How Frontier Labs Train Large Language Models (中文版)
目录
- 为什么要读这些技术报告?
- 前沿模型的样子
- 数据:真正的护城河
- 预训练:scaling、精度与稳定性
- 后训练(一):SFT、冷启动与蒸馏
- 后训练(二):RL,推理的引擎
- 对齐:有用性、安全与诚实
- 评测:度量这场攀登
- 安全与红队
- 收敛的配方
- 开放挑战
为什么要读这些技术报告?
在深度学习时代的大部分时间里,一个前沿模型究竟是怎么训练出来的一直是业界守口如瓶的秘密:系统卡片里的寥寥数语、一个参数量、一张基准测试表格。你可以读遍每一篇论文,却仍然不知道该如何造出一个。这种情况已经改变了。2024-2026 年间发生了一件了不起的事:一家接一家实验室发布了真正的端到端技术报告——不是吊人胃口的预告,而是数据流水线、架构消融实验、优化器、强化学习配方、奖励设计、评测方法以及安全流程。DeepSeek(V3、V3.2、R1)、Qwen3、Kimi K2 和 k1.5、Meta 的 Llama 3、Google 的 Gemma、Microsoft AI 的 MAI-Thinking-1、Zhipu 的 GLM-4.5、Alibaba、Moonshot、Xiaomi 的 MiMo、Tencent 的 Hunyuan、MiniMax、NVIDIA 的 Nemotron,以及完全开源的 OLMo 2 / Tulu 3——它们合在一起,就是一本无心插柳的教科书。
把它们并排来读,最令人惊讶的不是各家实验室有多么不同,而是它们变得多么趋同。剥去品牌的外衣,几乎每一篇报告走的都是同一条路:
论点。到 2026 年,训练一个前沿 LLM 本质上只有一套配方——一条标准流水线,从数据 → 预训练 → 中期训练 → 后训练(先 SFT 后 RL) → 对齐 → 评测 → 安全。区分各家实验室的不再是骨架;而是一小撮设计选择(如何平衡 mixture-of-experts、用哪种 RL 算法变体、信任哪些奖励、是否使用合成数据、是否蒸馏)以及少数几个在大规模下保持稳定的来之不易的技巧。
本文讲的就是这套配方,逐阶段教学。我们以 Microsoft AI 的 MAI-Thinking-1 报告作为主线,因为它异常坦诚,并且很好地把整件事框定为打造一台“爬山机器”:一个由数据流水线、训练基础设施、RL 环境、评测套件和安全测试构成的一体化系统,它把模型研发变成一个经验性的优化循环。在每个阶段,我们都问同一个问题——MAI 是怎么做的,其他家又是怎么做的?——然后让其他报告彼此印证、相互分歧,偶尔自相矛盾。
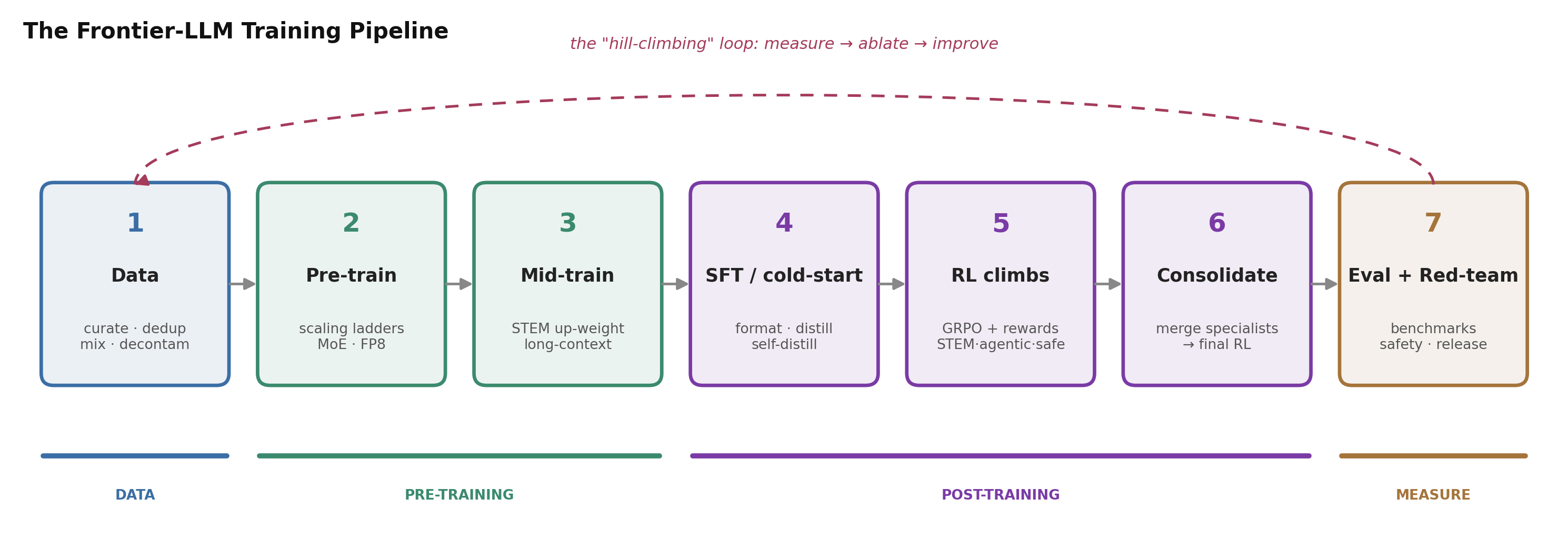 图 1. 本文遵循的这条反复出现的流水线。数据先经过筛选整理,基座模型先预训练、再中期训练,后训练加入 SFT 和若干次 RL”攀登”,并把它们整合成一个模型,所有这一切都由评测和红队来衡量——其结果又反馈给下一轮迭代。本文中的每一家实验室都在实例化这同一副骨架;它们的差别主要在于旋钮的设置。
图 1. 本文遵循的这条反复出现的流水线。数据先经过筛选整理,基座模型先预训练、再中期训练,后训练加入 SFT 和若干次 RL”攀登”,并把它们整合成一个模型,所有这一切都由评测和红队来衡量——其结果又反馈给下一轮迭代。本文中的每一家实验室都在实例化这同一副骨架;它们的差别主要在于旋钮的设置。
