我从 RL 与 Agentic RL 面试题里学到的东西(中文版)
目录
Part I — 基础与问题设定
- §1 什么是 post-training,以及整条 recipe map
- §2 RL 背景与数学工具箱
- §3 算法家族:value-based、policy-gradient、actor-critic
Part II — Reward 与 Preference
- §4 Preference 与 reward modeling
- §5 可验证 reward、正则化与 reward hacking
- §6 Rejection sampling 与 on-policy distillation
Part III — Policy Optimization Algorithms
Part IV — Reasoning、Test-Time Scaling 与 Evaluation
Part V — Agentic RL
- §13 从 single-turn RLHF 到 multi-turn agentic RL
- §14 环境瓶颈,以及 difficulty ≠ trainability
- §15 Agent safety:verifier 不是唯一攻击面
Part VI — RL Infrastructure & Systems
这是一篇围绕 LLM post-training 与 agents 的 RL 复习指南:从 policy gradient、PPO/GRPO/DPO,到 reasoning / RLVR、agentic RL,以及真正大规模训练这些模型所需的系统栈。它不是 classical RL 教科书,也不是“所有 RL 的综述”;它是一份由 2026 年 RL 面试题集驱动、围绕现代 LLM post-training 实战栈组织的学习指南。
全篇用一个 mental model 串起来:
Reward 定义目标;optimization 限制你追目标的速度;exploration 决定你能发现什么;environment 提供经验;systems 让它跑得快;consistency 防止它炸掉。
等价地,记住这条栈:
Reward → Optimization → Exploration → Environment → Systems Consistency
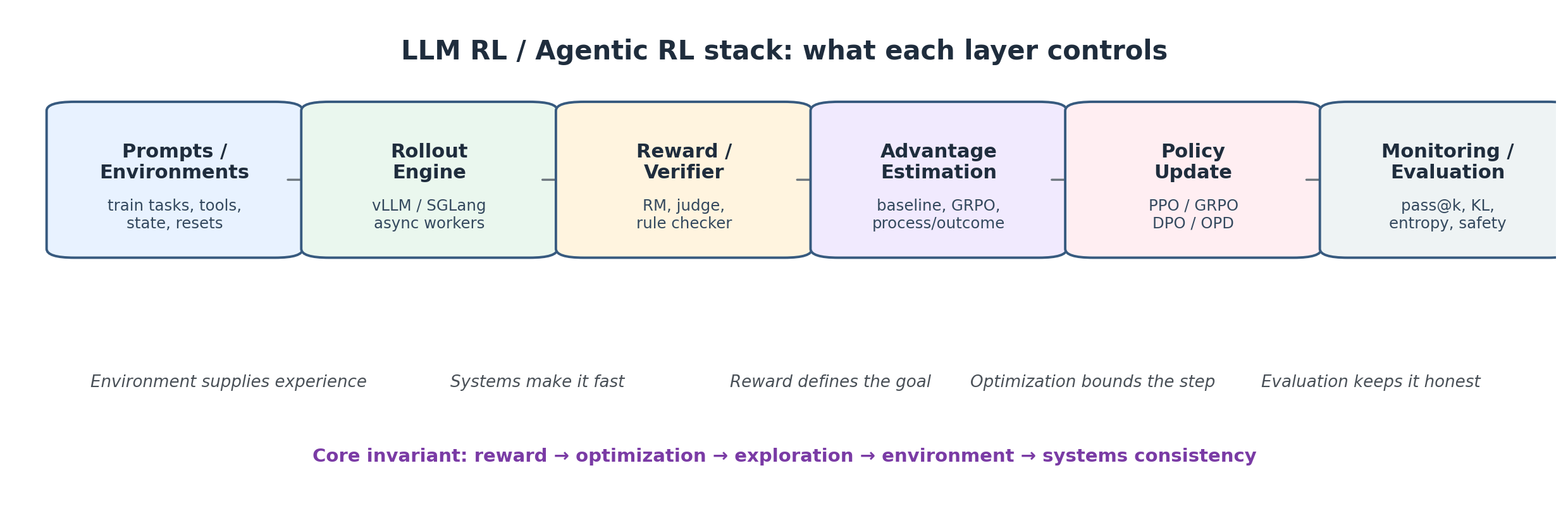 一个实用的 stack 视角:reward 定义目标,optimization 限制更新,environment 产生经验,systems 让 rollout 高效,monitoring/evaluation 让整条 loop 保持诚实。
一个实用的 stack 视角:reward 定义目标,optimization 限制更新,environment 产生经验,systems 让 rollout 高效,monitoring/evaluation 让整条 loop 保持诚实。
如果只记住五件事:
- LLM 的 RL 本质上是在生成 token 和 trajectory 上做 policy-gradient。
- Reward/verifier 同时定义了目标,也定义了攻击面。
- GRPO 用 group-relative baseline 去掉了 critic。
- RLVR 大多是把 latent capability 变成更可靠的行为;除非 exploration 被维持得足够久,否则它很难扩展边界。
- Agentic RL 的瓶颈不只是算法,还有 environment、evaluation、safety 和 rollout systems。
怎么读。 快速读法: 读每节的 Key concepts 加上每道题开头的 🎯 一句话答案。深读法: 读完整解答与公式推导。数学只保留你必须能推导的少数对象。每个非平凡结论都给出 primary source,见 References。原始面试题清单见 Appendix。
Reading paths.
- Interview path: §1–3、§7–9、§12–15、§19、Appendix。
- Reasoning / RLVR path: §1、§5、§8、§10–12、§14。
- Agentic RL path: §13–15,然后 §16–18 看系统部分。
- Systems path: §8、§16–18。
Part I — 基础与问题设定
§1 — 什么是 post-training,以及整条 recipe map
Key concepts.
现代 chat / reasoning model 分两步构建。Pre-training 通过大规模 next-token prediction 学到一个 base model——知识面广,但还不能可靠地遵循指令,也没有对 helpful、honest 答案的偏好。Post-training 把这个 base model 变成可用的模型。它是一条按大致顺序执行的 recipe(Ouyang et al., 2022; Lambert, 2026):
- Instruction tuning / SFT —— 在 (instruction, response) pair 上做监督微调,让模型遵循指令、形成格式/语气(Wei et al., 2021)。
- Reward modeling —— 在 human preference pair 上训练 reward model (RM) 来给回答打分(§4)。
- Rejection sampling —— 采样若干回答,用 RM 选最好的,再在其上微调(§6)。
- Reinforcement learning —— 用 PPO/GRPO 针对 reward 信号优化 policy(§7–§8)。
- On-policy distillation / direct alignment —— 更便宜的信号来源:在学生自己的 rollout 上蒸馏一个 teacher(§6),或用 DPO 完全跳过 RM/RL loop(§9)。
贯穿其中的有两种 reward regime。RLHF(RL from human feedback)用一个 learned reward model 作为人类偏好的代理——灵活,但可被 hack。RLVR(RL from verifiable rewards)把 RM 换成程序化检查器——“数学答案对不对?”“单元测试过没过?”——这远更难被 game,也是 reasoning model 的基础(DeepSeek-AI, 2025;这个词由 Tülu 3 推广,Lambert et al., 2024)。
Question: 走一遍标准 post-training pipeline——每一步到底学到了什么?
🎯 SFT 学格式与 instruction-following;reward model 学人类偏好;rejection sampling 和 RL 把 policy 推向更高 reward 的行为;direct-alignment/distillation 是注入同样偏好信号的更便宜方式。
每一步在补不同的缺口。SFT 让模型以正确形态回答(遵循指令、在该停的地方停下),但它只能模仿 demonstration——永远学不到在多个有效答案中哪个更好。reward model 从人类比较中捕捉这种相对偏好。RL(或 rejection sampling)随后优化 policy,使其产生 reward 偏好的回答,并在 demonstration 集之外探索。Direct alignment (DPO) 和 on-policy distillation 是无需搭建完整 online RL loop、也能传递偏好/teacher 信号的替代方式。实践中大家会混用——例如 SFT → DPO 做便宜对齐,再在有 verifiable reward 的地方做 GRPO/RLVR。
Question: RLHF vs RLVR——什么时候不需要 reward model?
🎯 当 reward 可验证时。如果正确性能被程序化检查(math、code、format),就直接用那个检查器(RLVR),跳过 learned RM,这样还顺带去掉了一整类失败模式(reward-model hacking)。
当“好不好”是主观的(helpfulness、tone、safety),就需要 learned RM,因为没有程序能给它打分。但对于有 ground-truth 检查的任务(数学答案、通过测试、格式 regex),verifiable reward 比 learned RM 更便宜、往往也更稳健,因为它去掉了 reward-model overoptimization(DeepSeek-AI, 2025)。但 verifier 本身依然是攻击面:弱测试、浅 regex、泄漏环境都可能被 exploit。代价是 verifiable reward 通常稀疏且二值(对/错),这正是为什么 exploration 和 difficulty-vs-trainability(§14)在 RLVR 里变得核心。
Question (added): 在切到 RL/GRPO 之前,SFT 要做到什么程度?
🎯 足够的 SFT 意味着模型能可靠地以正确格式产生可评分的 rollout,且在 verifier 下既有成功也有失败。一旦 rollout 大多可解析、reward 有方差,就该切到 RL;更多 SFT 不会自动更好,因为它把模型拉向一个固定外部分布、可能削弱 exploration。
RL 之前 SFT 的目的是 bootstrapping,不是追求完美。它应教会模型任务格式、tool/API 语法、停止行为和基本 instruction-following,使 RL 的 rollout 不至于全部无效。一个实用的 readiness checklist:
- Format validity: 大多数输出可解析 / 可执行 / tool-call 合法。
- Verifier coverage: reward 能给大多数 rollout 打分,不会频繁崩溃或返回歧义结果。
- Reward variance: 模型既有成功也有失败;全错意味着 RL 没有有用梯度,全对意味着任务已被解决(§14)。
- Exploration still exists: 采样没有坍缩成狭窄的 SFT 风格;回答长度和解法策略仍有变化。
- No broad regression: SFT 没有明显破坏你需要的相邻能力。
这就是 SFT → RL 交接的分布视角:SFT 把 policy 拉向一个固定的外部目标分布;RL 在模型自己的 rollout 上更新,把概率质量移向 rewarded behavior;OPD 介于两者之间,用 on-policy data 加 dense teacher signal(wh, 2026)。所以交接点是模型已经能产生对 RL 有用的 on-policy data 的时候。过了这个点,额外的 SFT 往往不如 RL 划算,因为它仍在模仿一个数据集,而不是优化任务目标。
Case study — VibeThinker. VibeThinker 的两篇报告把这个交接讲得很具体。VibeThinker-1.5B 把 SFT 定义为 Spectrum Phase:不是选 pass@1 最高的 checkpoint,而是选并融合 pass@K / 解法多样性最高的 specialist checkpoint,给 RL 构造一个宽广的候选空间。随后 RL 是 Signal Phase,用 verifiable reward 放大其中正确的路径(Xu et al., 2025)。VibeThinker-3B 把同样思路扩展成更完整的 pipeline:curriculum SFT、multi-domain RL、Long2Short Math RL、offline self-distillation、Instruct RL(Xu et al., 2026)。对这道 FAQ 的启示是:最适合接 RL 的 SFT checkpoint,不一定是 greedy 最准的那个,而是能给 RL 提供 valid、diverse、learnable rollout distribution 的那个。
Takeaway. Post-training 是一条 recipe——SFT、reward modeling、rejection sampling、RL、direct-alignment/distillation——其中最重要的分叉是 learned reward (RLHF) vs verifiable reward (RLVR)。SFT 应把模型带到 RL 能看到真实学习信号的位置,然后让 RL/GRPO 接手。本文剩余部分主要讲第 4–5 步,以及它们在 agent 场景下如何变化。
§2 — RL 背景与数学工具箱
Key concepts.
RL 把学习建模成 agent 在 马尔可夫决策过程 (MDP) 中行动:在状态 \(s_t\) 采取动作 \(a_t \sim \pi_\theta(\cdot\mid s_t)\),得到 reward \(r_t\),并转移到 \(s_{t+1}\)(Sutton & Barto, 2018)。对 LLM 而言:state 是 prompt 加上已生成的 tokens,action 是下一个 token,policy 就是模型。目标是最大化期望 return \(J(\theta)=\mathbb{E}_{\tau\sim\pi_\theta}[\sum_t \gamma^t r_t]\)。
两个 value function 概括未来:\(V^\pi(s)=\mathbb{E}[\,\text{return}\mid s]\) 和 \(Q^\pi(s,a)=\mathbb{E}[\,\text{return}\mid s,a]\);它们之差是 advantage \(A^\pi(s,a)=Q^\pi(s,a)-V^\pi(s)\)——“这个动作比平均好多少”。policy-gradient theorem(Sutton et al., 2000)给出我们真正使用的梯度 \(\nabla_\theta J=\mathbb{E}[\nabla_\theta\log\pi_\theta(a\mid s)\,A]\),而 GAE 是我们估计 \(A\) 的方式(§7 推导)。
有三个概率工具在 RL 训练里反复出现:
- Cross-entropy、KL、entropy、MLE —— 一个恒等式把它们串起来(见下题)。
- Monte-Carlo estimation —— 用平均样本来近似期望 \(\mathbb{E}_{x\sim p}[f(x)]\);policy-gradient RL 里一切都是对梯度的 Monte-Carlo 估计。
- Importance sampling 和 rejection sampling —— 两种处理“我手上的样本来自错误分布”的方法(见下题)。
Question (Algo-2): cross-entropy、KL divergence、entropy、MLE 之间什么关系?
🎯 一个恒等式:\(\mathrm{CE}(p,q)=H(p)+\mathrm{KL}(p\|q)\)。对 \(q\) 最小化 cross-entropy 或 KL 是同一件事(因为 \(H(p)\) 与 \(q\) 无关);而 maximum-likelihood 训练恰好是最小化 \(\mathrm{KL}(p_{\text{data}}\|p_\theta)\)。
对真分布 \(p\) 与模型 \(q\) 写出来: \(H(p)=-\!\sum_x p\log p,\quad \mathrm{KL}(p\|q)=\sum_x p\log\tfrac{p}{q},\quad \mathrm{CE}(p,q)=-\!\sum_x p\log q.\) 加减一下就得到 \(\mathrm{CE}(p,q)=H(p)+\mathrm{KL}(p\|q)\)。由于 \(H(p)\) 不依赖模型 \(q\),最小化 cross-entropy loss 就是最小化到数据的 KL。而 maximum-likelihood 目标 \(\max_\theta \mathbb{E}_{x\sim p_{\text{data}}}[\log p_\theta(x)]\) 逐项就是 \(\min_\theta \mathrm{KL}(p_{\text{data}}\|p_\theta)\)。所以 next-token pre-training、SFT loss、以及“最小化到数据的 KL”是同一个目标的三种说法。
为什么对 RL 重要。 KL 是非对称的——\(\mathrm{KL}(p\|q)\neq\mathrm{KL}(q\|p)\)——你惩罚哪个方向会改变行为(mode-covering vs mode-seeking)。RLHF 的 KL-to-reference 项(§7)及其 k3 estimator(§8)都是这个工具箱的直接产物。
Question (Algo-4): importance sampling 和 rejection sampling 是什么,在 RL 里怎么用?
