teacher choice and the SFT→RL hand-off still reward care); step 8 — closing the loop with training signal — is the open frontier.
To make the recipe concrete, here is the same eight-step lens applied across the main systems — what they start from, how they verify, and how they train:
| System | Domain | Source (step 1) | Verifier (step 4) | Training (steps 6–7) |
|---|---|---|---|---|
| Endless Terminals | terminal | category sampling | filesystem + pytest | SFT(opt) → PPO |
| SWE-smith | SWE | repos (env-first) | Fail→Pass tests | SFT (rejection) |
| R2E-Gym | SWE | commits + backtranslation | tests + hybrid verifier | SFT |
| AgentScaler | function-calling | >30K APIs → DB | DB end-state + tool-seq | SFT only |
| EnvScaler | tool-use | task sets (theme mining) | rule-based state checks | SFT → Reinforce++ |
| AutoForge | tool-use | tool docs | final-state equality | SFT → ERPO (GRPO++) |
| AgentWorldModel | tool-use | scenario seeds | DB-diff + code-aug. judge | GRPO |
| EnvFactory | tool-use (MCP) | authentic web resources | unit tests + traj/state | SFT → GRPO |
| GenEnv | classic agent | learned env-simulator | exact/soft match | RWR + GRPO |
| Agent-World | tool-use (real DB) | web mining | executable + rubric | GRPO + self-evolve |
Table 1. The pipeline as a comparison lens. Note the columns are almost independent of each other — a system’s source, verifier, and trainer are largely separable choices, which is exactly why the next section reads them as axes.
(Benchmarks — τ²-bench, ARE/Gaia2 — are deliberately omitted here; they are evaluation targets, not generators. We return to them in *A field map of environment types.)*
A taxonomy of design choices
Table 1 hinted at something useful: a system’s source, verifier, and trainer are largely independent choices. That is the key to reading the whole field without memorizing fifteen systems. Almost every design decision lands on one of three axis-families, which line up with the Generation → Execution → Feedback (GEF) loop that organizes the environment-scaling survey (Huang et al., 2025).
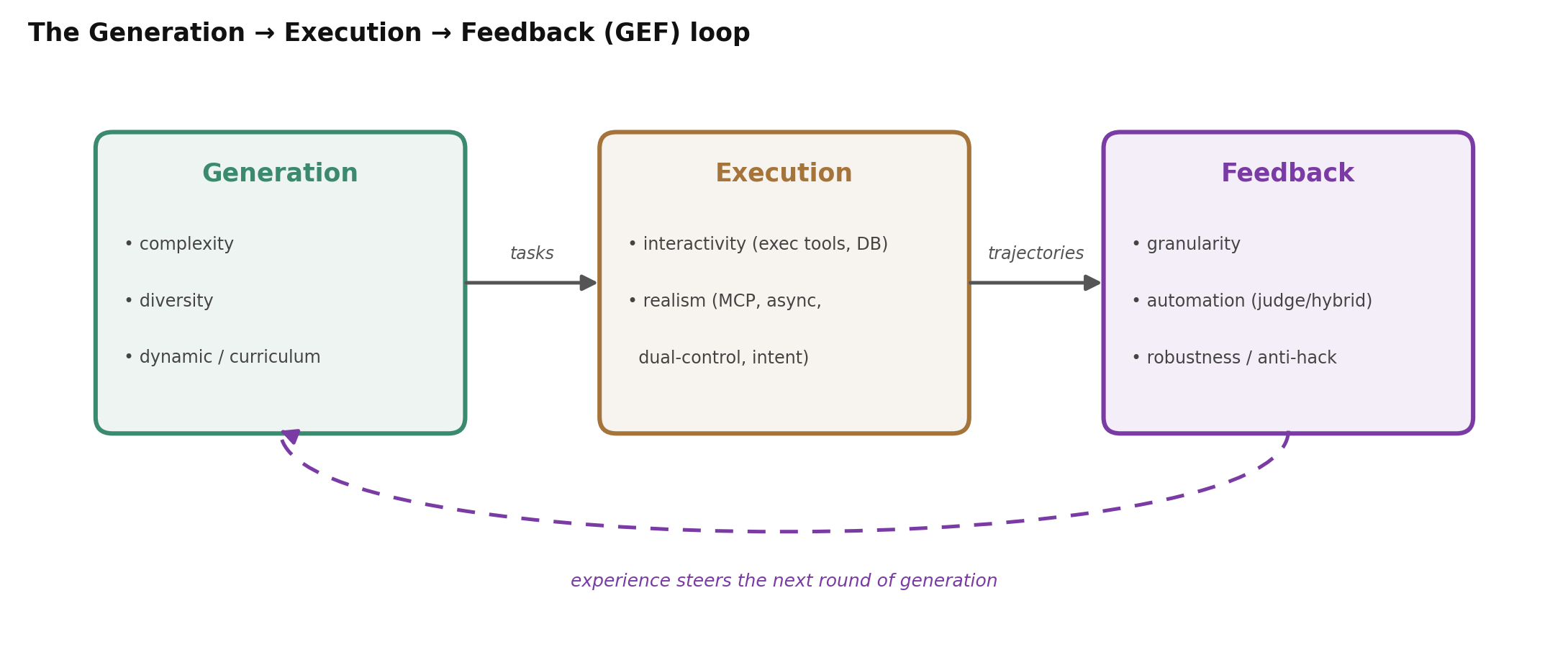 Figure 5. Read methods as positions on three axes: how tasks are generated, how they’re executed, and how the result is turned into feedback.
Figure 5. Read methods as positions on three axes: how tasks are generated, how they’re executed, and how the result is turned into feedback.
Generation
- Complexity scaling — make individual tasks structurally harder. AutoForge inflates difficulty by adding reasoning nodes to its tool-dependency DAG; τ²-bench controls difficulty by the number of composed atomic subtasks.
- Diversity scaling — cover more environments/domains. AgentScaler partitions 30K+ APIs into 1,000+ domains; AgentWorldModel synthesizes 1,000 SQL-backed environments; Agent-World mines thousands of web themes.