关于如何带着怀疑去读这些报告,这里说一句。一篇技术报告同时扮演两个角色。它是一份产品发布公告——所以基准测试表格的选取都是为了好看——同时它又是一份可复现的配方——所以方法部分才是真正信号所在的地方。完全开源的工作(OLMo 2、Tulu 3、Nemotron)会把其他家只能含糊转述的内容如实披露出来,所以每当一篇闭源报告变得含混时,我们就会倚重它们。并且自始至终,请记住一个我们会反复回到的区别:一家实验室声称有用的东西,与它实际做了消融并测量过的东西之间的差别。好的报告大多属于后者。
小结。2024-2026 年的技术报告已经收敛到一套统一的端到端配方;本文逐阶段讲解这套配方,以 MAI-Thinking-1 为主线,以其他实验室作为相互印证的合唱。
前沿模型的样子
在讲流水线之前,先看产物。如果你把 MAI-Thinking-1、DeepSeek-V3、Qwen3、Kimi K2、Llama 3 和 Gemma 3 的配置并排打开,你会惊讶于它们有多么相似。decoder-only Transformer 已经收敛到一个近乎通用的模块,而 2024–2026 年的报告把这个模块当作样板代码——它们的架构章节都花在两件仍然悬而未决的事情上:如何做到稀疏(mixture-of-experts),以及如何让注意力在长上下文下变得廉价。
已经定型的核心
本文中的每一个模型都是 decoder-only Transformer,由同样的五个部件构成,每一个都是在历时数年的比拼中”胜出”的:
- RoPE 负责位置——旋转位置编码刻画的是相对距离,并且能干净地外推,这也是为什么所有模型随后都用 RoPE-base scaling / YaRN 来拉长上下文(Su et al., 2021)。
- GQA 解决 KV-cache 瓶颈——grouped-query attention 只用解码时一小部分的显存,就拿到接近完整注意力的大部分质量(Ainslie et al., 2023)。
- SwiGLU 用于前馈层——一种门控激活,在 FLOPs 固定的情况下白赚一份质量(Shazeer, 2020)。
- RMSNorm 负责归一化——拥有 LayerNorm 的质量却没有其去均值的开销(Zhang & Sennrich, 2019)——如今通常还会搭配 QK-norm(在 query 和 key 上做 RMSNorm)和一个小的 z-loss,一项小规模研究表明,这两个廉价的稳定器能防止会拖垮大规模训练的 attention-logit 与 output-logit 爆炸(Wortsman et al., 2023)。
共识。RoPE + GQA + SwiGLU + RMSNorm + QK-norm 就是现代的 decoder 模块。MAI-Base-1 是它的一个教科书式实例;这里几乎每一个其他基座模型也都是如此。模块层面剩下的旋钮只有norm 的位置(pre-norm,还是 Gemma 和 OLMo 2 的 pre+post / 重排序 norm)以及注意力被稀疏化的激进程度。
大转变:从稠密到 MoE
这个时代真正的架构故事,是从稠密模型迁移到 mixture-of-experts(MoE):用许多个”专家”FFN 取代单个 FFN,并把每个 token 路由到其中的少数几个,于是总参数量(容量,承载知识)便与激活参数量(每个 token 的计算量)解耦了。大家纷纷照搬的那套设计来自 DeepSeekMoE(Dai et al., 2024):两个想法,细粒度专家切分(fine-grained expert segmentation)(把 FFN 切成许多个小专家并激活其中更多的——在 FLOPs 固定的情况下带来组合意义上更多的路由选择)和共享专家隔离(shared-expert isolation)(一个始终开启的专家,用来吸收通用知识,好让被路由的专家能够专精)。DeepSeek 的消融实验很值得引用:禁用共享专家会让 loss 飙升,而细粒度模型在你移除其顶部专家时退化得更厉害——这说明专家确实实现了专精。