🎯 两者都是处理“样本来自错误分布”的 Monte-Carlo 技术。Importance sampling 用概率比重加权 off-policy 样本(用来重用稍旧的 rollout);rejection sampling 通过保留/丢弃样本来匹配目标(用于数据过滤 / best-of-N)。
Importance sampling (IS) 用来自另一分布 \(q\) 的样本估计 \(\mathbb{E}_{x\sim p}[f(x)]\):\(\mathbb{E}_{p}[f]=\mathbb{E}_{q}[\tfrac{p(x)}{q(x)}f(x)]\)。比值 \(w=p/q\) 给每个样本重加权。这正是 PPO/GRPO 里的 \(r_t(\theta)=\pi_\theta/\pi_{\theta_{\text{old}}}\),以及 async RL(§18)里的 staleness 修正——它们让我们重用稍旧 policy 的 rollout。代价是:如果 \(p\) 和 \(q\) 差太远,比值会爆炸、估计方差暴涨——这正是我们要 clip(§7)和约束 staleness(§18)的原因。
Rejection sampling 则是生成候选并接受其中一部分以匹配目标——在 post-training 里就是“采样 N 个回答,保留 reward model 喜欢的那些,再微调”(Touvron et al., 2023)。它是把 reward 变成训练数据的最简单方式,也是 §6 的概念雏形。两者本质都是 Monte-Carlo:用你能采到的样本去估计/塑造目标分布。
Takeaway. RL 是对 policy gradient 的 Monte-Carlo 估计。advantage(\(Q-V\))是我们要估计的对象,importance sampling 让我们以方差为代价重用 off-policy 样本,而 CE/KL/MLE 恒等式是串起 pre-training、SFT 与 RL 中 KL penalty 的那条线。
§3 — 算法家族:value-based、policy-gradient、actor-critic
Key concepts.
Classical RL 有三个家族。Value-based 方法(Q-learning、DQN)学 \(Q(s,a)\) 并贪心行动 \(a=\arg\max_a Q(s,a)\);它们从不显式表示 policy。Policy-gradient 方法直接参数化 policy \(\pi_\theta\) 并上升 \(\nabla_\theta J\)。Actor-critic 保留一个显式 policy(actor),同时学一个 value function(critic)来降低 policy gradient 的方差——这是 PPO 的基础。LLM RL 几乎全在 policy-gradient / actor-critic 世界里,原因见下题。
Question (Algo-1): 为什么用 actor-critic,而不是纯 critic(value-based)方法?
🎯 因为 LLM generation 是一个巨大的、sequence-level、terminal reward 稀疏的决策问题。单步在词表上做 argmax 不是核心问题——核心问题是对长文本轨迹做 bootstrapped Q-learning 既不实际也不稳定。显式 policy 可以直接采样 trajectory;critic(若使用)只是降方差工具。
value-based 方法必须学 \(Q(s,a)\),再通过 Bellman backup 做 bootstrap。对 LLM 来说,单步动作是一个 token,但有意义的动作往往是整段回答或整条 tool trajectory:reward 来在 sequence/episode level,而 state space 是所有可能的 prefix 和 tool observation。这使得 sequence-level 最大化、off-policy bootstrapping 和 long-horizon credit assignment 都很脆弱。policy 绕开了这点:模型本来就输出下一个 token 的分布,所以我们可以采样完整 trajectory,再用 policy gradient 把它们的 log-probability 推高或推低。critic 仍然有用——它提供降方差的 baseline/advantage——但它是 actor 的辅助,不是决策者。这就是 PPO 所基于的 actor-critic 折中。(GRPO 在 §8 更进一步,去掉 critic,用 Monte-Carlo group baseline 替代。)
Common pitfall. “纯 critic”并非到处都错——对小的离散动作空间(游戏、控制),value-based 方法非常好。是随机、sequence-level、terminal reward 稀疏的语言生成让纯 value-based 方法不合适。
Question: value-based vs policy-gradient vs actor-critic——各自在什么时候失效?
🎯 Value-based:在大/连续动作空间失效,且只给出确定性的贪心 policy。纯 policy-gradient:无偏但方差高、样本效率低。Actor-critic:兼顾两者——显式(随机)policy 加降方差 critic——代价是多一个模型,且 critic 有偏会带偏 advantage。
- Value-based(Q-learning/DQN):配 replay 时样本效率高,但 \(\arg\max\) 在大/连续动作上行不通,纯贪心 policy 是确定性的(需要 exploration 或校准采样时很糟)。
- Policy-gradient(REINFORCE):能处理任意动作空间、给出随机 policy,但原始估计方差高、样本饥渴。
- Actor-critic(PPO):critic 的 value 估计提供 baseline 大幅降方差,同时保留显式 policy——实践默认——但你现在要训练并存储一个 critic,有偏 critic 会带偏 advantage。
Takeaway. LLM RL 处在 policy-gradient / actor-critic 世界里,因为语言生成是一个随机、sequence-level、terminal reward 稀疏的决策问题。保留显式 policy;把 critic 当作降方差工具——并注意 GRPO 用 group baseline 替代了它(§8)。
Part II — Reward 与 Preference
§4 — Preference 与 reward modeling
Key concepts.
当“好不好”是主观的,我们没法写出 reward function——只能从人类比较中学一个出来。标准 pipeline 收集 preference pair:对一个 prompt \(x\),人(或 AI)判断回答 \(y_w\) 好于 \(y_l\)。一个 reward model (RM) \(r_\phi(x,y)\)——通常是带一个 scalar head 的 base model——被训练成让偏好的回答得分更高,靠的是 Bradley–Terry 模型(Bradley & Terry, 1952),它说 \(y_w\) 胜过 \(y_l\) 的概率是
\[P(y_w \succ y_l \mid x) = \sigma\!\big(r_\phi(x,y_w) - r_\phi(x,y_l)\big),\]因此 RM 通过最小化 \(-\log\sigma(r_\phi(x,y_w)-r_\phi(x,y_l))\) 训练(Ouyang et al., 2022)。只有差值被学到,所以 reward 的绝对尺度是任意的(这对后面的 normalization 很重要)。
除了 learned scalar RM,现在还常见两种更便宜的偏好来源:
- LLM-as-judge —— 提示一个强模型去比较/打分(Zheng et al., 2023)。便宜、灵活,但有偏。
- Rubric / Constitutional feedback —— 对照一份明确的书面 rubric 或 constitution 打分(Bai et al., 2022),提升一致性与可解释性。
| Reward source | Cost | Strength | Main weakness |
|---|---|---|---|
| Learned scalar RM | medium(收集偏好 + 训练) | dense,推理时快 | overoptimization,distribution shift |
| LLM-as-judge | low | 灵活,无需训练 | position/verbosity/self bias,miscalibration |
| Rubric / constitutional | low–medium | 一致、可审计 | rubric 设计成本 |
| Verifiable checker (§5) | low(若可检查) | 攻击面更小、精确 | 仅限可验证任务;verifier 仍可被 exploit |
Table T3. Reward/verifier 来源与权衡。
Question: reward model 怎么训练,为什么只有分数的差值重要?
🎯 用 preference pair,对分数差值做 Bradley–Terry(logistic)loss 训练;因为 loss 只看到 \(r(y_w)-r(y_l)\),绝对尺度和偏移不可辨识——RM 学的是相对质量,不是绝对分数。
RM 就是把 base transformer 的 LM head 换成单个 scalar 输出。对每个 pair,我们用上面的 logistic loss 把 \(r_\phi(x,y_w)\) 推到高于 \(r_\phi(x,y_l)\)。直接有两个后果:(1) 给所有 reward 加一个常数毫无影响,所以下游 RL 必须用 baseline 或 normalization(这正是 GRPO 在 group 内标准化的原因,§8);(2) RM 只在它被训练的分布上可靠——把 policy 推得离那个分布很远,RM 的分数就变得不可靠,这是 overoptimization 的根源(§5)。
Question: LLM-as-judge 会出什么问题,怎么加固?
🎯 judge 有系统性偏差——position、verbosity、self-preference——而且常常 miscalibrated。加固方式:随机化顺序、参考答案/rubric、用 pairwise 而非 absolute 打分、对照人类标注做 calibration 检查。
Zheng et al., 2023 记录了 LLM judge 偏好第一个选项(position bias)、更长的答案(verbosity bias)、以及同模型家族的输出(self-bias)。实用缓解:交换顺序并平均、强制使用 rubric 或 reference answer、偏好 pairwise 比较 而非 absolute 的 1–10 打分(更稳定)、约束输出格式,并定期测量 judge–human 一致性以了解 judge 的 calibration。还有:在一次 run 内版本化并冻结 judge prompt。如果 judge 在训练中途变了,reward 目标就在移动,reward 曲线就变得不可解释。这些都无法完全消除偏差,所以高风险 RL 尽可能依赖 verifiable reward(§5)。
Takeaway. Reward modeling 通过 Bradley–Terry 把人类偏好转成可训练的分数;它的两个固有局限——尺度任意、只在分布内可靠——直接推动了 normalization(§8)与 verifiable-reward 转向(§5)。
§5 — 可验证 reward、正则化与 reward hacking
Key concepts.
一个 reward 的好坏,取决于它抗被 game 的能力。Reward hacking(又叫 specification gaming)是指 policy 最大化被测到的 reward,却没达成真正想要的目标——一个经典且普遍的 RL 失败模式(Amodei et al., 2016;Skalse et al., 2022)。在 learned RM 下尤其严重:优化得够狠,policy 就会找到 RM 的盲点,于是被测 reward 上升而真实质量下降——reward-model overoptimization,Gao et al., 2023 证明它遵循一条可预测的 scaling 曲线(true reward 先升、到顶,然后随着到 reference 的 KL 增大而下降)。
两种防御:
- Verifiable rewards (RLVR). 凡正确性可检查的地方——数学答案、单元测试、format regex——用检查器而非 RM 打分。这缩小了攻击面,但把攻击面挪到了 verifier 自身(DeepSeek-AI, 2025;Lambert et al., 2024)。
- KL regularization. 惩罚相对一个冻结 reference policy 的偏离,使模型无法漫游进 RM 盲点(§7 的 KL-to-reference)。这约束了终点,用一点 reward 换取留在分布内。
要点:可验证 ≠ 不可 hack。 测试套件可被退化解满足,format reward 可被空洞推理满足,“judge”型 verifier 可被谄媚措辞满足。reward/verifier 才是整个系统真正的攻击面。
Question (Algo-3): 不同 RL 场景该怎么设计 reward?
🎯 让 reward 匹配你真正能验证的东西。任务有 ground truth 时优先用程序化 verifiable reward;只在真正主观的质量上才用 learned RM(或 LLM-judge/rubric);并且永远要针对最便宜的 exploit 来设计,而不只针对预期行为。
设计 reward 时的实用 checklist:
- 可验证吗? Math/code/format ⇒ 用检查器(便宜、稳健)。主观 ⇒ RM 或 rubric。
- dense 还是 sparse? verifiable reward 通常二值/稀疏(对/错),这让 exploration 和 curriculum(§14)成为瓶颈;RM reward 是 dense 的但可被 hack。
- 作弊的最便宜方式是什么? 长但错的答案(length bias)、猜格式、利用 judge 偏差——把这些 shape 掉或过滤掉(DAPO 的 overlong shaping,§8,正是这件事)。
- 多目标? 把 helpfulness + safety + verifiability 混在一起会变成打地鼠;要显式加权并监控每一项。
具体到 agent,reward 跨越 outcome(任务成功了吗?)和 process(中间步骤合法吗?)——outcome reward 更干净但更稀疏;process reward 更 dense,但重新引入了 learned-verifier 攻击面。
Question: 实践中怎么检测 reward hacking?
🎯 盯住那个标志性的背离:被测 reward 持续上升,而 held-out 质量停滞或下降。具体信号——reward 突然跳升、回答长度暴涨、KL-from-reference 飙升,以及对高 reward 样本做定性检查。
因为 overoptimization 是 proxy 与 truth 之间的差距(Gao et al., 2023),你通过同时跟踪两者来检测它:proxy reward(RM/verifier 分数)和一个独立信号(held-out verifiable eval、人工抽查)。可操作的红旗:reward 不连续地阶跃上升(找到了 exploit)、平均生成长度膨胀(length hacking)、KL-to-reference 快速攀升(漂出分布),以及——最便宜也最被低估的——读样本。审计 top-\(k\) 最高 reward 的 rollout(hack 集中于此)和一份随机样本(抓住安静的 regression)。缓解:更强/集成的 verifier、KL 牵引、在 held-out 信号上 early stopping,以及移除被 exploit 的捷径。
Takeaway. reward/verifier 是系统的攻击面。verifiable reward 缩小它,KL regularization 约束漂移,但没有东西是不可 hack 的——持续监控 proxy-vs-truth 的差距。
§6 — Rejection sampling 与 on-policy distillation
Key concepts.
不是每个偏好信号都需要完整的 online RL loop。两种更轻量的技术处在 SFT 与 PPO/GRPO 之间。
Rejection sampling(又叫 best-of-N fine-tuning)。 对每个 prompt 从当前模型采样 \(N\) 个回答,打分(RM 或 verifier),保留最好的,用普通 SFT loss 在其上微调(Touvron et al., 2023)。这是把 reward 转成改进的最简单方式——无 critic、无 clipping、无 importance sampling——而且是一个强而稳定的 baseline。它的局限:它只会模仿当前模型已经能产生的最佳结果,所以无法像 on-policy RL 那样探索得那么远。
On-policy distillation (OPD). 一个 teacher 在学生自己的 rollout 上提供 dense 信号:学生生成一条 trajectory,teacher 对它逐 token 打分/重标(例如以 teacher log-prob 为目标),学生据此蒸馏(Agarwal et al., 2023,generalized knowledge distillation)。关键词是 on-policy:与在固定语料上做 vanilla distillation 不同,学生学会在它实际访问的状态里修正自己的错误,从而弥合了困扰 off-policy distillation 的 train/test 分布差距。
Question (Algo-17): on-policy distillation 相比纯 RL 或纯 SFT 好在哪,用在什么地方?
🎯 它结合了 RL 的 on-policy exploration 与 SFT 的 dense、低方差信号:学生像 RL 那样采样自己的 trajectory,但像 SFT 那样从 teacher 的 per-token 目标学习,而非从稀疏 scalar reward 学习——比 RL 更便宜更稳定,比 off-policy distillation 分布更匹配。
纯 SFT(或 off-policy distillation)在固定一组 trajectory 上训练,所以模型从不练习从自己的错误中恢复——测试时它会漂进数据从未覆盖的状态。纯 RL 解决了分布问题(它是 on-policy 的),但 reward 稀疏且高方差,使它昂贵又难调。OPD 取两者之长:on-policy rollout(正确分布)+ dense teacher signal(低方差)。它对 capability transfer 很有吸引力——把一个大/强 teacher 便宜地蒸馏进一个更小的学生——也可作为 RLVR 的 warm-start 或补充。主要前提是能访问到合适的 teacher(理想情况还有它的 token-level 分布;隐藏 logits 的闭源 API 会限制这一点)。
Question (added): rejection-sampling fine-tuning 和 inference-time best-of-N 有什么区别?
🎯 同一操作,不同位置。Inference-time best-of-N 在测试时花算力并返回最好的样本;rejection-sampling fine-tuning 用 best-of-N 来制造新的训练数据,然后改变模型权重,使未来的样本变好,而不必每次都付测试时成本。
两者都采样 \(N\) 个候选并用 reward/judge/verifier 选择。Best-of-N at inference 是 test-time scaling 方法(§11):权重不变,质量只在这次请求上改善,延迟成本随 \(N\) 增长。Rejection-sampling fine-tuning 是训练数据生成方法:选出好候选,再对其做 SFT。它把选择成本摊进权重,但受限于当前 policy 已能采样到的东西——如果好行为从未出现在那 \(N\) 个候选里,模型就无法仅靠 rejection sampling 学到它。
Takeaway. 在完整 RL 之前(或并行),rejection sampling 与 on-policy distillation 能以一小部分复杂度拿到大部分收益——rejection sampling 靠保留 N 中最佳,OPD 靠在学生自己的 trajectory 上蒸馏 teacher。
Part III — Policy Optimization Algorithms
§7 — PPO 家族与 trust region
Key concepts.