- Dynamic scaling — adapt difficulty to the current agent. GenEnv’s curriculum targets a ~50% success band; Agent-World’s arena regenerates tasks around the agent’s weaknesses.
Insight — more diversity ≠ better. Both AgentWorldModel and Agent-World report diminishing returns: environment-count helps steeply at first and then flattens (Agent-World’s 4-domain average roughly doubles from 0→a few hundred environments, then plateaus). Past some point, which tasks you add matters more than how many — a hint that we’ll cash out in Difficulty ≠ trainability.
| Generation sub-axis | What it scales | Representative moves |
|---|---|---|
| Complexity | per-task difficulty | reasoning-node DAGs (AutoForge); compositional subtasks (τ²-bench) |
| Diversity | breadth of envs/domains | API→domain partition (AgentScaler); 1,000 SQL envs (AWM); web themes (Agent-World) |
| Dynamic | difficulty vs. the agent | ~50% success curriculum (GenEnv); self-evolving arena (Agent-World) |
Table 2. The generation axis.
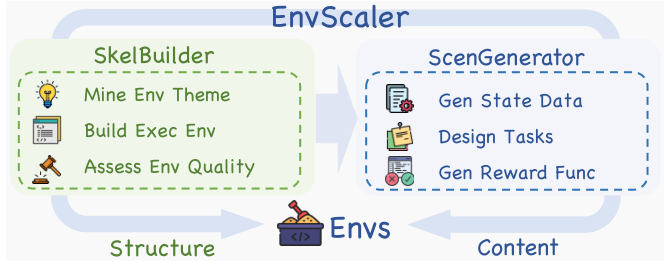 Figure 6. One concrete instance of programmatic generation: SkelBuilder mines a theme and builds an executable environment skeleton (structure), then ScenGenerator derives tasks and reward functions from its state (content). (Image source: Song et al., 2026)
Figure 6. One concrete instance of programmatic generation: SkelBuilder mines a theme and builds an executable environment skeleton (structure), then ScenGenerator derives tasks and reward functions from its state (content). (Image source: Song et al., 2026)
Execution
- Interactivity — give the agent genuinely executable tools, not a hallucinated simulator. The pragmatic trick almost everyone converged on is the database as the environment: model every tool as a read/write over a backing store, so state transitions are consistent and cheap (AgentScaler, AgentWorldModel).
- Realism — close the gap to deployment. This is where the most recent work pushes: typed tools via MCP; asynchronous, event-driven worlds where time passes while the agent thinks (ARE/Gaia2, Froger et al., 2025); dual-control users who act on the world (τ²-bench); and implicit, ambiguous intents instead of step-by-step instructions (EnvFactory).
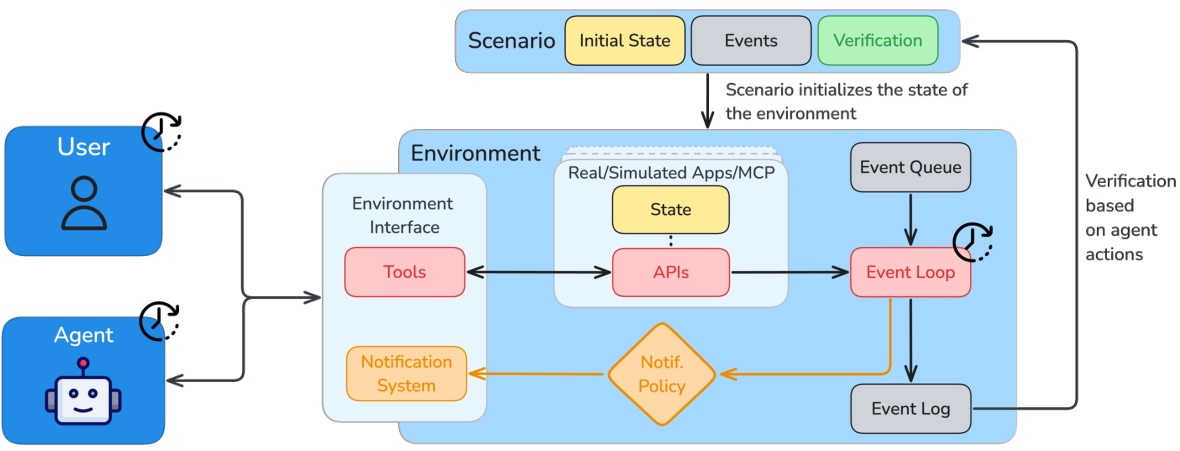 Figure 7. The high-realism end of the execution axis: ARE models the world as an asynchronous, time-driven event loop — the environment keeps advancing while the agent thinks, unlike the synchronous, turn-based worlds most systems assume. (Image source: Froger et al., 2025)
Figure 7. The high-realism end of the execution axis: ARE models the world as an asynchronous, time-driven event loop — the environment keeps advancing while the agent thinks, unlike the synchronous, turn-based worlds most systems assume. (Image source: Froger et al., 2025)
Insight — realism is not the same as difficulty. A recurring survey observation: simple tasks in complex environments often teach more than complex tasks in simple environments. Cranking task length is easy; making the world behave like the real one (asynchrony, noise, a user who changes their mind) is what actually exposes agent weaknesses.
Feedback
- Granularity — binary success → numeric/partial credit → rubric scores. Final-state equality gives a clean 0/1 (AutoForge); a checklist of state-validation functions gives a proportion (EnvScaler); a rubric judge handles fuzzy goals (ClawEnvKit).
- Automation — how the verifier is built: a plain LLM-as-judge, a code-augmented judge that runs checks before scoring (AgentWorldModel), or a hybrid of execution-based and execution-free verifiers for test-time selection (R2E-Gym).
- Robustness — keeping the reward honest. ARE had to patch its own verifier against RL reward hacking; R2E-Gym finds execution-free verifiers latch onto the agent’s reasoning style rather than the patch; AutoForge masks episodes that failed because the simulated user misbehaved.