到 2026 年,这已是默认做法。DeepSeek-V3 用 1 个共享 + 256 个路由(8 个激活)专家;Kimi K2 把它推到总计 1.04T / 激活 32B、横跨 384 个专家;Qwen3 去掉了共享专家;MAI-Thinking-1 把高稀疏度的 MoE 层与稠密 FFN 层交错排列(并发现这种搭配在实际耗时上胜过处处采用中等稀疏度);Llama 3 则是显眼的稠密派钉子户,明确选择了一个 405B 的稠密模型,”以最大化训练稳定性”。
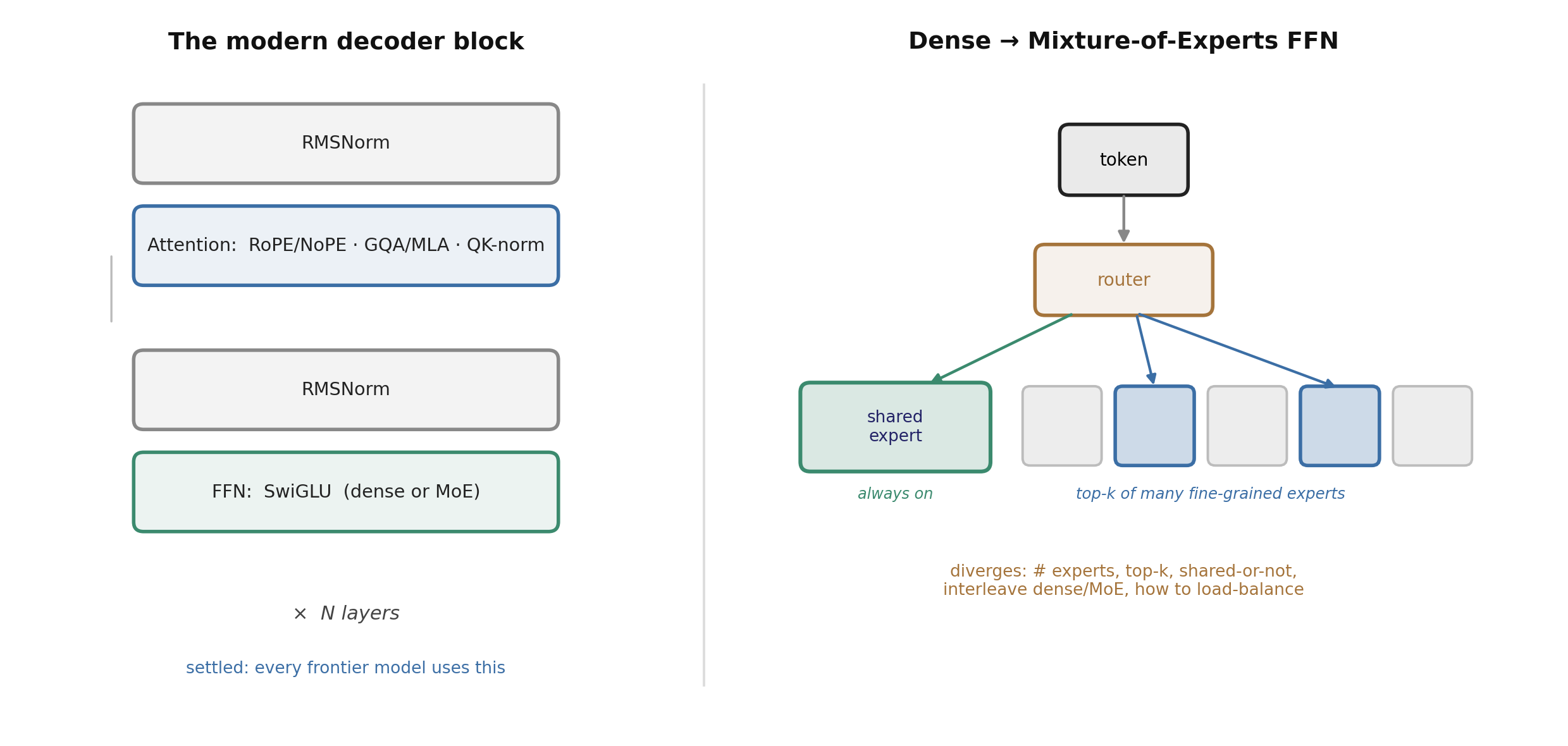 图 2. 已经收敛的 decoder 模块(左)以及从稠密到 MoE 的前馈层转变(右):一个 token 被路由到少数几个细粒度专家,外加一个始终开启的共享专家。各家实验室在专家数量、top-k、是否存在共享专家,以及如何交错排列稠密层与 MoE 层上各有不同。
图 2. 已经收敛的 decoder 模块(左)以及从稠密到 MoE 的前馈层转变(右):一个 token 被路由到少数几个细粒度专家,外加一个始终开启的共享专家。各家实验室在专家数量、top-k、是否存在共享专家,以及如何交错排列稠密层与 MoE 层上各有不同。
各家仍有分歧之处
有两个维度仍然存在真正的争议,而工程上的努力也正集中在这两处。
注意力效率。GQA 是基线,但前沿则是一大堆缩小 KV cache 或二次方开销的花样:DeepSeek 的 Multi-head Latent Attention(MLA)(DeepSeek-V2)把 KV 压缩成一个低秩潜在表示(缓存比 GQA 更小,质量却更好),后来又用 DeepSeek Sparse Attention 加以扩展,使长上下文注意力变为次二次方(DeepSeek-V3.2);Gemma 3 和 MAI 以 5 局部 : 1 全局 的方式交错排列注意力层,于是每六层里只有一层需要付出长程开销;MiniMax-M1 走得最远,用 7:1 的 lightning(线性)注意力 混合方案,让 1M token 上下文——以及廉价的 long-CoT RL——变得负担得起;Hunyuan 把 GQA 与跨层注意力结合,节省约 95% 的 KV;gpt-oss 加入了 attention sinks。MAI 甚至在它的全局层上彻底去掉了位置编码(NoPE),发现这样和 RoPE 一样好却更便宜。到 2026 年,这已成了那场竞赛:稀疏/压缩注意力加上 1M token 上下文 如今已是入场门槛——DeepSeek-V4 推出了 Compressed-Sparse + Heavily-Compressed Attention 混合方案,GLM-5 采用了 DeepSeek 的 DSA(GLM-5.2 还加入了”IndexShare”,把 1M 上下文的 FLOPs 削减约 2.9×),它们追逐的都是同一个目标:让长上下文便宜到足以用来训练 RL,而不只是用来推理部署。