语言模型的 RL 优化一个 policy \(\pi_\theta\)(模型)以最大化期望 reward。主力是 policy gradient:与其对一个无法求导的 reward 求导,我们把那些结果比预期更好的动作的 log-probability 推高。对一条 trajectory \(\tau\),
\[\nabla_\theta J(\theta) \;=\; \mathbb{E}_{\tau \sim \pi_\theta}\!\left[\sum_t \nabla_\theta \log \pi_\theta(a_t \mid s_t)\, \hat{A}_t \right],\]其中 \(\hat{A}_t\) 是 advantage——动作 \(a_t\) 比 policy 在状态 \(s_t\) 的平均好多少。这是 REINFORCE estimator(Williams, 1992),由 policy-gradient theorem(Sutton et al., 2000)变得实用。用 advantage 而非原始 return 是最重要的单个降方差技巧;把它估好正是 GAE(见下文)的工作。
vanilla policy gradient 的问题是步长:一次过大、尺度失衡的更新会把 policy 推到一个连它自己的样本都不再有信息量的区域,训练随之崩溃。Trust-region 方法通过限制每次更新能把 policy 移动多远来解决这点。TRPO(Schulman et al., 2015a)把它写明确——在硬 KL 约束下最大化 reward:
\[\max_\theta\; \mathbb{E}_t\!\left[ r_t(\theta)\, \hat{A}_t \right] \quad \text{s.t.} \quad \mathbb{E}_t\!\left[ \mathrm{KL}\big(\pi_{\theta_{\text{old}}}(\cdot\mid s_t)\,\|\,\pi_\theta(\cdot\mid s_t)\big) \right] \le \delta,\]其中 \(r_t(\theta) = \dfrac{\pi_\theta(a_t \mid s_t)}{\pi_{\theta_{\text{old}}}(a_t \mid s_t)}\) 是让我们能重用稍旧 policy \(\pi_{\theta_{\text{old}}}\) 样本的 importance-sampling ratio。
PPO(Schulman et al., 2017)用一个便宜的 clipped surrogate objective 替换硬约束,用一阶方法近似 trust region:
\[L^{\text{CLIP}}(\theta) \;=\; \mathbb{E}_t\!\left[ \min\!\Big( r_t(\theta)\,\hat{A}_t,\;\; \mathrm{clip}\big(r_t(\theta),\, 1-\epsilon,\, 1+\epsilon\big)\,\hat{A}_t \Big) \right].\]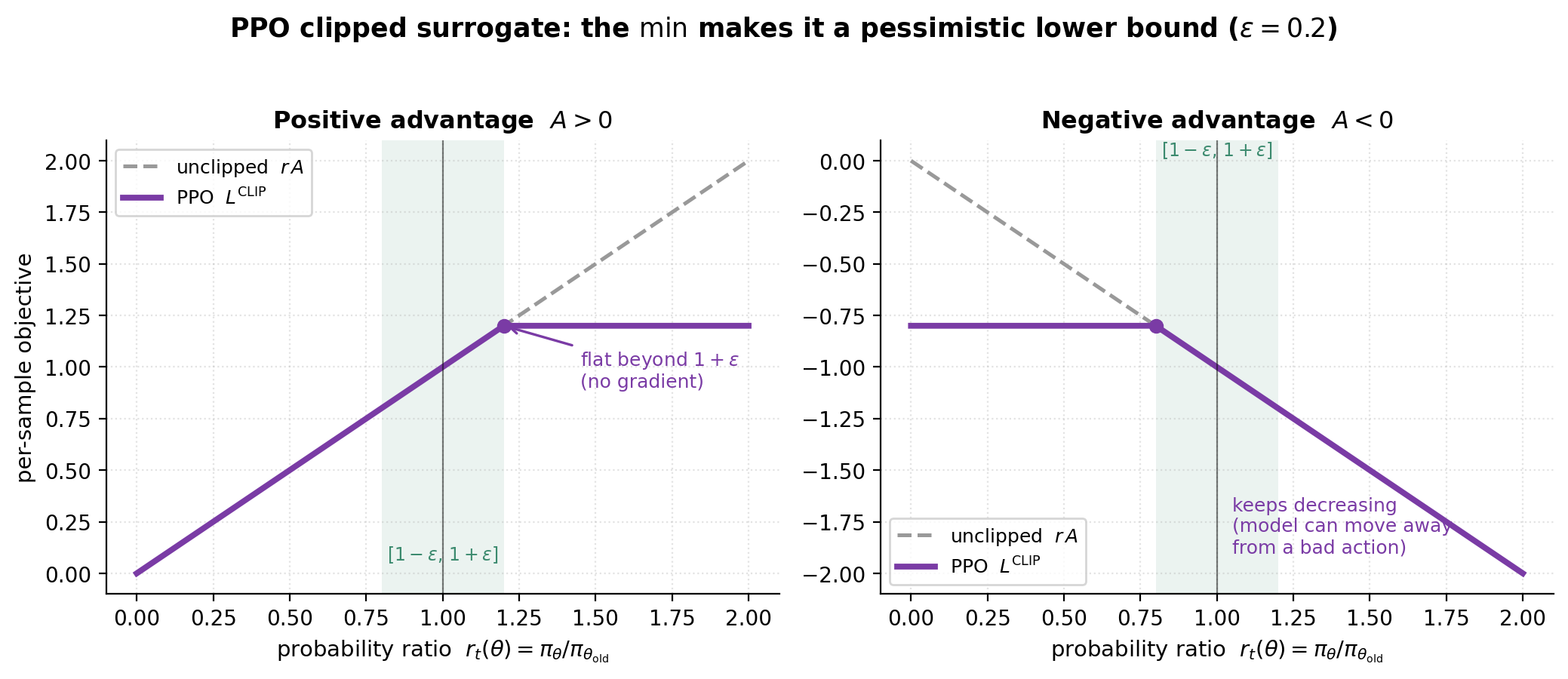 \(A>0\)(左)与 \(A<0\)(右)时的 clipped surrogate。在 \([1-\epsilon,1+\epsilon]\) 之内它跟随未裁剪的 \(rA\);之外,外层 \(\min\) 压平了上行(左),同时仍允许 policy 远离坏动作(右)。正是这种不对称使 \(L^{\text{CLIP}}\) 成为一个悲观下界。
\(A>0\)(左)与 \(A<0\)(右)时的 clipped surrogate。在 \([1-\epsilon,1+\epsilon]\) 之内它跟随未裁剪的 \(rA\);之外,外层 \(\min\) 压平了上行(左),同时仍允许 policy 远离坏动作(右)。正是这种不对称使 \(L^{\text{CLIP}}\) 成为一个悲观下界。
advantage 通常用 Generalized Advantage Estimation 估计(Schulman et al., 2015b):
\[\hat{A}_t^{\mathrm{GAE}(\gamma,\lambda)} = \sum_{l=0}^{\infty} (\gamma\lambda)^l\, \delta_{t+l}, \qquad \delta_t = r_t + \gamma V(s_{t+1}) - V(s_t),\]它在低方差/高偏差(\(\lambda\to 0\))与高方差/低偏差(\(\lambda\to 1\))的 advantage 估计之间插值。
在 RLHF 里,PPO 并不优化原始 reward model 分数。它优化的是 reward model 减去一个到冻结 reference policy 的 KL penalty,这防止模型漂进退化的、reward-hacking 的文本(Stiennon et al., 2020;Ouyang et al., 2022):
\[R(x,y) \;=\; r_\phi(x,y) \;-\; \beta\, \mathrm{KL}\big(\pi_\theta(\cdot\mid x)\,\|\,\pi_{\text{ref}}(\cdot\mid x)\big).\]这套 PPO recipe——actor + critic + reward model + reference model——是经典的 RLHF setup(Lambert, 2026,Policy Gradient 章)。它很强但很吃显存(同时有四个模型);下一节(§8,GRPO)很大程度上是对这个成本的反应。
Question: PPO 的 clipping 到底在防什么,min 从哪来?
🎯 clipping 限制一次更新能把每个 token 的 policy 改变多少;外层 min 让目标成为一个悲观下界,使更新只“信任”落在 clip 范围内的变化。
当 importance ratio \(r_t(\theta)\) 漂离 1 很远时,vanilla policy gradient 会迈出毁灭性的大步——正是 TRPO 的 KL 约束要防的失败(Schulman et al., 2015a)。PPO 不用昂贵的约束优化就近似了那个 trust region。两块在起作用:
-
clip(r, 1-ε, 1+ε)去掉了把 ratio 推到 \([1-\epsilon, 1+\epsilon]\)(通常 \(\epsilon\approx 0.2\))之外的激励:一旦出了这个带,clipped 项就平了,其梯度为零,更新不再推。 - 未裁剪项与 clipped 项之间的外层
min使 surrogate 成为真实目标的下界。这对 advantage 的符号很重要:当 \(\hat{A}_t > 0\) 时它压住了提高概率的上行;当 \(\hat{A}_t < 0\) 时它仍让模型远离坏动作。没有min,单靠 clipping 会让 policy 在负 advantage 样本上过度修正(Schulman et al., 2017)。
不 clip 会怎样? 单个 ratio 漂离 1 很远的 token 会产生一个无界的 \(r_t\hat{A}_t\) 项,所以一个 minibatch 就能迈出巨大、尺度失衡的一步;policy 移进一个它旧样本已 off-distribution 的区域,importance weight 变得不可靠,训练失稳或崩溃。clipping 是对此的便宜防护。
Common pitfall. clipping 约束的是单次更新步长,不是累积漂移。跨多个 epoch,policy 仍可能漂离 \(\pi_{\text{ref}}\) 很远,这正是 RLHF 在 reward 里另外保留一个 KL-to-reference penalty(见上)的原因。clip 和 KL-to-ref 解决不同问题——一个约束步长,一个约束终点。
Question: CISPO 改变了 PPO/GRPO clipping 的什么,为什么?
🎯 PPO/GRPO clipping 一旦 ratio 越过被裁剪的一侧,就会让目标在“提升 reward 的方向”上变平;CISPO 改为裁剪 importance-sampling weight,同时让 log-prob 梯度仍流过每个 token,保住那些罕见但关键的更新。
PPO 式 clipping 的微妙代价在于哪些 token 被裁。在长 chain-of-thought 中,ratio 大的 token 往往是罕见、信息量高的那些——像 “wait”、“but”、“alternatively” 这类反思/分支 token——把它们的梯度清零,恰好丢掉了教会推理的那些更新。CISPO(Clipped IS-weight Policy Optimization),在 MiniMax-M1 (2025) 中提出,保留 REINFORCE 式的项 \(\texttt{sg}(w_t)\,\hat{A}_t\,\nabla_\theta \log \pi_\theta(a_t\mid s_t)\),但裁剪的是 importance-sampling weight \(w_t\)(一个 stop-gradient 乘子),而非裁剪目标本身。因为裁剪落在 weight 上、而非 log-prob 梯度上,所有 token 都继续贡献梯度——trust-region 边界(通过 weight)被保住,同时不让高 ratio 的 token 噤声。MiniMax-M1 报告说这对长 reasoning RL 既更稳定也更样本高效。
If asked in an interview: “PPO 式 clipping 一旦 token 的 ratio 越过被裁的一侧,就会停止那些提升 reward 的更新;CISPO 改裁 IS weight,所以 log-prob 梯度仍在流,只是 weight 有界。”
| Method | What it bounds | How it’s enforced | Effect once outside the clipped side |
|---|---|---|---|
| TRPO (2015a) | KL\((\pi_{\text{old}}|\pi_\theta)\le\delta\) | 硬约束(CG + line search) | n/a(约束步) |
| PPO (2017) | per-token ratio \(\in[1-\epsilon,1+\epsilon]\) | 裁剪目标,取 min | 可能在提升 reward 的方向变平 |
| CISPO (2025) | IS weight \(w_t\) | 裁剪 weight,保留 log-prob 梯度 | 梯度仍在流,只是 weight 有界 |
Question: TRPO vs PPO vs async RL 里的 “staleness bound”——它们怎么是同一个想法?
🎯 三者都在约束采样(behavior)policy 能偏离被更新 policy 多远;区别只在于这个约束如何被强制执行。
- TRPO:用约束优化(conjugate gradient + line search)求解的硬 KL 约束(Schulman et al., 2015a)。最忠实,最贵。
- PPO:通过裁剪 ratio 实现的近似 trust region——一阶、便宜、实践默认(Schulman et al., 2017)。
- Async RL staleness bound:在异步设置里,rollout 由一个已落后 trainer 几步的 policy 生成,所以数据是 off-policy 的。框架约束这个 gap(例如最大 off-policy 步数)并用 importance sampling 修正残差——概念上是同一个“别走太远”的预算,只不过是按墙钟 staleness而非按单次更新来执行(Fu et al., 2025, AReaL)。staleness 在 §18 再讲。
If asked in an interview: “它们都是 trust region。TRPO 精确执行,PPO 通过 clipping 近似执行,async RL 执行一个 staleness 预算加 importance-sampling 修正。”
Question (added — 不在原题集中,但值得知道): 为什么优化 advantage 而非原始 reward/return,GAE 里的 γ 和 λ 各权衡什么?
🎯 减去一个 baseline 来构造 advantage,抵消了梯度中那部分不依赖动作的高方差成分;γ 和 λ 随后在估计它时权衡偏差与方差。
| policy-gradient estimator 对任意状态相关的 baseline \(b(s)\) 都是无偏的:$$\mathbb{E}[\nabla\log\pi_\theta(a | s)\,b(s)] = 0\(。取\)b(s)=V(s)\(得到 advantage\)A = Q - V\(,它比原始 return 方差低得多,因为它衡量的是动作的*相对*质量,而非绝对(且噪声大)的 return([Sutton et al., 2000](https://proceedings.neurips.cc/paper/1999/hash/464d828b85b0bed98e80ade0a5c43b0f-Abstract.html))。GAE([Schulman et al., 2015b](https://arxiv.org/abs/1506.02438))随后把\)A\(估计为 TD residual 的指数加权和:**\)\gamma\(** 对未来 reward 折现(问题定义),而 **\)\lambda\(** 控制估计器的偏差–方差权衡——小\)\lambda\(信任学到的 value function\)V\((低方差,\)V\(错时有偏),大\)\lambda$$ 信任经验 return(高方差,低偏差)。 |
Insight box — “Clip 和 KL 解决不同问题。” PPO clip 约束一步;KL-to-reference 项约束相对 base model 的最终终点。以 reasoning 为主的 RLVR run 常常去掉 KL-to-reference(让 policy 能移得足够远去学新行为),同时保留 clip 来保稳定——见 §5 与 §8。
Takeaway. PPO 是一个近似的 trust region:clip 约束每次更新,GAE 提供低方差 advantage,而(在 RLHF 里)一个单独的 KL-to-reference 项把 policy 锚在 base model 附近。几乎所有后来的 LLM-RL 算法都是这个模板的修改。
§8 — GRPO 与变体动物园
Key concepts.