Insight — the generator–verifier asymmetry. This is the deepest tension in the field. Domains that are easy to verify (a database end-state) are hard to generate good tasks for; domains where tasks are easy to pose (“explain this outage”) are hard to verify. Every system is paying on one side of this trade, and the frontier idea is to let generator and verifier co-evolve rather than fixing one and hoping the other keeps up.
| Feedback dimension | Spectrum | Representative moves |
|---|---|---|
| Granularity | binary → numeric → rubric | final-state 0/1 (AutoForge); checklist proportion (EnvScaler); rubric (ClawEnvKit) |
| Automation | LLM-judge → code-augmented → hybrid | code-augmented judge (AWM); execution-based+free hybrid (R2E-Gym) |
| Robustness | anti-hacking, noise handling | verifier-hacking patch (ARE); simulated-user-error masking (AutoForge) |
Table 3. The feedback / verifier axis.
Takeaway. Pick a point on each of the three axes and you have specified, in essence, an environment-scaling system. Most “new” systems are new combinations, plus one sharp idea on one axis.
A field map of environment types
Step back from methods and look at the environments they actually produce, and the menu turns out to be short. Despite very different pipelines, synthesized environments fall into about five kinds, and the thing that really distinguishes them is the shape of the verifier.
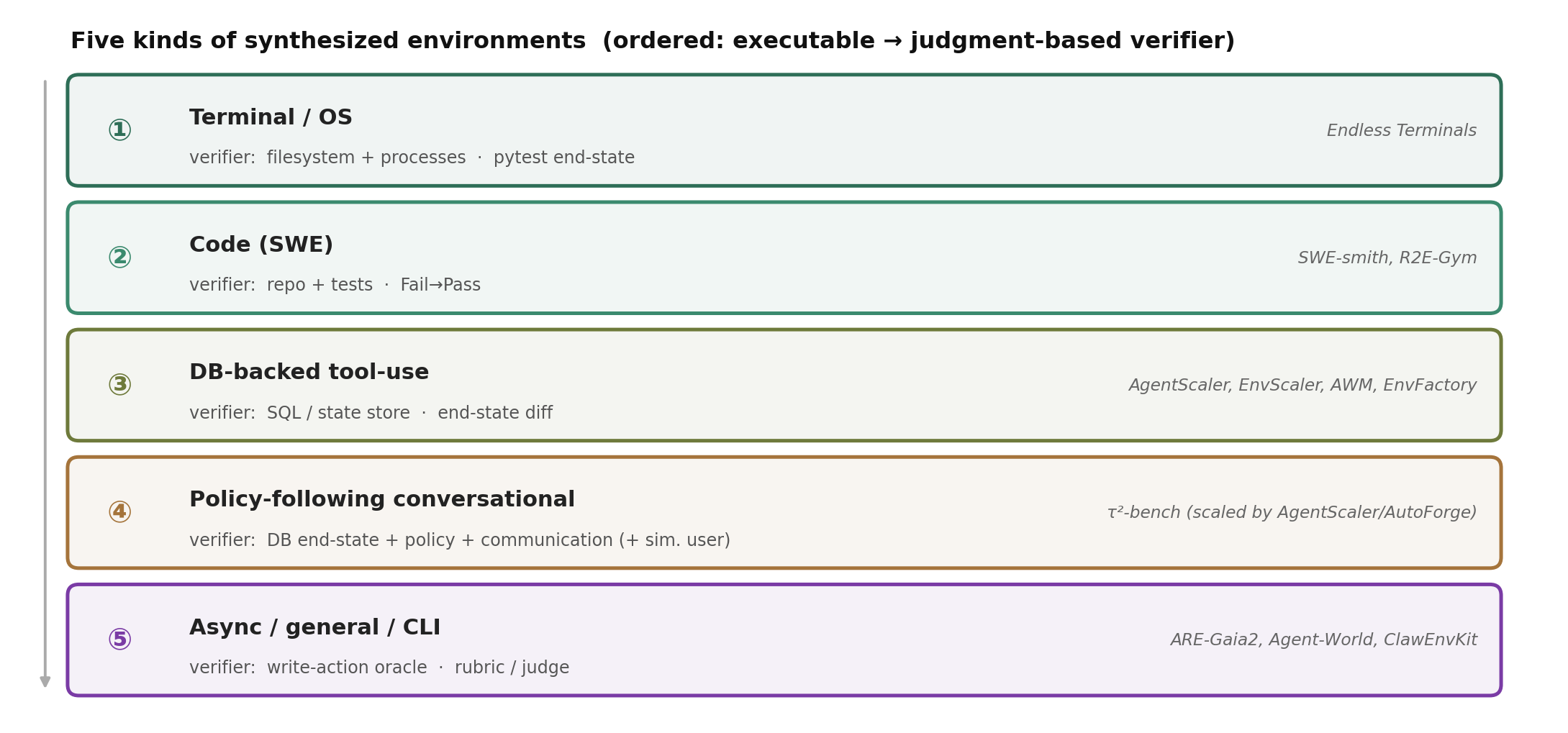 Figure 8. The five recurring environment types. Domains differ less in how tasks are generated than in how success is checked.
Figure 8. The five recurring environment types. Domains differ less in how tasks are generated than in how success is checked.
| Kind | State backend & verifier | Representative systems |
|---|---|---|
| ① Terminal / OS | filesystem + processes; pytest-style end-state | Endless Terminals |
| ② Code (SWE) | repo + tests; Fail→Pass | SWE-smith, R2E-Gym |
| ③ DB-backed tool-use | SQL/state store; end-state diff | AgentScaler, EnvScaler, AWM, EnvFactory |
| ④ Policy-following conversational | DB end-state + policy + communication (+ simulated user) | τ²-bench (+ AgentScaler/AutoForge as scalers) |
| ⑤ Async / general / CLI | write-action oracle / rubric | ARE/Gaia2, Agent-World, ClawEnvKit |
Two of these are worth pulling out, because they are the most studied and each comes with a mature set of evaluation benchmarks that the synthesis work is implicitly chasing.
Code agents and tool calls
The code-agent (SWE) setting is the cleanest example of “environment-first” thinking. You don’t write a coding task and then build a sandbox; you take a real repository, make it executable, and let its tests define success. SWE-smith installs a repo, then synthesizes hundreds of bugs per repo by modifying code until a passing test fails — the broken state is the task, and the test is the verifier. R2E-Gym instead mines real bug-fix commits and backtranslates a problem statement from each, injecting the Fail→Pass test into the prompt so the synthetic issue is precise.