MoE 负载均衡。被路由的专家必须保持均衡,否则训练就会崩溃、GPU 闲置。同一个问题经历了三个时代:最初的辅助损失(auxiliary-loss)(在目标函数里加一个均衡惩罚项——GShard);DeepSeek 的无辅助损失(auxiliary-loss-free)方案(把均衡移出梯度,变成每个专家的路由偏置,质量更好、专精程度也更高,Wang et al., 2024);以及 Qwen 的全局批次聚合(global-batch aggregation)洞见——没人注意到的那个 bug,就是按 micro-batch 来计算均衡损失,这会悄悄毁掉专家的专精(Qiu et al., 2025)。
分歧——在什么范围上做均衡,比怎么均衡更重要。MAI 用的是 GShard 式的损失,但在全局批次上聚合专家的使用频率,并直接给出了结论:”聚合策略远比负载均衡损失的类型更重要。”所以现代的答案与其说关乎损失还是偏置,不如说关乎是否在一个足够多样的 token 群体上做均衡。
最后还有一个值得知道、因为它反复出现的技巧:多 token 预测(multi-token prediction,MTP),即训练模型去预测接下来的若干个 token。DeepSeek-V3 引入它,为的是更密集的训练信号以及白送的约 1.8× 投机解码加速;MiMo 和 Nemotron 也采用了它。最亮眼的优化器故事——Muon 以及 Kimi 的 MuonClip——则属于下一节。
| 维度 | 共识 | 各家分歧之处 |
|---|---|---|
| 位置 | RoPE(+ YaRN/ABF scaling) | 全局层用 NoPE(MAI);注意力中完全不用(Nemotron 的 Mamba) |
| 注意力 | GQA | MLA(DeepSeek、Kimi K2);周期性的局部/全局(Gemma 3、MAI 5:1);lightning/linear(MiniMax 7:1);sparse DSA(DeepSeek-V3.2);sinks(gpt-oss);GQA+CLA(Hunyuan) |
| FFN / Norm | SwiGLU;RMSNorm + QK-norm | pre 还是 pre+post / 重排序 norm(Gemma、OLMo 2);logit soft-cap(Gemma 2) |
| 稀疏性 | 细粒度 + 共享专家 MoE | 稠密(Llama 3);无共享专家(Qwen3);稠密/MoE 交错(MAI);LatentMoE(Nemotron、MAI);Mamba-MoE(Nemotron) |
| 均衡 | 全局批次聚合 | aux-loss → aux-loss-free bias → global-batch |
表 1. 架构已经收敛了约 80%;剩下的旋钮是 MoE 的形态与注意力效率,而这恰恰是每家实验室倾注其聪明才智的地方。
小结。模块已经定型(RoPE/GQA/SwiGLU/RMSNorm/QK-norm);架构上仍在进行的博弈是 mixture-of-experts 的形态 与 廉价的长上下文注意力,在这里有少数几种各不相同的押注(MLA、局部/全局、linear/lightning、sparse)共存。
数据:真正的护城河
如果说架构已经有约 80% 被商品化,那么数据才是模型真正拉开差距的地方——而且并非巧合,这也是每家实验室守口最严的阶段。封闭的报告只给你一个 token 数和一句话(“公开与授权数据的多样化混合”);而完全开放的配方(OLMo 2、Tulu 3、Nemotron)则把整条漏斗都摊开给你看。把它们拼在一起,这条流程出奇地一致:原始爬取数据先经过过滤和去重、规模缩小一个数量级以上,再用一套量化配方重新混合。