PPO 最大的实际成本是 critic:第二个网络,大小约等于 policy,必须与之一起训练来估计 advantage 所需的 \(V(s)\)。GRPO(Group Relative Policy Optimization),在 DeepSeekMath(Shao et al., 2024)中提出、被 DeepSeek-R1(DeepSeek-AI, 2025)发扬光大,完全去掉了 critic。思路是:对每个 prompt,采样一组 \(G\) 个回答,打分,并用这组作为自己的 baseline。回答 \(i\) 的 advantage 就是它的 reward 在组内标准化:
\[\hat{A}_{i} \;=\; \frac{r_i - \mathrm{mean}(r_1,\dots,r_G)}{\mathrm{std}(r_1,\dots,r_G)}.\]其余都像 PPO——同样的 clipped ratio——但用这个 group-relative advantage,并(在原始公式里)把 KL-to-reference penalty 直接加到 loss 里,而非折进 reward:
\[\mathcal{J}_{\text{GRPO}}(\theta) = \mathbb{E}\!\left[ \frac{1}{G}\sum_{i=1}^{G} \frac{1}{|o_i|}\sum_{t} \min\!\big(r_{i,t}\hat{A}_i,\ \mathrm{clip}(r_{i,t}, 1\pm\epsilon)\hat{A}_i\big) \;-\; \beta\,\mathbb{D}_{\text{KL}}\!\big[\pi_\theta \,\|\, \pi_{\text{ref}}\big] \right].\]KL 项用低方差、恒正的 k3 estimator(Schulman, 2020): \(\mathbb{D}_{\text{KL}} \approx \tfrac{\pi_{\text{ref}}}{\pi_\theta} - \log\tfrac{\pi_{\text{ref}}}{\pi_\theta} - 1\)。
这笔交易——用一个 Monte-Carlo group baseline 换掉 learned critic——正是 GRPO 成为 RLVR/reasoning 默认选择的原因:它更便宜、更简单,且当你负担得起每个 prompt 多个 rollout 时效果很好。随后的“变体动物园”(Table T1)就是对 GRPO 已知偏差的一系列小修补。
Insight box — “去掉 critic,留下 baseline。” GRPO 的 advantage 就是一个减去 baseline 的 reward;group mean 替代了 value network。成本从第二个模型转移到了额外的 rollout。
| Method | Year | Key change vs GRPO | Known weakness |
|---|---|---|---|
| GRPO (Shao 2024) | 2024 | group-mean baseline,无 critic;KL 在 loss 里 | std/length 偏差(见下) |
| Dr. GRPO (Liu 2025) | 2025 | 去掉 std- 和 length-normalization | 需要仔细的 reward scaling |
| DAPO (Yu 2025) | 2025 | clip-higher、dynamic sampling、token-level loss、overlong shaping;去掉 KL | 超参更多 |
| GSPO (Qwen 2025) | 2025 | sequence-level 的 importance ratio、clipping 与优化 | 每 token credit 更粗 |
| CISPO (MiniMax 2025) | 2025 | 裁剪 IS weight,保留全 token 梯度(见 §7) | weight clipping 调参 |
Table T1. 主要的 GRPO 变体。每个都是对某个特定 GRPO 偏差的针对性修补;更多变体存在,但这四个覆盖了实践中反复出现的想法。
Question (Algo-5): GRPO/PPO 的 advantage 怎么算,为什么减 baseline,一定要除以 std 吗?
🎯 Advantage = reward 减一个 baseline(GRPO 里是 group mean);减 baseline 抵消了梯度中高方差、与动作无关的成分。除以 std 是可选的——它跨 prompt 稳定尺度,但引入一个 difficulty bias,Dr. GRPO 把它去掉了。
baseline 问题与 §7 的一样:对任意状态相关的 \(b(s)\),\(\mathbb{E}[\nabla\log\pi\,b(s)]=0\),所以减去它使梯度无偏但方差更低。GRPO 的妙处在于 baseline 是 Monte-Carlo 的:\(G\) 个采样回答的平均 reward,这正是它无需 critic 的原因。
| ÷std 并非必需。它把每个 prompt 的 advantage 重缩放到单位方差,当 prompt 之间 reward 尺度差异很大时有帮助。但 Liu et al., 2025 (Dr. GRPO) 表明它引入了 difficulty bias:简单 prompt(reward std 低)的 advantage 被放大、困难 prompt 被缩小——再加上 per-response 的长度归一化 $$1/ | o_i | $$ 制造了一个奖励更长错误答案的 length bias。Dr. GRPO 去掉这两个 normalization,报告了更干净的优化。 |
Common pitfall. 当 \(G\) 个回答得到相同 reward 时,\(\mathrm{std}=0\) → 除法爆炸(实现里会加 ε 或跳过该组)。更糟的是,那个 prompt 携带零学习信号(全同 reward ⇒ 零 advantage)——这是 DAPO “dynamic sampling” 与 §14 difficulty-vs-trainability 论点的种子。
Question (Algo-8): GRPO 为什么加 KL 项,怎么算,为什么 DAPO/GSPO 又去掉它?
🎯 KL-to-reference 把 policy 锚在 base model,使 RL 不退化通用能力;它用 k3 estimator 计算。RLVR 规模的 run(DAPO/GSPO)去掉它,因为有了 verifiable reward,这条牵引绳主要是在阻止模型移得足够远去学习。
在 RLHF 里 KL 防止漂进 reward-model 盲点(reward hacking)。但在 RLVR 里 reward 是 verifiable 检查器(math/code 正确性),远更难 hack,所以 KL 牵引绳的主要效果变成拖慢真正新 reasoning 行为的学习。经验上,DAPO 去掉 KL 项、训练得更激进;这在 reasoning RL 里现在很常见。计算: 上面的 k3 estimator 优于朴素的 \(\log(\pi_\theta/\pi_{\text{ref}})\),因为它无偏、恒正、方差更低(Schulman, 2020)。
If asked in an interview: “KL 把你留在 base model 附近——当 reward 是可 hack 的 RM 时必不可少,当 reward 可验证时可有可无。RLVR run 去掉它以更快学习。”
Question (Algo-13): GRPO 的变体(Dr. GRPO、DAPO、GSPO、CISPO …)各修了什么?
🎯 每个都补一个特定的 GRPO 偏差:Dr. GRPO 去掉 std/length normalization 偏差;DAPO 加 clip-higher + dynamic sampling + token-level loss + overlong 处理并去掉 KL;GSPO 把 importance ratio 移到 sequence level 以稳住 MoE;CISPO 裁剪 IS weight 以保留全 token 梯度。
- Dr. GRPO —— 去掉把优化带偏向简单/长答案的 std 和 length normalization(Liu et al., 2025)。
- DAPO —— 四个技巧(Yu et al., 2025):clip-higher(解耦上下 clip \(\epsilon\) 以保 exploration)、dynamic sampling(丢掉所有回答全对或全错的 prompt——无梯度)、token-level policy loss、overlong reward shaping;并去掉 KL。
- GSPO —— Qwen/Alibaba 的 Group Sequence Policy Optimization(Qwen Team, 2025)把 GRPO/PPO 式的 token-level clipping 移到 sequence-level clipping:用 sequence likelihood 定义 importance ratio,让优化粒度与 sequence-level reward 对齐,并报告对大规模 MoE RL post-training(含 Qwen3 改进)有更好的稳定性/效率。
- CISPO —— 裁剪 importance-sampling weight 而非目标,保留每个 token 上的梯度(见 §7;MiniMax, 2025)。
Caveat(给读者)。 这个领域变化很快、新变体每月出现;把每一条都当作“它声称修的那个问题”,在依赖确切 delta 前先核对 primary source。
Question (Algo-12): group size、learning rate、PPO epochs、generation length 怎么设?
🎯 group size 8–16(越大 baseline 越好、算力越多);lr ~1e-6(RL 很敏感);PPO epochs ≈ 1(重用越多 = 越 off-policy = 越不稳);generation length 设到能容纳任务的 reasoning 预算。
| Hyperparameter | Typical | Why |
|---|---|---|
| group size \(G\) | 8–16 | 越大 ⇒ group baseline 方差越低,但 rollout 成本线性增加 |
| learning rate | ~1e-6(policy) | RL 比 SFT 敏感得多;太高 ⇒ collapse |
| PPO epochs | 1(有时 2–4) | 反复重用同一批 rollout 会让数据越来越 off-policy → 不稳 |
| generation length | 视任务而定 | 太短截断 reasoning;太长浪费 rollout 算力并招致 length hacking |
Table T2. 合理的 GRPO 默认值。这是起点,不是定律——按任务核实。
Takeaway. GRPO 用 group-mean baseline 换掉 PPO 的 critic;变体动物园(Dr. GRPO、DAPO、GSPO、CISPO …)是对它 std/length/KL/credit 偏差的一份补丁目录。要知道每个针对的偏差,而不只是名字。
Minimal GRPO runbook.
for prompts in batches:
# 1. Roll out from the behavior policy and SAVE old logprobs.
responses, old_logprobs, policy_mask = rollout(
policy_behavior, prompts, group_size=G
)
# 2. Score each response/trajectory with a verifier or reward model.
rewards = verifier(prompts, responses)
# 3. Compute group-relative advantages per prompt.
adv = rewards - rewards.mean(group="prompt") # std normalization optional
# 4. Recompute logprobs under the train policy.
new_logprobs = policy_train.logprob(prompts, responses)
ratio = exp(new_logprobs - old_logprobs)
# 5. Apply clipped policy-gradient loss only on policy-generated tokens.
loss = -masked_mean(
min(ratio * adv, clip(ratio, 1-eps, 1+eps) * adv),
mask=policy_mask, # mask prompts, tool outputs, and observations
)
# 6. Log what can go wrong.
log(reward=mean(rewards), group_std=std(rewards),
entropy=policy_entropy, clip_fraction=frac_clipped,
length=mean_len, all_pass=all(r == 1 for r in rewards),
all_fail=all(r == 0 for r in rewards))
§9 — Direct alignment:DPO 及相关方法
Key concepts.
PPO/GRPO 是 online 的:从当前 policy 采样、打分、更新。Direct alignment 问的是:我们能否完全跳过 reward model 和采样 loop,直接在一组固定的 preference pair 上优化?DPO(Direct Preference Optimization,Rafailov et al., 2023)证明可以。诀窍是代数性的:KL-regularized 的 RLHF 目标有一个已知的闭式最优解,
\[\pi^*(y\mid x) \;\propto\; \pi_{\text{ref}}(y\mid x)\,\exp\!\Big(\tfrac{1}{\beta} r(x,y)\Big),\]你可以反解它,把 reward 用 policy 写出来: \(r(x,y) = \beta \log \tfrac{\pi_\theta(y\mid x)}{\pi_{\text{ref}}(y\mid x)} + \beta\log Z(x)\)。 把它代入 Bradley–Terry preference likelihood,配分函数 \(Z(x)\) 抵消,剩下一个在 preference pair \((y_w \succ y_l)\) 上的简单监督 loss:
\[\mathcal{L}_{\text{DPO}} = -\,\mathbb{E}_{(x,y_w,y_l)}\!\left[ \log \sigma\!\Big( \beta \log \tfrac{\pi_\theta(y_w\mid x)}{\pi_{\text{ref}}(y_w\mid x)} - \beta \log \tfrac{\pi_\theta(y_l\mid x)}{\pi_{\text{ref}}(y_l\mid x)} \Big) \right].\]所以 DPO 的“reward”是隐式的:量 \(\beta\log(\pi_\theta/\pi_{\text{ref}})\) 就是该 policy 被隐式训练去对抗的 reward——“你的语言模型偷偷是一个 reward model”。没有 RM、没有 rollout、没有 online loop;只是一个对比式的 log-likelihood。正是这种简单性使 DPO 成为便宜、稳定 preference tuning 的默认选择。
Question (Algo-10): DPO 的 reward 是什么,DPO 会被 over-optimize 吗,怎么修?
🎯 DPO 的隐式 reward 是 \(\beta\log(\pi_\theta/\pi_{\text{ref}})\)。它没有显式 RM 可 hack,但固定的 preference 目标仍可被 over-optimize 或 exploit:likelihood displacement、length exploitation、off-distribution drift。修法:保留一个 SFT/NLL anchor、length-normalize、用 on-policy 或 iterative preference data,或用保守变体。
DPO 没有 learned RM 可 game,所以“reward hacking”不太准确。更精确的失败是目标 over-optimization:它只看到一个固定、off-policy 的 preference 数据集。实践中有三件事会出问题:
- Likelihood displacement —— loss 只在乎差距 \(\log\pi(y_w)-\log\pi(y_l)\);它可能在拉大这个差距的同时也降低 \(\pi(y_w)\),只要 \(\pi(y_l)\) 掉得更快。模型可能变得更不可能产生偏好的答案。
- Length / style exploitation —— 如果偏好答案系统性更长,DPO 会学成“更长 = 更好”,而非预期的质量信号。
- Distribution shift —— 因为数据是 off-policy 的,DPO 可能漂到 preference 集从未覆盖的区域并在那里退化。
实践中见到的缓解:在 chosen 回答上加一个 SFT (NLL) regularizer 锚住 \(\pi(y_w)\);length-normalize(如 SimPO);改用 on-policy / iterative DPO(从当前 policy 重新生成 preference);或使用重构的目标——IPO(Azar et al., 2023)抑制 over-optimization,KTO(Ethayarajh et al., 2024)从不成对的 good/bad 标签学习,SimPO(Meng et al., 2024)去掉 reference model 并做 length-normalize。
Question: DPO vs PPO/GRPO——什么时候用哪个?
🎯 有固定 preference 集、想要便宜稳定、无 RM 无 rollout 的调优时用 DPO;有训练期间可查询的 reward 信号(尤其是 verifiable 的)、且需要超出 preference 数据的 exploration 时用 online RL (PPO/GRPO)。
DPO 放弃了 online loop:没有 reward model 要训练/serve、训练时不采样、活动部件少得多——代价是被你起步的 preference 分布困住。PPO/GRPO 保留 online loop,所以能 explore、能用 verifiable reward (RLVR)、能在无人标注的 prompt 上改进——代价是基础设施(rollout engine、显存里更多模型,§16)。一个常见的现代 recipe:SFT → DPO 做便宜对齐,然后在有 verifiable reward 处用 GRPO/RLVR 做 reasoning。
If asked in an interview: “DPO 是带隐式 reward 的 offline preference optimization——便宜稳定但被数据限制;GRPO 是带显式(通常可验证)reward 的 online 方法——更强但更多基础设施。preference 用 DPO,verifiable reasoning 用 RLVR。”
Takeaway. DPO 借助 RLHF 的闭式最优解,把 RM-training + RL 坍缩成一个对比 loss;它的隐式 reward 仍可被 over-optimize,由 SFT-anchor / length-norm / on-policy / IPO-KTO-SimPO 家族来应对。Direct alignment 与 online RL 是互补的,不是竞争对手。
Part IV — Reasoning、Test-Time Scaling 与 Evaluation
§10 — RLVR 与 reasoning
Key concepts.
reasoning model(OpenAI o1、DeepSeek-R1)是 RLVR 的标志性成果:拿一个 base model,给它一个 verifiable reward(数学答案对吗?测试过吗?),跑大规模 RL——于是长 chain-of-thought、self-correction 和“thinking”涌现出来(DeepSeek-AI, 2025)。机制陈述起来很简单:policy 只因最终答案正确而被奖励,而在难题上提高成功率的唯一办法就是生成更长、更谨慎的推理——所以 RL 选择了它。Chain-of-thought 本身(Wei et al., 2022)是基底;RLVR 放大它。
一个核心且争论激烈的问题是 RL 是增加了新能力,还是只磨锐了 base model 已有的能力。证据偏向磨锐:Yue et al., 2025 发现 RLVR 提升 pass@1,但在大 \(k\) 下往往不扩展 pass@k——也就是说 RL 把概率集中到了 base model 本来就偶尔能采到的解上,而非发现真正新的解。这关联到两个相关的 entropy 故事。Entropy collapse 研究 reasoning RL 如何快速降低 policy entropy 并停滞;The Entropy Mechanism of RL for Reasoning LMs 提出 Clip-Cov / KL-Cov 来控制高协方差 token 并保住 exploration(Entropy Mechanism, 2025)。一条互补的线把 entropy 当作 exploration 信号:Reasoning with Exploration 发现高 entropy 区域常与转折点、self-verification/correction 和罕见 reasoning 行为重合,并向 advantage 加入一个裁剪过、梯度分离的 entropy 项,以鼓励探索性推理,而非盲目最大化 policy entropy(Reasoning with Exploration, 2025)。
Question (Algo-18): reasoning 能力在哪个训练阶段出现?