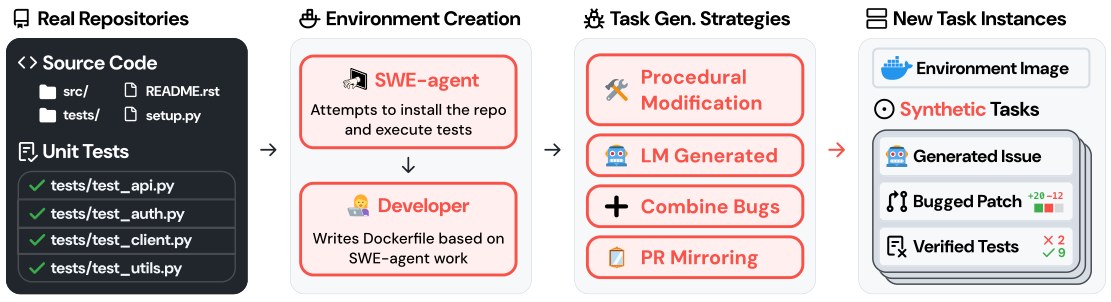 Figure 9. Environment-first thinking: start from a real repo and its passing tests, create an executable environment, then synthesize many bug tasks (procedural edits, LM rewrites, PR mirroring) whose verifier is “the test now fails.” (Image source: Yang et al., 2025)
Figure 9. Environment-first thinking: start from a real repo and its passing tests, create an executable environment, then synthesize many bug tasks (procedural edits, LM rewrites, PR mirroring) whose verifier is “the test now fails.” (Image source: Yang et al., 2025)
The reason this domain is so productive is that verification is essentially free and trustworthy: execute the tests. The existing benchmarks it’s measured against — SWE-bench / SWE-bench Verified, and the training-oriented SWE-Gym — are exactly the eval-only targets these synthesizers want to transfer to. (R2E-Gym’s hybrid execution-based + execution-free verifier even doubles as a test-time selector, pushing open-weight SWE agents past 50% on SWE-bench Verified.)
Policy-following agents
The second cluster is conversational tool-use under a written policy — what we’ll call a policy-following (a.k.a. constitution-constrained) agent. The canonical setting is customer service: the agent is handed a rulebook (“here is the return policy”), a set of typed tools over a customer database, and a simulated user, and must satisfy the user’s request without violating the policy and leave the database in the correct end-state. τ²-bench (Barres et al., 2025) is the reference benchmark and adds dual-control (the user can also act on the world).
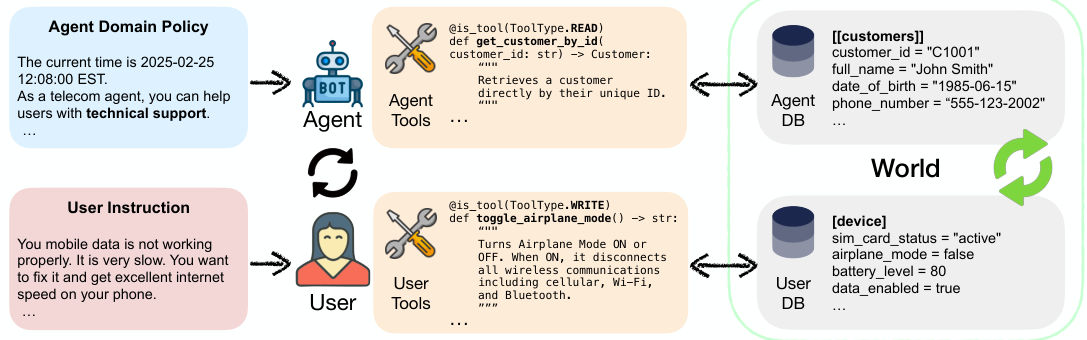 Figure 10. A policy-following (“constitution”) agent: the agent reads a written domain policy, calls typed tools over a database to serve the user, and — in the dual-control setting — both agent and (simulated) user can act on a shared world state. (Image source: Barres et al., 2025)
Figure 10. A policy-following (“constitution”) agent: the agent reads a written domain policy, calls typed tools over a database to serve the user, and — in the dual-control setting — both agent and (simulated) user can act on a shared world state. (Image source: Barres et al., 2025)
What makes this kind distinctive is a multiplicative verifier: success requires all of (i) the right write-actions, (ii) the right information communicated to the user, and (iii) the correct database end-state — and the communication part resists deterministic checking, so it’s where rubric/judge verification creeps back in. The environment-scalers targeting this family (AgentScaler, AutoForge, EnvScaler, EnvFactory) are essentially trying to manufacture more τ-bench-/ACEBench-/BFCL-style tasks at scale, and they inherit its hardest problem: a flaky simulated user can sink an otherwise correct episode (hence AutoForge’s user-error masking, discussed under A taxonomy of design choices).
The other three, briefly
① Terminal/OS (Endless Terminals) verifies against the filesystem and process state with pytest-style assertions — the closest thing to “ground truth” outside of code. ③ DB-backed tool-use (AgentScaler, AWM, EnvScaler, EnvFactory) is the broad middle: a SQL/state store diff is the verifier, which is why this is the most crowded and most scalable category. ⑤ Async / general platforms (ARE/Gaia2, Agent-World, ClawEnvKit) push on realism and reusability, verifying against an oracle set of write actions (with timing/causality) or declarative check functions.