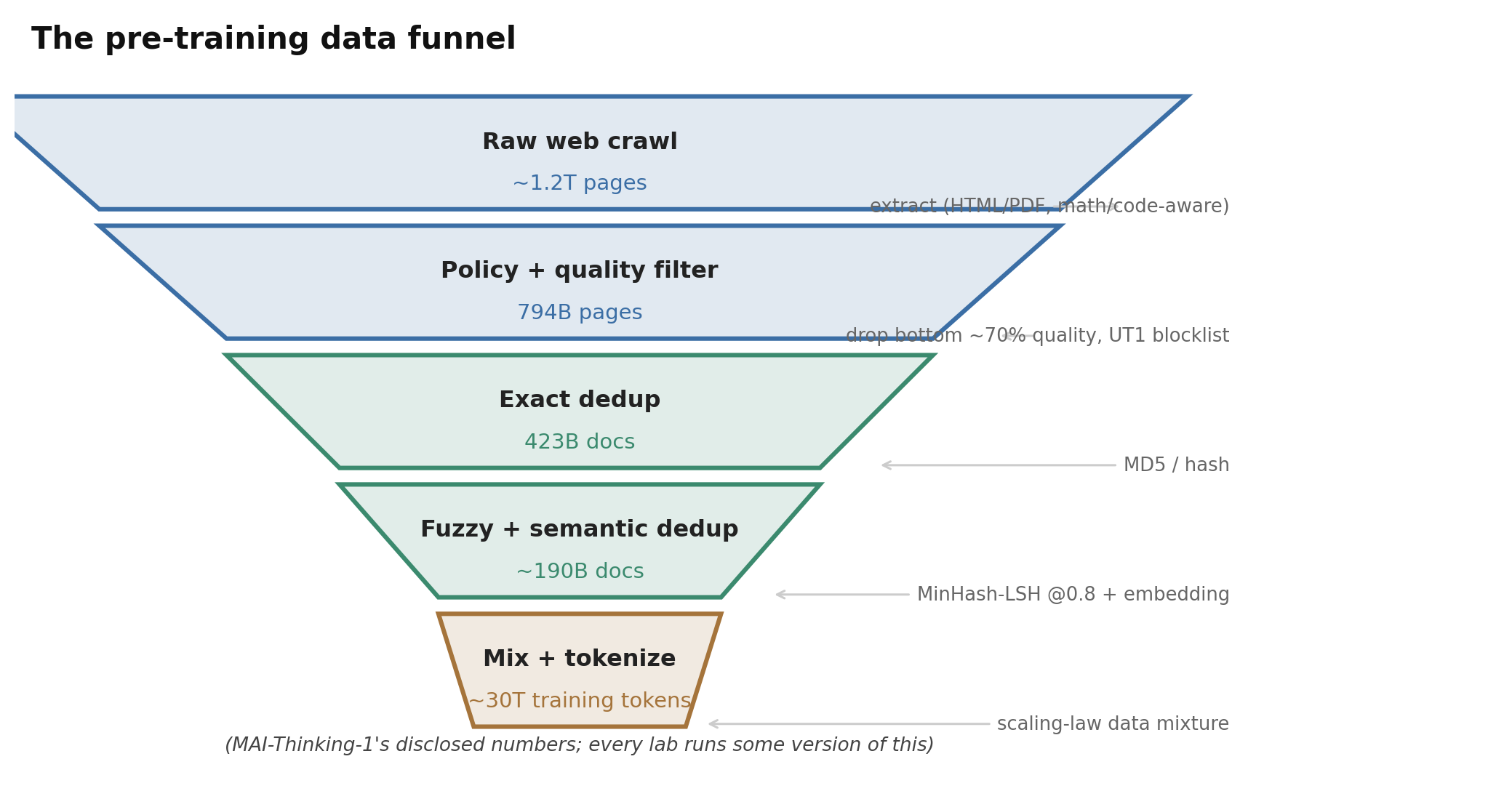 图 3. 这条数据漏斗以 MAI-Thinking-1 公开的数字作为具体示例:约 1.2T 爬取页面经过政策与质量过滤,再用多种方式去重,最后重新混合成约 30T 训练 token。每家实验室都在跑某个版本的它;真正的分歧在于各项占比,以及合成数据策略。
图 3. 这条数据漏斗以 MAI-Thinking-1 公开的数字作为具体示例:约 1.2T 爬取页面经过政策与质量过滤,再用多种方式去重,最后重新混合成约 30T 训练 token。每家实验室都在跑某个版本的它;真正的分歧在于各项占比,以及合成数据策略。
抽取被严重低估。 实验室最想要的内容——数学、代码、表格——恰恰是朴素的 HTML 转文本流程最容易弄坏的部分。所以好的报告都会描述定制化的抽取器:MAI 把 MathML 和 LaTeX 归一化为 Markdown,并使用一个只能保留或删除文本片段(绝不添加合成文本)的 LLM;Llama 3 构建了一个自定义解析器,能保留代码/数学结构,甚至会为公式保留图片的 alt 文本;MiMo 和 Llama 都指出,通用过滤器会错误地丢弃富含数学/代码的页面。这种投入的回报体现在那些专门构建的语料上——代码用 StarCoder2 / The Stack v2,数学用 Nemotron-CC-Math——在这些语料里,精心抽取本身就是绝大部分价值所在。
去重是多阶段的,而且是承重环节。 各份报告收敛到了同一套组合:去除样板内容、精确(哈希)去重、MinHash-LSH 模糊去重(相似度约 0.8)、模板化页面的骨架化,以及越来越多地采用沿袭 SemDeDup 和 D4 思路的嵌入/语义去重——它们表明,你可以丢掉约一半的网页数据而不损失质量,而且聪明的重复胜过随机的新鲜 token。MAI 把这些全都跑了一遍,外加一套跨数据集的丢弃次序,以保证同一篇文档不会在不同来源间被重复计入;它明确报告了这条漏斗(1.2T 页面 → 过滤后 794B → 精确去重后 423B → 模糊去重后约 190B)。
过滤与分类把一堆杂乱数据变成可控的语料。 实验室用廉价的分类器给每篇文档打分——用 fastText 和嵌入模型来判断语言、主题、教育价值/层次以及质量——于是语料就变成了一组带标签、可供混合的桶。Essential AI 的 Essential-Web 把这一思路推到了逻辑极致:用一个蒸馏出来的分类法分类器把整个网络标注一遍,之后想要整理任何一个领域,只需用类似 SQL 的过滤查询,而不必每次都训练一个新分类器——这正是 MAI“把语料组织成可解释维度”的理念。
数据混合已经成为一门量化学科。 领域配比(网页、代码、数学、多语种各占多少)极大地决定了能力,而实验室已经不再靠手工设定它了。Data Mixing Laws(Ye et al., 2024)表明,验证 loss 是混合比例的一个可预测函数——先在小规模的“群跑(swarm)”实验上拟合它,再去优化;RegMix 和 OLMix 把这套做法工程化落地(OLMix 还为不断演化的领域集合加入了复用机制)。MAI 在 3 个规模上、跨 61 种混合配比训练了 183 个模型,以刻画其 Pareto 前沿;Llama 3 通过 scaling-law 实验选定了大致 50% 通用 / 25% 数学与推理 / 17% 代码 / 8% 多语种的配比;MiMo 则刻意采用了一套三阶段混合,把数学+代码的占比一路拉升到约 70%。