🎯 潜在能力在 pre-training 中奠定;RL post-training (RLVR) 把它唤起并放大。RL 不是从零教数学——它把 base model 的分布重塑成可靠地使用它已经部分拥有的推理。
在大规模文本(含 math、code、解题过程)上 pre-training 给了 base model 原材料——它本来就有时能产出正确的 chain-of-thought。SFT 教格式;RLVR 随后为正确性优化,把模型推向可靠且充分地展开推理。基底已存在的最强证据正是上面的 pass@k 发现(Yue et al., 2025):如果 RL 在创造新能力,pass@k 在大 \(k\) 下会升;大多数情况它不升。所以:pre-training 创造能力,RL 让它可靠。
Question (Algo-15): RL 能扩展 LLM 的能力边界,还是只能磨锐它?
🎯 在当前方法下大多是磨锐——RL 提高已可达解的概率,多过发现新解。延长/curriculum RL 能否真正扩展边界,是一个开放研究问题,有早期正面迹象。
默认发现是“磨锐,不扩展”(Yue et al., 2025)。但这是方法相关的,不是定律:如果 exploration 被维持(entropy regularization、多样化数据、curriculum)且训练跑得够久,有报告称出现了真正的边界扩展——见 §11 的 ProRL 讨论。面试里诚实的答案:在标准的短 GRPO run 下,RL 磨锐;放大、保 exploration 的 RL 能否扩展前沿,尚无定论,是一个活跃方向。
Insight box — “pass@1 升,pass@k 平。” “新能力 vs 磨锐”的最干净判据:如果 RL 只动 pass@1 而不动 pass@k,它就是集中了已有质量,而非发现新解。
Takeaway. RLVR 把可验证的正确性变成涌现的长篇推理,但——在今天的 recipe 下——大多是通过磨锐 base model 已有的分布(pass@1 ↑,pass@k ≈),entropy collapse 是限制因素。
§11 — RL 与 test-time scaling
Key concepts.
有两种截然不同的“花算力换更好答案”的方式。RL(train-time)重塑权重,使模型平均更好。Test-time scaling (TTS) 在固定模型上花更多推理算力——更长的 chain-of-thought、采样多个解并选择(best-of-N、majority vote)、或搜索——以在这个特定 query 上得到更好答案(Muennighoff et al., 2025;OpenAI o1, 2024)。它们互补:RL 抬高曲线,TTS 在推理时沿曲线移动。
它们的 exploration 也不同(Algo-6)。RL 在训练期的权重空间里探索——它采样 trajectory,reward gradient 慢慢把 policy 移向期望 reward 更高的区域;exploration 由 policy entropy 支配,并随 entropy collapse 被耗尽(§10)。TTS 在推理期的输出空间里探索——对一个 prompt 采样多样候选(高温、多 rollout)并选择,权重不变;它的“exploration”受当前分布和推理预算约束。
Question (Algo-6): RL 训练与 test-time scaling 各自如何探索?
🎯 RL 跨训练探索:采样 trajectory 并把 policy 移向高 reward 区域(exploration 受 policy entropy 限制,在许多步上被花掉)。TTS 在推理时探索:为单个 query 抽取许多多样样本并在其中选择(无权重更新,受推理预算和当前模型多样性限制)。
具体说:在 RL 里,exploration 是“在数千次更新上尝试许多 trajectory,保留 reward 喜欢的”——它的货币是训练期 entropy,当 entropy collapse 时模型停止发现新行为。在 TTS 里,exploration 是“对这一道题,想更久,或采 64 个答案取 majority/best”——它的货币是当下的推理算力,且无法超出固定模型已能表达的范围。这就是为什么二者很好地组合:用 RL 把 per-sample 分布做好,再用 TTS 在难 query 上兑现额外推理算力。
Question (Algo-16): 怎么 scale RL 的训练前沿(参考 ProRL)?
🎯 保住 exploration 并训练得久得多。ProRL 式结果表明,配合 entropy 控制、KL reset、多样/curriculum 数据和延长训练,RL 能达到 base model 即便在高 pass@k 下也展现不出的推理——突破“只磨锐”的状态。
ProRL(Liu et al., 2025)认为“RL 只磨锐”的发现部分是短训练的产物。它 scale 前沿的 recipe 是长而稳定的 RL:KL-divergence 控制、周期性 reference-policy / optimizer reset、多样化 verifiable 任务、dynamic sampling、更高的 rollout 温度,以及一个 multi-task verifiable 语料(math、code、STEM、逻辑谜题、instruction following)。关键主张不只是 pass@1 提升:延长 RL 能在某些任务上发现 base model 即便大量采样也达不到的推理策略。论文也给了我们该记住的告诫:效果是任务相关的,某个数学 benchmark 的 pass@1 收益并不自动意味着到处都有 pass@128 或前沿扩展。scale RL 的普遍教训依旧清晰:约束性瓶颈通常是 exploration/diversity,而非原始算力——保住 entropy、需要时 reset reference、喂一份 curriculum(直接关联 §14)。
Question (Algo-19): 从 DeepSeek-R1 到 V3/V3.2/V4——RL 变了什么,MoE RL 有什么不同?
🎯 DeepSeek-R1 让 MoE base 上的大规模 RLVR 可见;V3.2 走向 specialist distillation 加用 GRPO 的混合 RL 与 MoE 专用稳定器;V4 公开看起来把 domain-expert 培养 (SFT+GRPO) 与通过 OPD 的统一模型整合分开。MoE RL 更难,因为 expert routing 让训推一致性与 per-token ratio 变脆。
高层看,R1 在 V3 MoE base 之上展示了用于 reasoning 的大规模 RLVR(DeepSeek-AI, 2025)。V3.2 报告了一套由 specialist distillation + mixed RL training 构成的 post-training recipe:先训练 specialist,再把 reasoning / agent / human-alignment 数据混进一个最终 RL 阶段,仍用 GRPO,以避免多个孤立阶段带来的灾难性遗忘。对 reasoning 和 agent 任务,reward 主要是 rule-based outcome reward 加 length penalty、language-consistency reward 这类 shaping;通用任务用带 per-prompt rubric 的 generative RM。报告的 scaling 稳定器包括 unbiased KL estimate、off-policy sequence masking、Keep Routing、Keep Sampling Mask。Keep Routing 对 MoE RL 尤其相关:它保存 rollout 期间用的 expert routing 并在训练时重用,以减少 router mismatch(DeepSeek-V3.2, 2025)。
V4 应更谨慎地描述。公开材料把它的 post-training 刻画为两阶段 pipeline:先用 SFT + GRPO 培养 domain expert(如 math、coding、agent、instruction following),再用 on-policy distillation (OPD) 借助学生自己的 trajectory 和 teacher 信号把这些能力整合进一个统一学生(DeepSeek, 2026;DeepSeek-V4, 2026;NVIDIA model card, 2026)。安全的说法不是说 V4 用一个全新的 RL 算法取代了 GRPO;而是 expert-stage RL 仍用 GRPO,而最终统一高度依赖 OPD。Reward 公式、KL/clip 超参、rollout batch 设置、完整 teacher 列表,以及许多 OPD 工程细节都未完全公开。
稳健为真的是为什么 MoE 让 RL 更难:
- Routing nondeterminism —— 哪些 expert 触发,在 rollout(推理)引擎与 trainer 之间可能不同,所以同样的 token 得到不同概率 → importance ratio 被破坏(这就是 §18 Algo-11 的 MoE 训推不一致)。
- Token-level ratio noise —— per-token IS ratio 在 routing 下更吵,这促成了 sequence-level importance sampling(GSPO,§8)。
- Expert parallelism —— 分片 expert 给训练系统带来 all-to-all 通信和负载均衡问题(§16)。
Takeaway. RL(权重)与 test-time scaling(推理)是互补的算力杠杆;scale RL 前沿主要是一个 exploration 问题(ProRL);而 MoE 模型把 RL 变成一个 systems 问题,主要通过 routing 引起的训推不一致。
§12 — Evaluation:如何判断 RL 真的有帮助?
Key concepts.
RL 很容易自欺。训练 reward 曲线上升还不够:也许模型找到了 verifier exploit、变长了、过拟合了公开测试,或只在更大的 test-time 预算下才改善。Evaluation 必须分清 training signal、held-out capability、exploration 和 systems health。最干净的问题是:在固定推理预算和 held-out verifier 下,训练后的 policy 是否在不退化别处的前提下解出了更多任务?
所有模型比较都应预算受控:相同 prompt、相同解码设置、相同采样数、相同 tool 限制、相同推理预算。否则你可能在衡量“花了更多 test-time 算力”,而非“模型变好了”。
对 reasoning,永远把 pass@1 与 pass@k / best-of-N / majority vote 分开。pass@1 衡量 policy 在正确解上放了多少概率质量;pass@k 衡量正确解是否存在于模型分布的某处。正是这个区分让你能测试“磨锐 vs 前沿扩展”(§10)。对 agent,还要测 trajectory 属性:success rate、turn count、tool error、side effects、cost per success、environment reset failure。
Question (added): 怎么评估一次 RL run 是改进了模型,还是过拟合了 verifier?
🎯 用一个 held-out、污染受控的 eval,在固定推理预算下;跟踪 pass@1/pass@k、reward、KL/entropy/length,并人工审计 top-reward 与随机样本。如果 reward 上升但 held-out 质量停滞或下降,你优化的是 proxy,不是任务。
一份最小评估协议:
- Capability: held-out pass@1、pass@k、固定采样预算下的 best-of-N / majority-vote。
- Training health: reward 曲线、held-out verifier 分、KL-to-ref、entropy、clip fraction、ratio 分布、回答长度、advantage 分布。
- Data split: 无 train/test 环境泄漏;尽可能用 hidden test;制造训练数据时 generator 拿不到 verifier。
- Agent metrics: task success、average turns、tool-call count、tool error/timeout rate、side-effect rate、cost per success。
- Judge reliability: 若用 LLM-as-judge,冻结 judge prompt、随机化顺序、跟踪 human agreement(§4)。
关键是三角互证。单个指标容易被 hack;当 reward、held-out success、entropy/KL、length、定性审计都讲同一个故事时,一次 run 才令人信服。
Question (added): 真实 GRPO/RLVR run 期间该 log 什么?
🎯 log 到足以诊断 reward hacking、entropy collapse、off-policyness 和 systems 饥饿:reward、KL、entropy、clip fraction、ratio 分布、length、group reward std、all-pass/all-fail rate、rollout throughput、trainer idle time、queue size、staleness,以及 held-out quality。
| Layer | Metrics to log | What they catch |
|---|---|---|
| Policy | reward、KL、entropy、clip fraction、ratio 分布、grad norm | collapse、过大更新、exploration 丢失 |
| Generation | length、truncation rate、tool-call count、timeout rate | overlong hacking、cap 设置不当、tool 不稳 |
| Data | all-pass/all-fail 比例、group reward std、prompt 重复率 | 无学习信号、重复任务 |
| Systems | rollout tokens/s、trainer idle time、queue size、staleness 分布、KV-cache 利用率 | rollout 瓶颈、async 不稳 |
| Quality | held-out pass@1/pass@k、人工抽查、top-reward 审计 | proxy 过拟合、reward hacking |
Takeaway. Evaluation 不是一个排行榜数字。它是一块仪表盘,把 proxy reward 与真实能力、train 与 test、pass@1 与 pass@k、模型质量与系统瓶颈分开。
Part V — Agentic RL
§13 — 从 single-turn RLHF 到 multi-turn agentic RL
Key concepts.
到目前为止一切都假设 single turn:prompt 进、一个 response 出、一个 reward。agent 不同——它在一个环境里跨多步行动:调用 tool、读取结果、决定下一动作、重复,直到任务完成。Agent 的 RL 沿用同样的 policy-gradient 机器,但 episode 现在是一条 trajectory \(\tau=(s_0,a_0,s_1,a_1,\dots)\),其中 action 是 tool call / message,state 包含 tool output。两件事根本改变了:reward 通常是 terminal 且 sparse 的(整个任务成功了吗?),且 credit 必须跨许多步和 token 分配。
LLM agent 特有的一个实践细节:trajectory 把模型生成的 token(action、reasoning)与环境返回的 token(tool output、observation)交织在一起。你必须把 observation token 从 loss 中 mask 掉——模型不应被训练去“预测”环境产生的文本,只训练它自己的 action。把这个 masking 弄错是一个常见而沉默的 bug。
Question: 为什么 multi-turn agentic RL 里 credit assignment 更难,有哪些选择?
🎯 因为一个稀疏的 terminal reward 必须分配到许多步和 token 上,而没有 per-step 监督。选择跨越一个谱:trajectory-level(整个 episode 一个 advantage,简单但高方差)到 step/turn-level(每步一个 value 或 process reward,方差更低但需要 critic 或 process verifier)。
single-turn 情形很简单:reward 附在那一个 response 上。在一条只在最后成功或失败的 30 步 tool-use trajectory 里,哪些步该得 credit?三种常见方法:
- Trajectory-level (outcome) advantage —— 给 trajectory 里每个 token 赋同一个 group-relative advantage(GRPO 式)。简单、只需 verifier、实践中占主导,但高方差且不知道哪一步重要。
- Step/turn-level advantage —— 估计每步的 value(critic)或 shape per-turn reward,以更细的 credit 为代价换取 critic 或更多 reward engineering。
- Process rewards (PRMs) —— 一个 learned/automatic verifier 给中间步骤打分,加密信号——但重新引入 learned-verifier 攻击面(§5),且本身难造。
实践中许多 agentic-RL 系统用 GRPO + terminal verifiable reward + trajectory-level advantage,加上仔细的 loss masking,正是因为它避免了 critic 和 process verifier。
Question: 从 single-turn 到 multi-turn tool use,GRPO 里什么变了?
🎯 机制上几乎没变——同样的 group-relative advantage 和 clipped ratio——但你要 (1) 把 episode 定义成完整的 tool-interleaved trajectory,(2) 把 environment/observation token 从 loss 中 mask 掉,(3) 通常给所有 action token 赋一个 trajectory-level advantage,(4) 处理变长的、长的 trajectory(截断、turn 限制、§17 的 long-tail rollout 问题)。
算法是一样的;难的是簿记。你对每个任务采样一组完整 trajectory,用 terminal verifier 给每条打分,在组内标准化得到 advantage,并只对模型生成的 token 施加它。新的失败模式是运营性的:trajectory 长度差异极大(rollout long-tail,§17),tool call 可能失败或挂起(需要稳健的环境),长 horizon 让 credit assignment 和系统负载(§16–§18)都比 single-turn RLHF 重得多。
Takeaway. Agentic RL 是把 single-turn RL 拉伸到一条 tool-interleaved trajectory 上:同样的 policy-gradient 内核,但稀疏的 terminal reward、跨步的 credit assignment,以及对 environment token 的严格 masking,正是它难的地方。
§14 — 环境:瓶颈,以及 difficulty ≠ trainability
Key concepts.