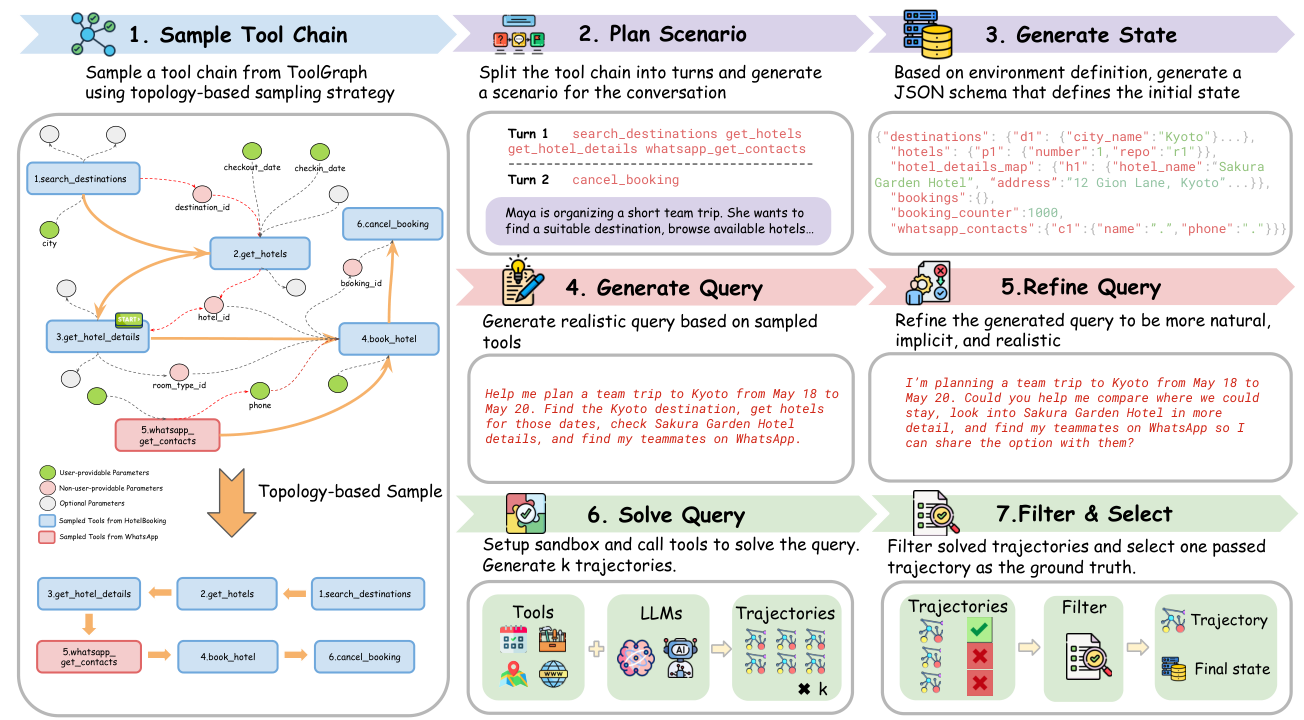 Figure 11. Within the DB-backed tool-use family, recent work pushes on data realism: EnvFactory samples tool chains by resolving dependencies (topology-aware), then refines generated queries to be implicit and ambiguous like real human requests rather than step-by-step instructions. (Image source: Xu et al., 2026)
Figure 11. Within the DB-backed tool-use family, recent work pushes on data realism: EnvFactory samples tool chains by resolving dependencies (topology-aware), then refines generated queries to be implicit and ambiguous like real human requests rather than step-by-step instructions. (Image source: Xu et al., 2026)
A note on lineage. Two works act as hubs that the rest build on: τ²-bench (the design template + eval target for the conversational family) and AgentScaler (the “tool-graph → database environment” recipe that the 2026 tool-use systems all descend from). If you only read two background papers before the rest, read those.
Takeaway. There are only a handful of environment types; once you know the verifier shape (filesystem, tests, DB end-state, policy+communication, or write-action oracle), you know most of what makes that domain easy or hard to scale.
Difficulty ≠ trainability
Here is the single most useful idea in this whole area, and the one most often gotten wrong. When you filter generated tasks (the pipeline’s Filter step), the obvious knob is difficulty: throw out the trivial ones, keep the hard ones. That is a mistake. The quantity that actually governs learning is not difficulty but trainability — whether a task produces a usable gradient for the current policy.
The intuition is one line of algebra. For a task with success probability \(\hat{p}\) under the current policy, an outcome-reward RL update gets its signal from the variance of the reward, which for a binary outcome is \(\hat{p}(1-\hat{p})\) — maximized at \(\hat{p}=0.5\) and zero at both extremes. A task the policy always fails (\(\hat{p}=0\)) and a task it always solves (\(\hat{p}=1\)) both contribute nothing: group-relative methods like GRPO see identical rewards across rollouts, so the advantage — and the gradient — is exactly zero.