开放问题——小规模排名可能会骗人。 廉价的混合搜索背后有一个诱人的假设:排名不变性——如果配比 A 在小规模上胜过配比 B,那么它在大规模上也会胜出。MAI 报告说这个假设被打破了——一个偏代码的混合和一个偏 STEM 的混合,在 5B 与 23B 模型之间交换了名次。也许混合配比需要按它们的scaling 行为来选择,而不是靠一次小规模的对比测试。
整篇文章里最尖锐的分歧就在这里:
分歧——合成数据 vs 人类数据。 MAI 采取了反主流的强硬立场:预训练中不使用任何 LM 生成的合成数据,并主动地去检测并移除爬取数据中的 AI 生成内容(这是一种押注:干净的人类数据可以避开模型崩溃 / 同质化的陷阱)。但相反的一极同样随处可见:Hunyuan-Large 在约 1.5T 合成 token 上训练,这些 token 来自一条四步走的“生成—演化—过滤”流水线;Persona Hub 用十亿量级的 persona 来扩展合成数据的多样性;Qwen 和 Nemotron 则倚重合成改写与蒸馏。MiniMax 取了个折中(和 MAI 一样,在预训练中回避合成数据)。这个问题确实尚无定论,也是最能干净利落地标记出“实验室之间存在分歧”的一刻。
最后,去污染(decontamination)——把评测基准挡在训练数据之外——是潜伏在这一切之下的一场静默危机。随着基准泄漏到 GitHub 和各类爬取数据里,污染会产出好看却虚假的数字。实验室对此的处理还比较粗糙:MAI 移除所有 huggingface 镜像,并普遍施加 20-gram 模糊去重,而且——这也是大家正在收敛到的做法——依赖那些他们有信心不会出现在网上的私有、留出(held-out)基准。我们会在评估一节再回到这个话题。
小结。 数据是分享得最少、却杠杆最高的阶段:一条已经收敛的漏斗(抽取 → 去重 → 分类 → 混合)之上,压着两个悬而未决的问题——该有多信任合成数据,以及你的评测集是否早已泄漏进了训练数据。
预训练:scaling、精度与稳定性
有了数据之后,预训练如今已是一门工程学科,围绕三个问题展开:模型多大、训练多久(scaling),用什么数值格式(精度),以及如何让一次长达数月的训练不至于发散(稳定性)。再加上一个两年前几乎还不存在的第四阶段:mid-training。
Scaling:从 Chinchilla 到刻意的过度训练。 2020 年的 Kaplan laws 指出,loss 是参数量、数据量与算力的一个平滑幂律,并建议把预算的大头花在参数上——那是 Gopher 和 PaLM 的时代。Chinchilla 纠正了这一点:在固定的训练预算下,应当让参数量和 token 量一起扩展,大约每个参数配 20 个 token。但 20 TPP 是训练算力最优,而非部署最优——一旦你把一个模型摊销到数十亿次推理 token 上,正确的做法就是用一个远超 20 TPP 训练的更小模型。于是整个领域开始刻意地过度训练:Llama-3-8B 见过约 15T token(约 1900 TPP);MAI 把它的主力模型训练在 500–1000 TPP,以得到一个紧凑、推理便宜的结果,同时在接近 Chinchilla 最优的区域里做架构消融。MAI 把这套方法论很好地形式化了:一是scaling ladder(scaling 阶梯)(让一个模型家族在每个激活参数对应固定 token 数下训练),二是 Efficiency-Gain(效率增益)指标(基线要追平某个候选方案还需要多少额外算力)——这样每一处改动都由它的 scaling 曲线来证明其价值,而不是靠单个数据点。