对 single-turn RLHF,“环境”很简单——给一个 response 打分。对 agent,环境是一个可执行、有状态、可验证的世界,而造出足够多这样的环境才是真正的约束。这个领域的工作假设是:agentic RL 的瓶颈是环境,不是算法——benchmark 给出几百个手工任务(够 evaluate,远不够 train),所以一条快速增长的工作线在大规模合成环境。(本文的姊妹篇 Environment Scaling for Agentic RL 是深入版;这里我们只需要与训练相关的那一个想法。)
那个想法是 difficulty ≠ trainability。一个任务只有在当前 policy 下结果不确定时才产生学习信号。对一个二值 verifiable reward,per-task 方差是 \(p(1-p)\),其中 \(p\) 是 policy 的通过率:
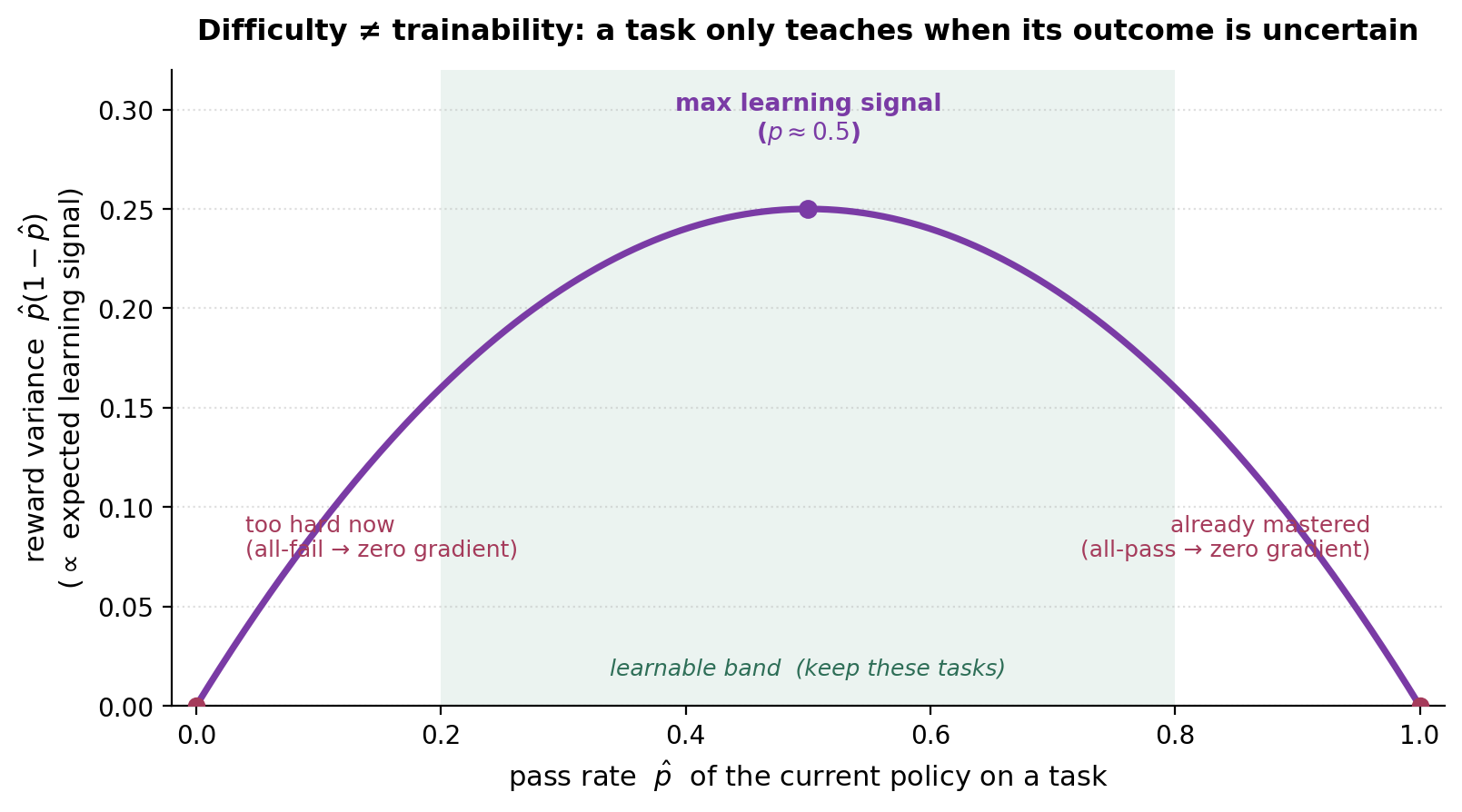 Reward 方差 \(\hat{p}(1-\hat{p})\) 在 \(p\approx0.5\) 时最大、在两端为零。一个模型总是失败(\(p=0\))或总是通过(\(p=1\))的任务,给出零 advantage、零梯度——它当下什么都不教,无论它在绝对意义上多“难”。
Reward 方差 \(\hat{p}(1-\hat{p})\) 在 \(p\approx0.5\) 时最大、在两端为零。一个模型总是失败(\(p=0\))或总是通过(\(p=1\))的任务,给出零 advantage、零梯度——它当下什么都不教,无论它在绝对意义上多“难”。
Question: 为什么人们说 agentic RL “瓶颈是环境,不是算法”?
🎯 因为算法(GRPO/PPO)成熟且应用便宜,但 RL 对 verifiable、interactive 任务很饥渴,而手工 benchmark 又小又只能评估。稀缺资源是大规模、可执行、可验证的环境——所以近期大多数进展都来自生成它们。
一个几百道 coding 或 tool-use 任务的 benchmark 是为衡量模型而造的;RL 烧任务的速度远快于人类能编写的速度,且需要带程序化 verifier 的交互式任务(不只是 input/output pair)。所以真正能撬动指标的杠杆是环境的供给——程序化生成容器化任务并合成它们的 verifier——而非又一次对 loss 的微调。这正是 environment-scaling 文献(姊妹篇)的全部前提。
Question: 为什么最难的任务不是最有用来训练的?
🎯 因为一个你总是失败的任务给出零 reward 方差,因而零 advantage、零梯度——和一个你总是通过的任务一样。学习信号在成功不确定(\(p\approx0.5\))处达到峰值,而非在难度最大处。
这是整条 pipeline 里最反直觉的杠杆。对二值 reward,期望 policy gradient 幅度按 \(p(1-p)\) 缩放:在 \(p=0.5\) 最大,在 \(p\in\{0,1\}\) 为零。一个极难任务(当前通过率 0)和一个平凡任务(通过率 1)此刻同样无用——两者都不给梯度。实际后果:
- 按 learnability 而非 difficulty 过滤 —— 把任务保持在一个“learnable band”(如 \(0.2<p<0.8\)),这正是 DAPO 的 dynamic sampling(丢掉 all-pass/all-fail 的 prompt,§8)。
- Curriculum —— 随着 policy 改进,今天 learnable 的任务变得平凡;难度必须随能力上升,以让 \(p\) 保持在中间(self-evolving environments,姊妹篇)。
Insight box — “按学习信号过滤,而非按原始难度。” 最有用的任务是模型大约对一半的那个——而不是最难的那个。
Case study — MGPO. VibeThinker 的 MaxEnt-Guided Policy Optimization (MGPO) 是这条原则的一个具体版本。对每个 prompt,它采样一组 rollout,估计经验正确率 \(p(q)\),并上调最接近最大不确定性(\(p(q)\approx0.5\))的 prompt 的权重,同时下调 all-pass 或 all-fail 的 prompt。换句话说,它把 learnability band 变成了一个 GRPO 式目标内部的 prompt-level 加权方案(Xu et al., 2025)。这也是为什么 VibeThinker 是一个有用的小模型案例:它把 diversity first, signal second 从哲学变成了可操作的东西。*
一个任务可以 learnable 但仍不安全或无效。 learnable 的任务不自动是好的训练环境;verifier 和 reset 机制也必须可信。
| Dimension | Bad environment | Good environment |
|---|---|---|
| Verifiability | 仅公开测试;浅 regex | hidden/adversarial 测试;state-based verifier |
| Reset | 状态跨 episode 泄漏 | 确定性干净 snapshot |
| Learnability | all-pass 或 all-fail | \(p\) 在 learnable band 内 |
| Diversity | 模板重复 | 组合式变化 |
| Safety | 不受限的 tool 副作用 | 沙箱化、scoped tool |
| Cost | 慢 / 不稳 / 非确定性 | 有界 timeout、可复现执行 |
Takeaway. Agentic RL 的约束性瓶颈是 verifiable interactive 环境的供给,而关键选择原则是 trainability(reward 方差 \(p(1-p)\))而非原始难度——这就是为什么 dynamic sampling 和 curriculum 与 RL 算法同等重要。
§15 — Agent safety:verifier 不是唯一攻击面
Key concepts.
对普通 RLHF,reward hacking 主要是指 exploit 一个 reward model 或 judge。对 agentic RL,攻击面更大:agent 通过 tool 行动、读取不可信的 observation、改变外部状态,且可能从一个本身能被操纵的环境获得 reward。失败可以是 reward hack、verifier hack、tool-use exploit、prompt-injection exploit、sandbox escape,或一个不可逆的副作用。这就是为什么 agent 的训练与部署需要一个安全边界,而不只是更好的 reward。
Agentic RL 的安全最好被当作围绕整个 environment–tool–verifier loop 的约束来处理:scoped credential、sandboxed tool、读/写权限分离、确定性 reset、hidden test、不可逆动作的人工 approval,以及对副作用的显式 logging。verifier 只是其中一个组件;环境的其余部分仍可能泄漏状态或提供捷径。Tool output 应被当作 observation,而非 instruction——这把 prompt injection 与 §13 的 loss-masking 规则联系起来。
| Risk | Example | Mitigation |
|---|---|---|
| Prompt injection | tool 输出说 "ignore your policy" | 隔离不可信 observation;instruction hierarchy |
| Data exfiltration | agent 从文件 / DB 读取 secret | scoped credential;allowlist;redaction |
| Sandbox escape | 生成的代码触及 host/network | 容器、seccomp、网络控制 |
| Irreversible side effects | 删数据、发邮件、下单购买 | human gate;dry-run mode;可逆事务 |
| Verifier hacking | 满足公开测试但没解决任务 | hidden/adversarial 测试;multi-verifier 检查 |
| Environment leakage | 状态跨 episode 持续 | 确定性 reset;干净 snapshot |
Question (added): 怎么防止 agentic RL 学到不安全的 tool-use 行为?
🎯 在训练前、而非训练后约束 action 空间与权限。用 sandboxed/scoped tool、hidden test、确定性 reset、不可逆动作的 human gate,并监控副作用——reward 不能是唯一的安全机制。
安全的设计模式是 least privilege。训练环境应只暴露任务所需的 tool,配 scoped credential、无环境 secret;破坏性 tool 在 dry-run 或 approval 模式运行;tool output 被标为不可信 observation 而非 instruction;每个 episode reset 到干净 snapshot。训练期间,log tool-call count、failed call、timeout rate、side-effect rate,以及任何 permission-denied 事件。如果模型学会通过 exploit 环境而非完成任务来拿 reward,修法不只是 reward shaping——而是收窄或加固环境。
Question (added): reward hacking、verifier hacking 和 benchmark overfitting 有什么区别?
🎯 Reward hacking exploit proxy 目标;verifier hacking exploit 检查器实现;benchmark overfitting exploit 对评估分布的反复暴露。在 agentic RL 里它们常重叠,但缓解方式不同。
- Reward hacking: 模型最大化一个 learned RM,而真实质量下降(§5)。
- Verifier hacking: 模型学到测试、regex、judge 或环境状态的怪癖。
- Benchmark overfitting: 模型被间接训练向公开/易泄漏的 eval 任务。
缓解:独立的 held-out 环境、hidden/adversarial 测试、污染检查、周期性人工审计,以及把训练 generator 与评估 verifier 分开。这是 agentic 版的“别在 test set 上训练”——只不过 test set 是可执行的、更容易意外泄漏。
Takeaway. 在 agentic RL 里,verifier 不是唯一攻击面。Policy 能 exploit tool、状态、权限和 reset 逻辑;安全始于环境设计与 least-privilege tooling,然后用 reward 和 eval 作为额外检查。
Part VI — RL Infrastructure & Systems
§16 — 显存、并行与精度
Key concepts.
一个 GRPO/PPO 训练步会同时在显存里持有模型的若干份拷贝。在一般的 PPO 情形:policy(被训练)、一个 reference policy(用于 KL 项)、一个 reward model、一个 critic——多达四个。GRPO 去掉 critic 和 RM(verifiable reward),剩 policy + reference,再去掉 KL 项也去掉了 reference——这是一个重大的显存节省,也是 RLVR run 常去掉 KL(§8)的原因。除了模型权重,你还要付 optimizer states(Adam 存两个 moment,所以 fp32 下约 2× 参数显存)和 activations。
当单份拷贝放不下时,你就分片 (shard)。各个轴:
- Data parallel / FSDP / ZeRO —— 在 GPU 上对不同数据复制计算;FSDP/ZeRO 把 parameter、gradient、optimizer state 跨 rank 分片并按需聚合(Rajbhandari et al., 2019;Zhao et al., 2023)。
- Tensor parallel (TP) —— 把单个 matmul 跨 GPU 切分(层内)(Shoeybi et al., 2019, Megatron-LM)。
- Pipeline parallel (PP) —— 把层切成 stage 跨 GPU(层间);中等规模会回避它,因为有 pipeline bubble 和复杂性。
- Context parallel (CP) —— 为长 context 把序列跨 GPU 切分。
- Expert parallel (EP) —— 对 MoE,把不同 expert 放到不同 GPU。
Question (Infra-1): 不考虑 CPU offload,GRPO 期间显存里有几个模型,能省多少?
🎯 有 KL 时最多三个:policy + reference +(若 learned-reward)reward model;GRPO 已经去掉了 critic。去掉 KL 项移除 reference model;用 verifiable reward 移除 reward model——所以一个精简的 RLVR-GRPO run 基本只留 policy(加 optimizer state 和推理拷贝)。
给 GRPO run 算账:policy(可训练,+ optimizer state + activation)是大头;一份 reference 拷贝(冻结、只推理)只在 KL penalty 时需要;一个 reward model(冻结)只在 reward 是 learned 时需要。节省杠杆:去掉 KL ⇒ 无 reference model;verifiable reward ⇒ 无 reward model;量化/分片冻结拷贝(reference/RM 只推理,可低精度并分片)。你无法避免的是一份用于 rollout 的 policy serving 拷贝(§17)——在 colocated 设置里它与 trainer 共享权重,在 disaggregated 设置里它是一份单独的、常被量化的副本。
Question (Algo-9): LLM 训练时,如果不小心多 All-Reduce 了几次 loss,会发生什么?
🎯 Data-parallel All-Reduce 把梯度跨 rank 平均;多 reduce 几次 loss/gradient(或求和而非平均)会重缩放有效梯度——例如乘上 world size——这等价于把 learning rate 放大,通常会使训练失稳或发散。
在 data-parallel 训练里,每个 rank 算一个 local gradient,单次 All-Reduce 把它们平均。如果 loss(或其梯度)被多 All-Reduce 一次,或被求和而非取均值,梯度就被乘上一个常数(常是 rank 数)。梯度缩放与缩放 learning rate 完全相同,所以更新变得太大——loss spike、NaN 或沉默发散。这是经典的分布式训练 bug:局部看数学没问题,但有效步长被乘上了 world size。修法是确保 loss 被恰好一次、以正确的均值 reduction 归约(且 gradient-accumulation 归一化匹配)。
Question (Infra-3): INT8 vs FP8——训练用哪个、推理用哪个、为什么?