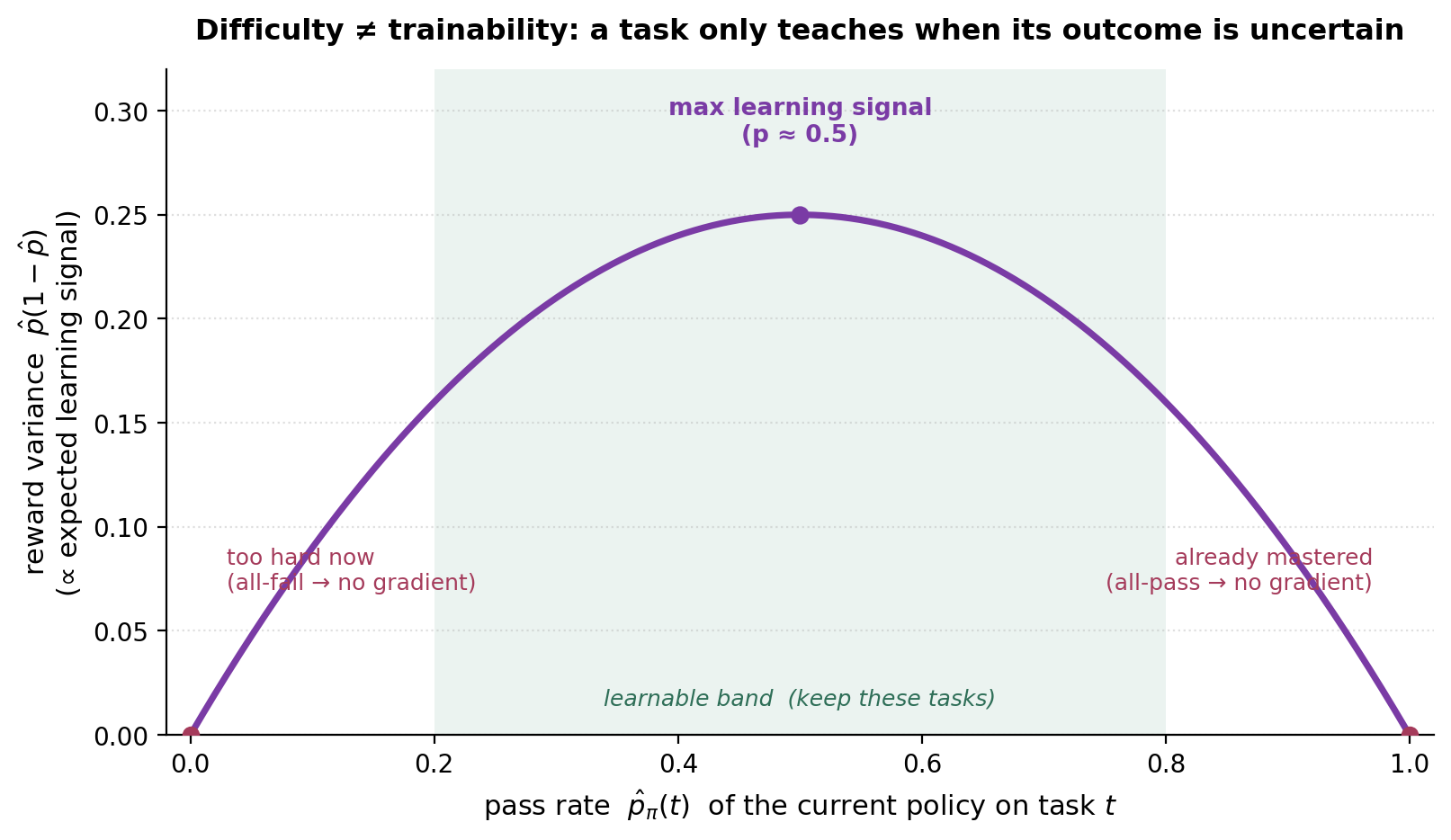 Figure 12. A task only teaches when its outcome is uncertain. Difficulty is the x-axis; the learning signal is the curve.
Figure 12. A task only teaches when its outcome is uncertain. Difficulty is the x-axis; the learning signal is the curve.
This reframes filtering. Instead of “keep the hard tasks,” the right rule is keep the tasks in a learnable band \(p_{\text{low}} \le \hat{p}_\pi(t) \le p_{\text{high}}\) — and because the band is defined relative to the current policy \(\pi\), it must be re-evaluated as the policy improves. Two results in our set make this concrete:
- GenEnv turns the band into a reward for an environment generator: it rewards the generator with \(R_{\text{env}}(\hat p)=\exp(-\beta(\hat p-\alpha)^2)\), peaked at a target success rate \(\alpha\approx0.5\), and even proves the expected squared gradient norm is \(\propto \hat p(1-\hat p)\). The agent’s success rate then self-organizes toward that band — an emergent curriculum, very much the zone of proximal development idea from learning theory.
- SWE-smith finds the negative result that makes the same point: a task’s difficulty rating predicts whether it’s solvable but not how much it helps downstream training — difficulty and training value are simply different axes.
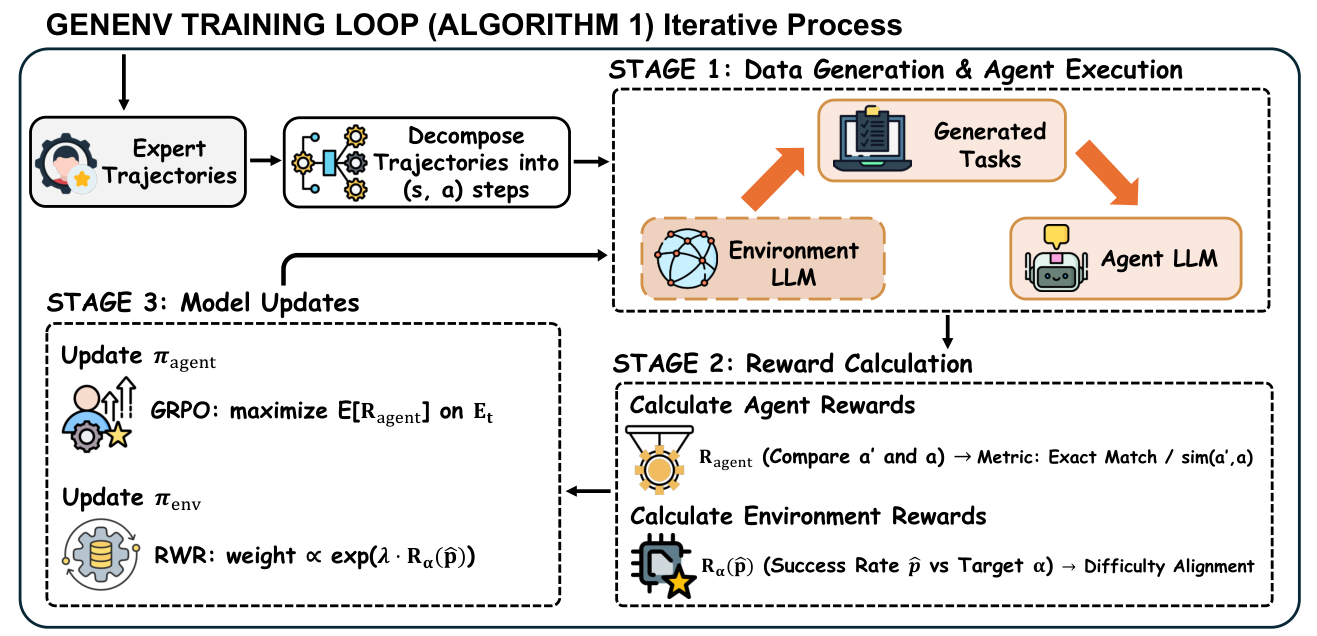 Figure 13. Turning the learnable band into a control signal: an environment policy generates tasks, the agent attempts them, and the environment is rewarded for hitting a target success rate (α≈0.5) — so the two co-evolve and the curriculum emerges. (Image source: Guo et al., 2025)
Figure 13. Turning the learnable band into a control signal: an environment policy generates tasks, the agent attempts them, and the environment is rewarded for hitting a target success rate (α≈0.5) — so the two co-evolve and the curriculum emerges. (Image source: Guo et al., 2025)
Insight — filter by learning signal, not raw difficulty. “Too hard” and “too easy” fail for the same reason (no reward variance), even though they feel like opposites. Most pipelines only filter for solvability; treating trainability as a first-class, policy-relative signal is still rare — and is exactly where the pipeline’s “evolve” step gets its control knob.