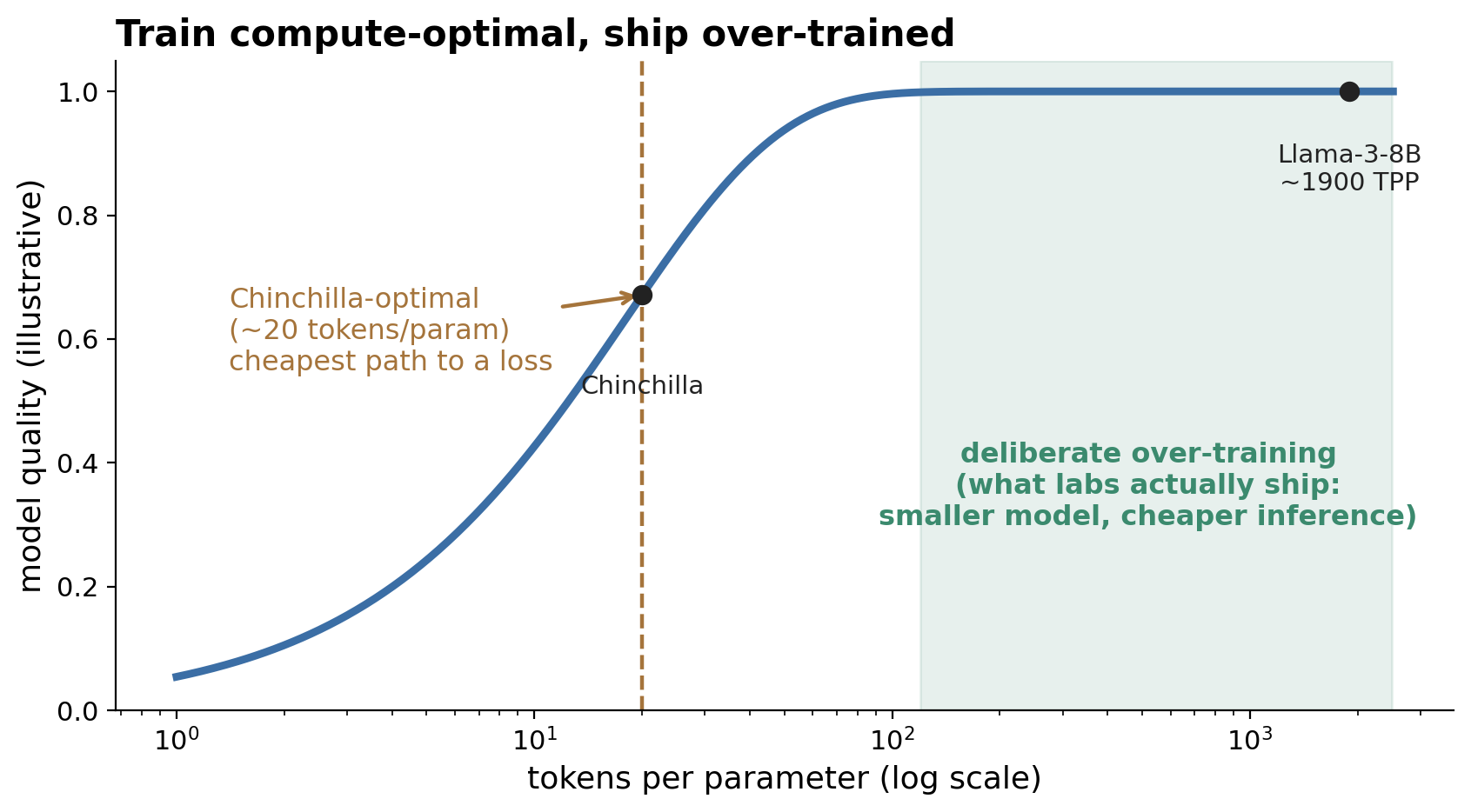 图 4. Chinchilla 主张让参数量与 token 量一起扩展(约每参数 20 个 token),以最便宜的路径达到某个 loss;而推理的经济账则推动实验室选一个更小的模型,并把它一路向右过度训练。实验室在接近算力最优处做消融,但发布的是深处过度训练区间的模型。
图 4. Chinchilla 主张让参数量与 token 量一起扩展(约每参数 20 个 token),以最便宜的路径达到某个 loss;而推理的经济账则推动实验室选一个更小的模型,并把它一路向右过度训练。实验室在接近算力最优处做消融,但发布的是深处过度训练区间的模型。
共识——为推理而过度训练。 没人再去做算力最优训练了。背后的共同逻辑是:训练只付一次钱,推理却要永远付钱,所以用额外的训练 token 去换一个更小、更便宜的模型。这件事的开放前沿是数据墙——在极端的 TPP 下,你会耗尽独一无二的高质量 token,这又绕回到了合成数据之争。
精度:BF16 → FP8 → FP4。 训练精度一路向下行进,从 FP16 混合精度的时代(Micikevicius et al., 2017),经过 BF16(Zamirai et al., 2020),来到今天的前沿。最显眼的一次效率冲击,是 DeepSeek-V3 用 FP8 训练了一个 671B 模型——使用 FP8 formats(前向 E4M3、反向 E5M2),配合细粒度的 tile/block 级缩放来驯服离群值——总成本约 $5.6M,相对 BF16 的 loss 误差不到 0.25%(这还得益于 stochastic rounding 之类的技巧)。NVIDIA 的 Nemotron 3 更进一步推到了 NVFP4(4-bit),通过逐层的精度规则(让网络最后约 15% 保持高精度)做到了在 25T token 上保持稳定;gpt-oss 则发布了 MXFP4 MoE 权重,让一个 120B 模型能塞进单张 GPU。MAI 同样用 FP8 训练。那些坚守者也很有启发:Llama 3 出于稳健性留在了 BF16——这是一个反复出现的“稳定性优先于效率”的主题。
分歧——优化器的垄断正在裂开(而 Muon 正在胜出)。 十年来,AdamW 一直是唯一的答案。如今 Muon(Liu et al., 2025)——它通过一次 Newton–Schulz 迭代把动量更新正交化,并匹配 AdamW 的更新 RMS——号称有约 2× 的算力效率,而各家旗舰都在切换:GLM-4.5/GLM-5 用 Muon,Kimi K2 用 MuonClip(Muon 加上一个 QK-Clip,它会重新缩放 query/key 投影以给注意力 logits 封顶;一次 15.5T token、万亿参数的训练做到了零 loss 尖峰),而到了 2026 年,连 DeepSeek-V4(2026)——一家长期使用 AdamW 的实验室——也采用了 Muon,“以获得更快的收敛和更好的训练稳定性”。AdamW 仍在训练 MAI、Qwen 和 Llama,但这股“动量”(一语双关)显然站在 Muon 一边——这是多年来最具影响力的优化器转变。