🎯 训练用 FP8,推理用 INT8。FP8 把 bit 花在浮点指数上,给梯度/激活所需的动态范围;INT8 是定点、在窄范围内精度更高,经过 calibration 后适合推理的 weight/activation。
训练值(梯度、激活)跨越很宽的动态范围,所以你需要指数——FP8(如 E4M3/E5M2)在低精度下保住范围,如今是大模型训练的标准(Peng et al., 2023, FP8-LM)。推理,尤其是 weight 量化,能容忍定点 INT8,因为范围已知、可被 calibrate,而 INT8 在该范围内给更多 mantissa 精度,且硬件支持广。经验法则:FP8 = 范围(训练);INT8 = 范围内精度(推理 serving)。
Question (Infra-10/11): 为什么 expert parallelism 对 MoE 关键,长 context 下 Megatron 和 FSDP 有何不同?
🎯 MoE 把不同 expert 放到不同 GPU (EP);routing 随后需要 all-to-all 通信把每个 token 送到它的 expert,所以 throughput 取决于把 all-to-all 与计算重叠以及 expert 负载均衡。对长 context,FSDP 分片 parameter/optimizer state(简单、按需通信),而 Megatron 用显式 3-D (TP+PP+DP) 并行,再加 context/sequence parallelism 切分序列。
一个 MoE 层每个 token 只激活几个 expert,所以 expert 被跨 GPU 分片(EP)。代价是一次 all-to-all 把 token 路由到其 expert 再送回;throughput 取决于 (1) 把 all-to-all 与计算重叠,(2) 负载均衡(一个热 expert 拖住所有人)。对长 context,activation/KV 显存随序列长度增长,所以你加 context/sequence parallelism;FSDP 保持简单(分片 param/grad/optimizer,按需 all-gather,把通信与计算重叠),而 Megatron 组合显式的 TP × PP × DP(+ CP)以在大规模下获得最大控制。FSDP 更易用;Megatron 以复杂性为代价榨出更多性能。
Takeaway. 知道显存花在哪(policy + optimizer state + 冻结的 reference/RM 拷贝),以及每个并行轴切分什么(data/params:FSDP/ZeRO;matmul:TP;layer:PP;sequence:CP;expert:EP)。最便宜的 RLVR 显存收益是去掉 KL/RM;经典的正确性 bug 是 mis-reduced gradient。
§17 — Rollout engines 与 serving
Key concepts.
在 RL 里瓶颈通常是 generation,而非梯度更新:每一步都需要来自当前 policy 的新 rollout,而 autoregressive decoding 很慢。所以 RL 训练依赖生产级 inference engine。两个想法占主导:
- Continuous batching —— 不等整批结束,scheduler 在 token 级别把完成的序列换出、新序列换入,让 GPU 保持忙碌(Yu et al., 2022, Orca)。
- KV-cache management —— attention KV cache 主导推理显存;你如何存储与重用它决定了 throughput。vLLM 引入 PagedAttention,像虚拟内存一样分页 KV cache 以减少碎片(Kwon et al., 2023);SGLang 引入 RadixAttention,通过 radix tree 在有公共 prefix 的请求间共享 KV(Zheng et al., 2023, SGLang)。
还有一种系统模式是 disaggregated prefill/decode:prefill(compute-bound)和 decode(memory-bandwidth-bound)profile 不同,所以把它们拆到不同 GPU 并在它们之间传输 KV cache 能提升利用率(Zhong et al., 2024, DistServe)。
Question (Infra-5): continuous batching 在 RL 训练里会造成什么问题,vLLM 和 SGLang 有何不同?
🎯 Continuous batching 让一批里的序列在不同时间完成,所以训练步前你必须对齐完成的 trajectory 及其 log-prob——而且生成的 log-prob 可能与 trainer 的不匹配(见 §18)。vLLM 用 PagedAttention 优化 KV 显存;SGLang 用 RadixAttention 优化共享 prefix——两者都加速 rollout,但缓存的东西不同。
在 RL 里你生成一组 trajectory,然后做一次梯度步——所以不同的完成时间意味着 straggler trajectory 拖住整批(下面的 long-tail 问题),且你必须仔细收集每条序列的 token 和 log-prob。两个引擎帮的忙不同:vLLM/PagedAttention 是关于显存的(无 KV 碎片 ⇒ 更大 batch),而 SGLang/RadixAttention 是关于重用的(共享的 prompt prefix 只算一次 ⇒ 当许多 rollout 共享一个 prompt 时极好,正是 RL group-sampling 的情形)。许多 RL stack 用任一作为 trainer 背后的 rollout engine。
Question (Infra-4): RL rollout 的 long-tail 问题是什么,怎么处理?
🎯 一批里少数 trajectory 跑得比其余久得多(长生成、多 tool turn),而同步 trainer 必须等最慢的那个——浪费 GPU。修法:continuous batching、length cap / early truncation,以及异步 rollout,使 trainer 永不为 straggler 阻塞。
一个同步 RL 步只能和它最慢的 rollout 一样快,而生成长度是重尾的(某些题诱发很长的 chain 或很多 tool call)。缓解:continuous batching(回填空出的 slot)、truncation / max-turn limit(截掉尾巴,代价是丢一些信号)、PipelineRL 式的生成与训练重叠,以及——最根本的——asynchronous RL(§18),它把 rollout worker 与 trainer 解耦,使 straggler 不拖住 optimizer。
Question (Infra-6): 怎么看 vLLM/SGLang 的利用率,以及训练里的 KV-cache 利用率?
🎯 跟踪 throughput (tokens/s)、GPU compute 利用率,以及 KV-cache occupancy(在用的 cache block 比例,以及请求被 preempt/evict 的频率)。低 GPU 利用 + 低 KV occupancy ⇒ 你在等待(sync/CPU/scheduling);高 KV occupancy + eviction ⇒ memory-bound,减小 batch 或 context。
引擎暴露 scheduler/cache 指标:throughput (tok/s)、KV-cache occupancy(已用 block / 总数;PagedAttention/RadixAttention 报告它)、running vs waiting/preempted 请求,以及 GPU utilization。诊断:低 GPU 利用通常意味着你瓶颈在计算之外——rollout↔trainer 同步、CPU 工作或 scheduling——而非模型本身慢;高 KV occupancy 且频繁 eviction/preemption 意味着你 memory-bound,应减小 batch size 或 max sequence length。具体到 RL,盯住 trainer 是否在空等 rollout——那种空闲正是 async 框架(§18)瞄准的头号低效。
Takeaway. Generation 是 RL 瓶颈;continuous batching 加 KV-cache 引擎(vLLM 的 PagedAttention 管显存、SGLang 的 RadixAttention 管 prefix 重用)是主要杠杆,而慢 rollout 的 long-tail 正是把系统推向异步的原因。
§18 — Async RL 与训推一致性
Key concepts.
同步 RL 交替“生成一批 → 更新一次”,所以 trainer 在生成期间空转,并等最慢的 rollout(§17)。Asynchronous RL 把 rollout worker(许多推理副本,一直在生成)与 trainer(一直在更新)解耦,由一个 queue 连接。这让两者都忙碌,是现代系统的基础(AReaL Fu et al., 2025;slime,THUDM;verl Sheng et al., 2024;prime-rl)。代价是 off-policyness:rollout 由一个落后 trainer 几步的 policy 产生。
Staleness 量化那个 gap——生成 rollout 的 policy 落后当前 policy 多少次 trainer 更新。有界的 staleness(通常几步)加一个 importance-sampling 修正,让 async 训练接近 on-policy;让它增大,IS ratio 就爆炸、训练失稳(§2、§7)。这与 PPO/TRPO 的“trust region”预算是同一个,只是按墙钟而非按单次更新执行。
第二个更微妙的问题是 training–inference mismatch(训推不一致):rollout engine 与 trainer 对同样的 token 算出不同概率,所以 rollout 生成时用的 log-prob 与 trainer 认为的不匹配——这破坏了 importance ratio。原因:不同 kernel/engine(vLLM vs 训练框架)、量化、reduction 顺序,以及——对 MoE——推理与训练之间不同的 expert routing。修法是让两者数值一致:batch-invariant kernel、匹配的 reduction 顺序、在 trainer 侧重算 log-prob,以及重放推理 router 的 expert 选择(Thinking Machines Lab, 2025)。
Question (Infra-8): 有哪些 async RL 框架,相比同步训练它们解决了什么问题?
🎯 AReaL、slime、verl、prime-rl 等把 rollout 生成与梯度更新解耦,使 trainer 永不为(慢的或掉队的)rollout 空等——解决同步 RL 的 GPU 利用不足和 long-tail 问题,代价是必须被控制的 off-policy staleness。
同步 RL 在生成期间浪费 trainer 的 GPU,且被最慢的 rollout 挟持。Async 框架让一池推理副本持续运行,向 trainer 喂一个 trajectory 流,并让 trainer 持续更新。新的负担是约束 staleness 并用 importance sampling 修正残余 off-policyness——这正是这些框架所 instrument 的。
Question (Infra-14): 什么是 full-async staleness,实际中大概有多 stale?
🎯 Staleness = 生成某个 rollout 的 policy 与当前 policy 之间的 trainer 更新次数。Fully-async run 通常保持很小——量级在 1–4 步——因为更大的 gap 会让 importance-sampling ratio 不可靠、使训练失稳。
在 fully-async 设置里,等一条 trajectory 完成并到达 trainer 时,policy 已经又更新了若干次——那个滞后就是 staleness。实际中它被保持在几步内(且硬上界):IS 修正 \(\pi_\theta/\pi_{\text{behavior}}\) 只有在两个 policy 接近时才良态,所以框架要么给最大 off-policy 步数设上界,要么丢弃/降权过 stale 的样本(Fu et al., 2025)。
Question (Infra-12): 怎么开 determinism,什么是 batch-invariance,什么导致非确定性,atomic-add 能解决吗?
🎯 非确定性主要来自并行 reduction 下浮点的非结合性,其顺序随 batching/scheduling 变化(包括 atomic-add 的累加顺序)。“Batch-invariant” kernel 强制无论 batch size/shape 都用同样的 reduction 顺序,使一个 token 的 logprob 在任何 batch 里都相同。Atomic-add 是原因(累加顺序非确定),不是修法;determinism 需要固定顺序的 reduction,而非更多 atomic。
浮点加法不结合,所以以不同顺序加同样的数会给出略不同的结果。GPU kernel 并行 reduce,顺序取决于 batch size、sequence packing 和 scheduling——所以同一个 token 在不同 batch 里能得到略不同的 logit。Atomic-add 累加是一个来源:它的完成顺序非确定,所以它造成而非修复 run-to-run 方差。补救是用batch-invariant / deterministic kernel 固定 reduction 顺序(并在推理与训练路径之间匹配设置),使 logprob 可复现、训推不一致缩小(Thinking Machines Lab, 2025)。
Question (Algo-11): 有哪些算法处理 MoE 训推不一致,怎么做?
🎯 两个互补修法:(1) 把 importance ratio 移到 sequence level (GSPO),使其对 per-token routing 噪声稳健;(2) 让推理与训练数值一致——在 trainer 侧重放推理引擎的 expert-routing 决策,并用 batch-invariant kernel,使同样的 token 走同样的 expert、得同样的概率。
MoE routing 意味着一个 token 的概率取决于哪些 expert 触发了,而那个选择在 rollout engine 与 trainer 之间可能不同(不同 kernel/scheduling),所以 rollout 携带的 behavior-policy log-prob 与 trainer 的重算不匹配——importance ratio 变错。缓解:GSPO(§8)在 sequence level 计算 importance ratio,比 token-level ratio 对 per-token routing 噪声敏感得多得少;系统侧,重放 router 的 expert 选择 并用 deterministic/batch-invariant kernel,使 routing 和概率对齐(Thinking Machines Lab, 2025)。
Question (Infra-9): 在 partial-rollout 框架里,rollout worker 会保留旧 policy 的 KV cache 吗?
🎯 KV cache 是 request-local 且 policy-version-specific 的。一般不为训练 logprob 重用 stale KV。partial rollout 可以在同一个 behavior policy/version 下继续生成,但 trainer 必须知道保存的 behavior logprob 和 policy version。
KV cache 为一个特定模型状态和 prefix 存储中间的 key/value。如果 policy 变了,该 cache 对新 policy 就不再是忠实缓存。实践中,rollout worker 可以在启动它的同一个 behavior policy 下继续一条部分完成的 trajectory,但训练步应使用保存的 old logprob(或用匹配的 behavior checkpoint 重算它们),并给 trajectory 打上其 policy version 标签。不要用一个 stale cache 假装这条 trajectory 是由当前 train policy 生成的。
Question (Infra-7): 多机多卡 RL 训练里 backprop 怎么做?
🎯 Rollout 是推理;训练是对 policy loss 的普通分布式 backprop。RL 特有的部分是组装 trajectory、logprob、mask、reward 和 advantage;梯度随后像其他 LLM 训练一样按 DP/FSDP/ZeRO/TP/PP 归约或分片。
trainer 收到一批 token 加 mask、old logprob、advantage 和 reward。它在 train policy 下重算 new logprob,构造 clipped policy-gradient loss,只通过 policy 生成的 token 反传,并按所选并行同步梯度:FSDP/ZeRO 做 parameter/optimizer 分片、tensor parallel 做 matmul、pipeline parallel 做 layer、context parallel 做长序列。RL 改变的是数据组装与 loss,不是基本的 backprop 算法。
Question (Infra-16): VeRL / TRL / Unsloth / AReaL / slime——你会选哪个?