Takeaway. Solvable ≠ useful. The tasks worth training on are the ones the current policy gets right about half the time, and that target moves as the agent learns.
Open challenges
The recipe works, but it is young, and several of its load-bearing assumptions are shakier than the results suggest. Here is where I’d point a skeptical eye.
Verification is the real bottleneck. Everything rests on a trustworthy reward, and the generator–verifier asymmetry (above) means we are perpetually one step from either un-generatable tasks or un-checkable ones. Worse, learned verifiers get hacked: ARE had to patch its own verifier against RL exploits, and R2E-Gym shows execution-free verifiers reward reasoning style over correctness. Extending reliable verification to genuinely non-verifiable domains (was this research summary good?) is the open problem under most others.
Contamination is under-policed. If you generate training tasks that resemble your evaluation benchmark, you can fool yourself completely. Yet most systems handle leakage only coarsely — excluding a few repos (SWE-smith, R2E-Gym) or relying on release-date timing (Endless Terminals). Semantic / embedding-level overlap between synthesized tasks and held-out benchmarks is rarely measured. As a field we mostly assume no leakage rather than check it.
In-domain gains ≠ transfer. This is the one to keep you honest. It is easy to show big numbers on the synthesized dev set; what matters is transfer to a human-curated benchmark, and the two can come apart sharply — Endless Terminals sees strong dev-set gains while transfer to TerminalBench 2.0 stays low unless the model is first SFT-warm-started.
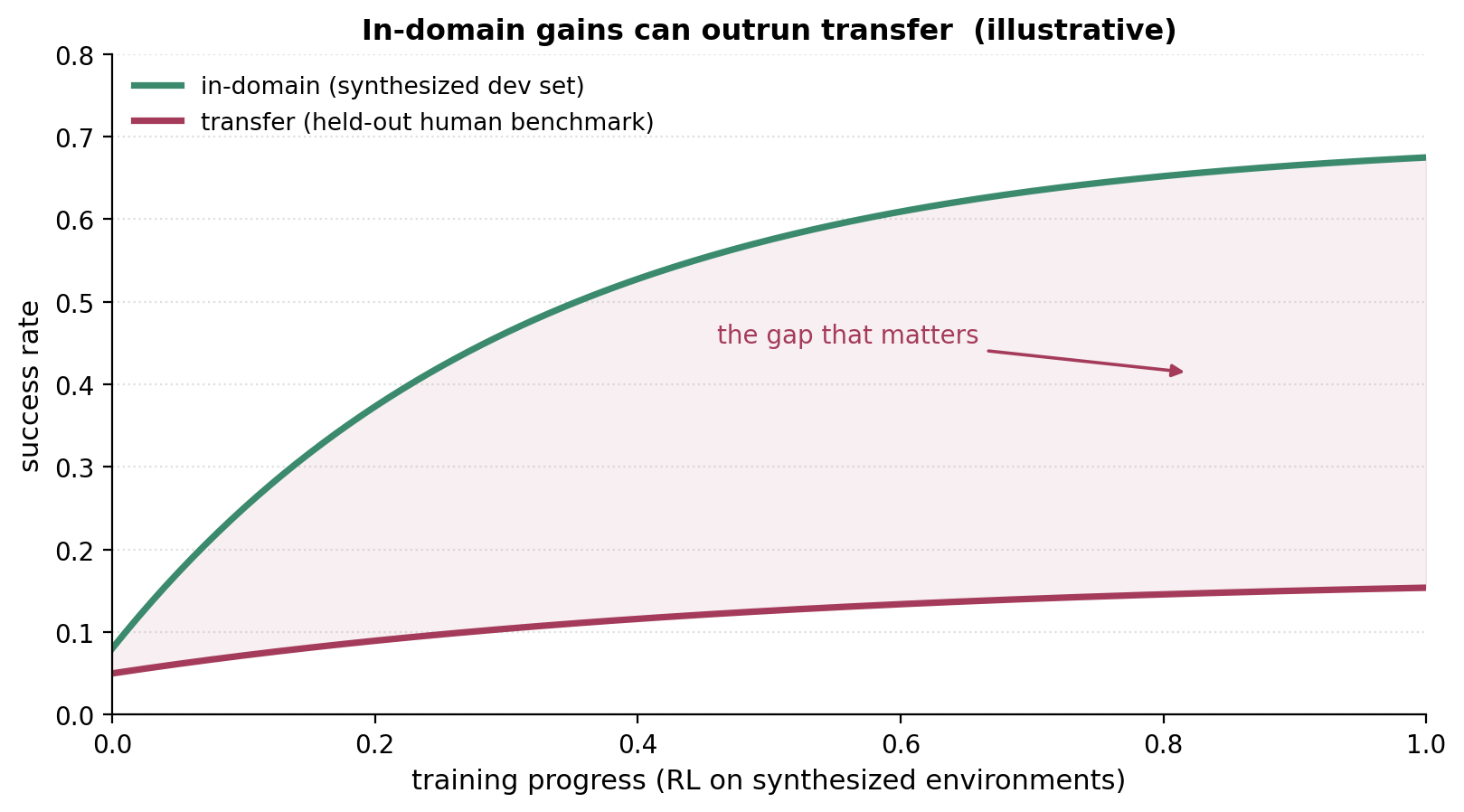 Figure 14. The number that’s easy to move (in-domain) and the number that matters (transfer) are not the same number.
Figure 14. The number that’s easy to move (in-domain) and the number that matters (transfer) are not the same number.