🎯 取决于规模与目标:TRL/Unsloth 用于单机 SFT/DPO 和快速实验(Unsloth 做省显存微调);VeRL 作为通用、可扩展的 RL 框架(HybridFlow 设计、强引擎集成);AReaL/slime 用于你确实需要大规模 fully-async RL 加 staleness 控制时。按 (1) sync vs async 需求、(2) 规模、(3) 引擎集成来选。
一份实用决策指南:
- TRL —— Hugging Face 的库;中小规模的 SFT/DPO/PPO 很好,易上手。
- Unsloth —— 显存/throughput 优化的微调(LoRA/QLoRA);单 GPU/单机效率。
- VeRL —— 可扩展的 RLHF/RLVR,带 HybridFlow controller 和 vLLM/SGLang + FSDP/Megatron 后端(Sheng et al., 2024);认真做 RL 的常见默认。
- AReaL —— fully-asynchronous RL,带显式 staleness 控制(Fu et al., 2025)。
- slime(THUDM)—— Megatron 支撑、聚焦 rollout throughput 的 RL 框架。
没有通用最优;按 sync-vs-async、规模,以及你需要哪些推理/训练后端来匹配框架。
Takeaway. Async RL 用同步的简单性换利用率,引入了 staleness(有界 + IS 修正)和 训推不一致(靠数值一致性修复:batch-invariant kernel、重放 routing、trainer 侧 logprob)。对 MoE,GSPO 加 routing replay 是关键杠杆;框架选择取决于 sync/async、规模和后端需求。
§19 — 总结、cheat-sheet 与 further reading
一段话版本。 Post-training 通过一条 recipe——SFT、reward modeling、rejection sampling、RL、direct-alignment/distillation——把 base model 变成有用的模型,其核心分叉是 learned reward (RLHF) vs verifiable reward (RLVR)。RL 内核是 policy-gradient/actor-critic:LLM 需要一个显式 policy 来做随机、sequence-level、terminal reward 稀疏的生成;PPO 通过 clipping 近似 trust region;GRPO 用 group baseline 去掉 critic;DPO 用一个隐式 reward 完全跳过 loop。Reward 是攻击面——verifiable 的缩小它,KL 约束漂移,没有东西不可 hack。Evaluation 告诉你 reward 收益是否变成了真实能力、而非 proxy 过拟合。RLVR 唤起的推理大多已存在于 base model(pass@1 ↑,pass@k ≈),而 exploration/entropy 是限制性资源。Agentic RL 把这一切拉伸到 tool-interleaved trajectory 上,约束性瓶颈变成 credit assignment、环境供给、trainability(reward 方差 \(p(1-p)\))以及围绕 tool 和副作用的安全边界。而在规模上 RL 是一个系统问题:显存(多少份模型拷贝)、生成 throughput(rollout engine),以及 async 训练引入的 off-policyness + 训推不一致。
算法 cheat-sheet.
| Method | One-line | Critic? | Reward | Use when |
|---|---|---|---|---|
| REINFORCE | raw policy gradient | no | any | 教学;很少单独用 |
| PPO | clipped trust region,actor+critic | yes | RM 或 verifiable | 通用 RLHF |
| GRPO | group-mean baseline,无 critic | no | 通常 verifiable | 大规模 RLVR/reasoning |
| Dr. GRPO | GRPO 去 std/length bias | no | verifiable | 更干净的 GRPO |
| DAPO | clip-higher + dynamic sampling + token loss,去 KL | no | verifiable | 激进 reasoning RL |
| GSPO | sequence-level IS ratio | no | verifiable | MoE 稳定性 |
| CISPO | 裁剪 IS weight,保留全 token 梯度 | no | verifiable | long-CoT / MoE |
| DPO | offline preference loss,隐式 reward | no | preference pair | 便宜对齐,无 RM/rollout |
超参默认 (GRPO)。 group size 8–16 · lr ~1e-6 · PPO epochs ≈1 · generation length 视任务。Systems quick-ref. 并行:FSDP/ZeRO (data/params) · TP (matmul) · PP (layer) · CP (sequence) · EP (expert)。Rollout engine:vLLM (PagedAttention, 显存) · SGLang (RadixAttention, prefix 重用)。框架:TRL/Unsloth (小) · VeRL (通用可扩展) · AReaL/slime (大规模 async)。
The mental model. Reward 定义目标;算法限制你追目标的速度;environment 提供经验;systems 让它跑得快;而 consistency(clip、KL、staleness、numerics)防止它炸掉。
Further reading
- Nathan Lambert, RLHF Book —— 经典的按 recipe 组织的参考(rlhfbook.com)。
- wh, SFT, RL, and On-Policy Distillation Through a Distributional Lens —— 关于何时停 SFT、以及为什么 on-policy 数据重要的有用直觉(blog)。
- WeiboAI, VibeThinker-1.5B / 3B —— 把 spectrum-first SFT 和 trainability-weighted RL 落地的紧凑 reasoning model(GitHub,1.5B HF,3B HF)。
- 姊妹篇 Environment Scaling for Agentic RL —— 环境如何被大规模合成。
- 每节的 primary paper 都在正文 inline 链接,并汇总在 References。
- 源题集:“RL Interview Questions 2026”(@sheriyuo;zhihu)。
Living document. 这篇会随时间维护:新问题、citation 和 open problem 会随着它们在面试和论文里出现而加入。欢迎指正。
Open questions (tracked, to expand)
- 保 exploration、延长的 RL 能扩展能力前沿,还是只能磨锐?(§10–§11)
- 长 horizon agent 的 process reward vs outcome reward——什么时候加密 credit 值得多出来的攻击面?(§13)
- 随 policy 改进、为 trainability(保持 \(p\approx0.5\))设计有原则的 curriculum。(§14)
- 在不牺牲 throughput 的前提下消除 MoE 的训推不一致。(§18)
- math/code 之外的 verifiable reward 的正确抽象(开放式、多步、用 tool 的任务)。(§5、§14)
Appendix — The source interview questions
本文按概念组织,但它源自一份具体的面试题集——@sheriyuo 的 “RL Interview Questions 2026”(zhihu 版)。对把本文当面试准备的读者,这里是原始清单加上每题在何处作答的指针。把它当自测 checklist:每题你能在 60 秒内答出吗?
Algorithm
- 为什么用 actor-critic 而非纯 critic? → §3
- KL divergence、cross-entropy、MLE 之间的关系? → §2
- 不同 RL 场景该怎么设计 reward? → §5
- RL 里的 importance sampling / rejection sampling / Monte-Carlo? → §2
- PPO/GRPO 的 advantage 怎么算;为什么减 baseline;一定要除 std 吗? → §8
- RL 训练与 test-time scaling 各自如何探索? → §11
- PPO 怎么 clip;为什么取
min;不 clip 会怎样;CISPO 是什么? → §7 - GRPO 为什么加 KL;怎么算;为什么 DAPO/GSPO 去掉它? → §8(计算也见 §5/§7)
- 不小心多 All-Reduce 几次 loss 会怎样? → §16
- DPO 的隐式 reward 是什么;目标会被 over-optimize 或 exploit 吗;怎么修? → §9
- 处理 MoE 训推不一致的算法及其原理? → §18
- group size / learning rate / PPO epochs / generation length 怎么设? → §8
- Dr.GRPO / DAPO / GSPO / CISPO 如何改进 GRPO,各自缺点? → §8
- TRPO / PPO / AReaL 如何用 trust region 约束 RL objective? → §7(+§18)
- RL 能扩展 LLM 的能力边界吗? → §10
- 怎么 scale RL 的训练前沿(参考 ProRL)? → §11
- on-policy distillation 相比 RL / SFT 好在哪;其应用? → §6
- reasoning 能力在哪个训练阶段涌现? → §10
- 从 DeepSeek-R1 到 V3.2/V4:RL 变化,以及 MoE-RL 有何不同? → §11(+§18)
Infrastructure
- 不考虑 CPU offload,GRPO 期间显存里有几个模型;能省多少? → §16
- 分布式推理:KV-cache 传输与多卡通信优化? → §17
- INT8 vs FP8 权衡;训练 vs 推理各用什么精度? → §16
- RL rollout 的 long-tail 问题是什么;解决方案? → §17
- RL 里 continuous batching 的问题;vLLM vs SGLang? → §17
- 怎么看 vLLM/SGLang 的利用率,以及训练里的 KV-cache 利用率? → §17
- 多机多卡 RL 训练里 backprop 怎么做? → §16(+§18)
- 有哪些 async RL 框架;它们解决了同步训练的什么问题? → §18
- partial-rollout 框架(AReaL 等)会保留前一个 policy 的 KV cache 吗? → §18
- MoE expert parallelism 怎么影响 throughput? → §16
- 长 context 的 compute–communication overlap;Megatron vs FSDP 并行? → §16
- determinism 模式、batch-invariance、什么导致它、atomic-add? → §18
- AReaL 和 slime 对 rollout 瓶颈的理解有何不同? → §18
- 什么是 full-async staleness,实际中大概多大? → §18
- 在 slime / Megatron 支撑的 RL 框架里,高层应理解什么? → §18(框架选择)
- VeRL / TRL / Unsloth / AReaL / slime——你会选哪个? → §18
References
(正文各处的 inline citation 直接链接到来源;这里是汇总列表。)
[1] Ronald J. Williams. “Simple Statistical Gradient-Following Algorithms for Connectionist Reinforcement Learning.” Machine Learning, 1992.
[2] Richard S. Sutton, David McAllester, Satinder Singh, Yishay Mansour. “Policy Gradient Methods for Reinforcement Learning with Function Approximation.” NeurIPS, 2000.
[3] John Schulman, Sergey Levine, Philipp Moritz, Michael I. Jordan, Pieter Abbeel. “Trust Region Policy Optimization.” ICML, 2015. arXiv:1502.05477.
[4] John Schulman, Philipp Moritz, Sergey Levine, Michael I. Jordan, Pieter Abbeel. “High-Dimensional Continuous Control Using Generalized Advantage Estimation.” ICLR, 2016. arXiv:1506.02438.
[5] John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, Oleg Klimov. “Proximal Policy Optimization Algorithms.” arXiv:1707.06347, 2017.
[6] Nisan Stiennon, Long Ouyang, Jeff Wu, et al. “Learning to Summarize from Human Feedback.” NeurIPS, 2020. arXiv:2009.01325.
[7] Long Ouyang, Jeff Wu, Xu Jiang, et al. “Training Language Models to Follow Instructions with Human Feedback” (InstructGPT). NeurIPS, 2022. arXiv:2203.02155.
[8] Nathan Lambert. “Reinforcement Learning from Human Feedback” (RLHF Book). Online, 2026.
[9] Wei Fu, Jiaxuan Gao, Xujie Shen, et al. “AReaL: A Large-Scale Asynchronous Reinforcement Learning System for Language Reasoning.” arXiv:2505.24298, 2025.
[10] MiniMax. “MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention” (introduces CISPO). arXiv:2506.13585, 2025.
[11] Zhihong Shao, Peiyi Wang, Qihao Zhu, et al. “DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models” (introduces GRPO). arXiv:2402.03300, 2024.
[12] DeepSeek-AI. “DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning.” arXiv:2501.12948, 2025.
[13] John Schulman. “Approximating KL Divergence” (the k1/k2/k3 estimators). Blog, 2020.
[14] Zichen Liu, Changyu Chen, Wenjun Li, et al. “Understanding R1-Zero-Like Training: A Critical Perspective” (Dr. GRPO). arXiv:2503.20783, 2025.
[15] Qiying Yu, Zheng Zhang, Ruofei Zhu, et al. “DAPO: An Open-Source LLM Reinforcement Learning System at Scale.” arXiv:2503.14476, 2025.
[16] Qwen Team. “Group Sequence Policy Optimization.” arXiv:2507.18071, 2025.
[17] Rafael Rafailov, Archit Sharma, Eric Mitchell, et al. “Direct Preference Optimization: Your Language Model is Secretly a Reward Model.” NeurIPS, 2023. arXiv:2305.18290.
[18] Mohammad Gheshlaghi Azar, Mark Rowland, Bilal Piot, et al. “A General Theoretical Paradigm to Understand Learning from Human Preferences” (IPO). arXiv:2310.12036, 2023.
[19] Kawin Ethayarajh, Winnie Xu, Niklas Muennighoff, et al. “KTO: Model Alignment as Prospect Theoretic Optimization.” arXiv:2402.01306, 2024.
[20] Yu Meng, Mengzhou Xia, Danqi Chen. “SimPO: Simple Preference Optimization with a Reference-Free Reward.” NeurIPS, 2024. arXiv:2405.14734.
[21] Richard S. Sutton, Andrew G. Barto. “Reinforcement Learning: An Introduction” (2nd ed.). MIT Press, 2018.
[22] Jason Wei, Maarten Bosma, Vincent Y. Zhao, et al. “Finetuned Language Models Are Zero-Shot Learners” (FLAN). ICLR, 2022. arXiv:2109.01652.
[23] Nathan Lambert, Jacob Morrison, Valentina Pyatkin, et al. “Tülu 3: Pushing Frontiers in Open Language Model Post-Training” (popularizes “RLVR”). arXiv:2411.15124, 2024.
[24] Hugo Touvron, Louis Martin, Kevin Stone, et al. “Llama 2: Open Foundation and Fine-Tuned Chat Models” (rejection-sampling fine-tuning). arXiv:2307.09288, 2023.
[25] Ralph A. Bradley, Milton E. Terry. “Rank Analysis of Incomplete Block Designs: I. The Method of Paired Comparisons.” Biometrika, 1952.
[26] Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, et al. “Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena.” NeurIPS, 2023. arXiv:2306.05685.
[27] Yuntao Bai, Saurav Kadavath, Sandipan Kundu, et al. “Constitutional AI: Harmlessness from AI Feedback.” arXiv:2212.08073, 2022.
[28] Dario Amodei, Chris Olah, Jacob Steinhardt, et al. “Concrete Problems in AI Safety.” arXiv:1606.06565, 2016.
[29] Joar Skalse, Nikolaus H. R. Howe, Dmitrii Krasheninnikov, David Krueger. “Defining and Characterizing Reward Hacking.” NeurIPS, 2022. arXiv:2209.13085.
[30] Leo Gao, John Schulman, Jacob Hilton. “Scaling Laws for Reward Model Overoptimization.” ICML, 2023. arXiv:2210.10760.
[31] Rishabh Agarwal, Nino Vieillard, Yongchao Zhou, et al. “On-Policy Distillation of Language Models: Learning from Self-Generated Mistakes” (GKD). ICLR, 2024. arXiv:2306.13649.
[32] Jason Wei, Xuezhi Wang, Dale Schuurmans, et al. “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models.” NeurIPS, 2022. arXiv:2201.11903.
[33] Yang Yue, Zhiqi Chen, Rui Lu, et al. “Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?” arXiv:2504.13837, 2025.
[34] Mingjie Liu, Shizhe Diao, et al. “ProRL: Prolonged Reinforcement Learning Expands Reasoning Boundaries in Large Language Models.” arXiv:2505.24864, 2025.
[35] Daixuan Cheng, Shaohan Huang, Xuekai Zhu, et al. “Reasoning with Exploration: An Entropy Perspective.” arXiv:2506.14758, 2025 / AAAI 2026.
[36] Ganqu Cui, Yuchen Zhang, Jiacheng Chen, et al. “The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models.” arXiv:2505.22617, 2025.
[37] Niklas Muennighoff, Zitong Yang, Weijia Shi, et al. “s1: Simple Test-Time Scaling.” arXiv:2501.19393, 2025.
[38] DeepSeek-AI. “DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models.” arXiv:2512.02556, 2025.
[39] DeepSeek-AI. “DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence.” arXiv:2606.19348, 2026.
[40] DeepSeek. “Transparency Center.” 2026.
[41] NVIDIA NIM. “deepseek-v4-pro Model Card.” 2026.
[42] Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, Yuxiong He. “ZeRO: Memory Optimizations Toward Training Trillion Parameter Models.” SC, 2020. arXiv:1910.02054.
[43] Yanli Zhao, Andrew Gu, Rohan Varma, et al. “PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel.” VLDB, 2023. arXiv:2304.11277.
[44] Mohammad Shoeybi, Mostofa Patwary, Raul Puri, et al. “Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism.” arXiv:1909.08053, 2019.
[45] Houwen Peng, Kan Wu, Yixuan Wei, et al. “FP8-LM: Training FP8 Large Language Models.” arXiv:2310.18313, 2023.
[46] Gyeong-In Yu, Joo Seong Jeong, Geon-Woo Kim, et al. “Orca: A Distributed Serving System for Transformer-Based Generative Models” (continuous batching). OSDI, 2022.
[47] Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, et al. “Efficient Memory Management for Large Language Model Serving with PagedAttention” (vLLM). SOSP, 2023. arXiv:2309.06180.
[48] Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, et al. “SGLang: Efficient Execution of Structured Language Model Programs” (RadixAttention). NeurIPS, 2024. arXiv:2312.07104.
[49] Yinmin Zhong, Shengyu Liu, Junda Chen, et al. “DistServe: Disaggregating Prefill and Decoding for Goodput-optimized LLM Serving.” OSDI, 2024. arXiv:2401.09670.
[50] Guangming Sheng, Chi Zhang, Zilingfeng Ye, et al. “HybridFlow: A Flexible and Efficient RLHF Framework” (verl). EuroSys, 2025. arXiv:2409.19256.
[51] Horace He, Thinking Machines Lab. “Defeating Nondeterminism in LLM Inference.” Blog, 2025.
[52] Sen Xu, Yi Zhou, Wei Wang, et al. “Tiny Model, Big Logic: Diversity-Driven Optimization Elicits Large-Model Reasoning Ability in VibeThinker-1.5B.” arXiv:2511.06221, 2025.
[53] Sen Xu, Shixi Liu, Wei Wang, et al. “VibeThinker-3B: Exploring the Frontier of Verifiable Reasoning in Small Language Models.” arXiv:2606.16140, 2026.