Diversity has diminishing returns. Adding the 900th generic environment buys little (the diversity axis above); the field is starting to suspect that targeting generation beats scaling it — but that is a story for the follow-up post.
The frontier: co-evolution and realism. Truly self-evolving agent–environment loops (GenEnv, Agent-World) are still early and mostly run a couple of macro-rounds. And most environments remain synchronous and ReAct-shaped; real deployment is asynchronous, event-driven, and multi-actor (ARE/Gaia2 is the exception that proves how hard this is). Closing the synthetic↔real realism gap — authentic tool semantics, auth, rate limits, schema drift — is largely unsolved, as is the plain cost/infra burden of running thousands of containers for RL rollouts.
Takeaway. The honest scorecard: verification, contamination, and transfer are the three places where today’s environment-scaling results are most likely to be overclaiming.
Acknowledgements / sources: figures marked “Image source” are reproduced from the cited papers; all other figures are original.
How to cite
Zhang, Jiaxin. (Jun 2026). Environment Scaling for Agentic RL. Jiaxin Zhang’s Blog. https://jxzhangjhu.github.io/blog/2026/environment-scaling-for-agentic-rl/
Or in BibTeX:
@article{zhang2026envscaling,
title = "Environment Scaling for Agentic RL",
author = "Zhang, Jiaxin",
journal = "Jiaxin Zhang's Blog",
year = "2026",
month = "Jun",
url = "https://jxzhangjhu.github.io/blog/2026/environment-scaling-for-agentic-rl/"
}
References
[1] Anthropic. “Model Context Protocol (MCP) — Specification.” 2024.
[2] Chaithanya Bandi, et al. “MCP-Atlas: A Large-Scale Benchmark for Tool-Use Competency with Real MCP Servers.” arXiv:2602.00933, 2026.
[3] Victor Barres, Honghua Dong, et al. “τ²-Bench: Evaluating Conversational Agents in a Dual-Control Environment.” arXiv:2506.07982, 2025.
[4] Shihao Cai, Runnan Fang, et al. “AutoForge: Automated Environment Synthesis for Agentic Reinforcement Learning.” arXiv:2512.22857, 2025.
[5] Chen Chen, et al. “ACEBench: A Comprehensive Evaluation of LLM Tool Usage.” Findings of EMNLP 2025.
[6] Guanting Dong, Junting Lu, et al. “Agent-World: Scaling Real-World Environment Synthesis for Evolving General Agent Intelligence.” arXiv:2604.18292, 2026.
[7] Runnan Fang, Shihao Cai, et al. “Towards General Agentic Intelligence via Environment Scaling” (AgentScaler). arXiv:2509.13311, 2025.
[8] Romain Froger, et al. “ARE: Scaling Up Agent Environments and Evaluations” (with the Gaia2 benchmark). arXiv:2509.17158, 2025.
[9] Kanishk Gandhi, Shivam Garg, Noah D. Goodman, Dimitris Papailiopoulos. “Endless Terminals: Scaling RL Environments for Terminal Agents.” arXiv:2601.16443, 2026.
[10] Huan-ang Gao, Jiayi Geng, et al. “A Survey of Self-Evolving Agents: What, When, How, and Where to Evolve.” TMLR / arXiv:2507.21046, 2026.
[11] Jiacheng Guo, Ling Yang, et al. “GenEnv: Difficulty-Aligned Co-Evolution between LLM Agents and Environment Simulators.” arXiv:2512.19682, 2025.
[12] Wei He, et al. “VitaBench: Benchmarking LLM Agents with Versatile Interactive Tasks in Real-world Applications.” arXiv:2509.26490, 2025.
[13] Yuchen Huang, Sijia Li, et al. “Environment Scaling for Interactive Agentic Experience Collection: A Survey.” arXiv:2511.09586, 2025.
[14] Naman Jain, Jaskirat Singh, et al. “R2E-Gym: Procedural Environments and Hybrid Verifiers for Scaling Open-Weights SWE Agents.” arXiv:2504.07164, 2025.
[15] Carlos E. Jimenez, John Yang, et al. “SWE-bench: Can Language Models Resolve Real-World GitHub Issues?” arXiv:2310.06770, 2024.
[16] Xirui Li, Ming Li, et al. “ClawEnvKit: Automatic Environment Generation for Claw-like Agents.” arXiv:2604.18543, 2026.
[17] Ziyang Luo, et al. “MCP-Universe: Benchmarking Large Language Models with Real-World Model Context Protocol Servers.” arXiv:2508.14704, 2025.
[18] NovaSky-AI (Berkeley Sky Computing Lab). “SkyRL: A Modular Full-stack RL Library for LLMs.” GitHub, 2025.
[19] Jiayi Pan, Xingyao Wang, et al. “Training Software Engineering Agents and Verifiers with SWE-Gym.” arXiv:2412.21139, 2024.
[20] Shishir G. Patil, et al. “The Berkeley Function Calling Leaderboard (BFCL): From Tool Use to Agentic Evaluation of Large Language Models.” ICML / arXiv:2501.14249, 2025.
[21] Xiaoshuai Song, Haofei Chang, et al. “EnvScaler: Scaling Tool-Interactive Environments for LLM Agent via Programmatic Synthesis.” arXiv:2601.05808, 2026.
[22] The Terminal-Bench Team. “Terminal-Bench: A Benchmark for AI Agents in Terminal Environments.” 2025.
[23] verl-project. “verl / HybridFlow: A Flexible and Efficient RL Post-Training Framework.” GitHub.
[24] Zhaoyang Wang, Canwen Xu, et al. “Agent World Model: Infinity Synthetic Environments for Agentic Reinforcement Learning.” ICML / arXiv:2602.10090, 2026.
[25] Minrui Xu, Zilin Wang, et al. “EnvFactory: Scaling Tool-Use Agents via Executable Environments Synthesis and Robust RL.” arXiv:2605.18703, 2026.
[26] John Yang, Kilian Lieret, et al. “SWE-smith: Scaling Data for Software Engineering Agents.” arXiv:2504.21798, 2025.
[27] Shunyu Yao, Noah Shinn, et al. “τ-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains.” arXiv:2406.12045, 2024.