稳定性本身就是一个研究领域。 一次动用上千张 GPU、长达数月的训练,可能会死于 loss 尖峰、发散的 logits,甚至是硬件比特翻转。那些廉价而近乎通用的修法——QK-norm 和 z-loss——来自那项小规模代理研究(Wortsman et al., 2023),而完全开放的 OLMo 2 报告则是其余各种技巧的最佳公开清单:一个用于剔除诱发尖峰数据的重复 n-gram 文档过滤器、std-0.02 的初始化、把 AdamW 的 ε 降到 1e-8、重排(pre+post)的 norm、对 embedding 不施加权重衰减——每一项都带有一个对其“尖峰分数(spike score)”的实测下降。MAI 的基础设施层还加入了确定性和静默数据损坏(silent-data-corruption)的处理。这些东西,在一份封闭的 system card 里是看不到的。
Mid-training 是新出现的阶段。 在原始的预训练和后训练之间,实验室如今插入了一个 mid-training 阶段:在高质量(往往是退火过的)数据上,给 STEM/数学/代码加权,并把上下文扩展到 128K–256K。这并不是装点门面:OctoThinker 表明,mid-training 决定了一个 base model 是否具备做 RL 的条件——同一套 RL 配方能让 Qwen 一飞冲天、却让 Llama 停滞不前,而推理密集的 mid-training 能弥合这道鸿沟。MAI 专门跑了一个显式的 mid-training 阶段(给 STEM 加权,把上下文扩到 256K),目的正是“为推理 RL 打下坚实的基础”;DeepSeek、Qwen 和 MiMo 也各有各的版本(MiMo 的三阶段混合、Llama 高质量的“退火”尾段)。
小结。 预训练如今就是工程:用 ladder 加 EG 的方式做 scaling、刻意地过度训练,采用 FP8/FP4 精度,配一套小巧的稳定性工具箱(QK-norm、z-loss、谨慎的初始化),再加上一个悄悄决定了 RL 上限的 mid-training 阶段——与此同时,AdamW 对 Muon 的优化器之争又重新打开了。
后训练(一):SFT、冷启动与蒸馏
预训练和中训练给你一个具备广泛能力的基础模型,但它完全不知道该如何行事——如何遵循指令、在回答之前进行推理,或者使用工具。后训练修复了这一点,它已经固定为一种两幕式结构:一个设定起点的监督阶段,然后是负责爬坡的强化学习(下一节)。本节讲的是起点,整个流程中最深层的理念分歧就发生在这里。
SFT 究竟是做什么用的。 人们很容易认为能力来自监督微调(SFT)。但在现代配方中,它主要是一道就绪门槛:教会模型聊天/工具的格式,并为它注入足够的能力,使其能产出一些好的 rollout,从而让 RL 有信号可以放大。做过头会僵化策略、扼杀 RL 所需的探索;做得不够则 RL 无处发力。指令数据本身也越来越多是合成的——其脉络从 WizardLM’s Evol-Instruct(让一个 LLM 把种子指令改写得更难、更多样)一路延伸到角色驱动的生成与约束分类体系。
“冷启动”与纯 RL 的意外。 这个时代最有影响力的后训练成果是 DeepSeek-R1(DeepSeek-AI, 2025)。它的 R1-Zero 变体把 GRPO 直接用在基础模型上,完全没有 SFT,仅靠基于规则的可验证信号给予奖励——推理能力却涌现了:AIME 准确率从 15.6% 攀升到 77.9%,回复长度自行增长,模型还自发地发展出自我检查(著名的”aha moment”,即”wait”一词的频率骤增)。代价是可读性和语言混杂问题,完整版 R1 通过在 RL 之前加入一小段冷启动 SFT(几千条精选的长 CoT 样例)来修复。这个模板——可选的冷启动 → RL → 拒绝采样 → RL——如今已成为标准(Qwen3、Kimi、MiMo、Magistral、MAI 都各自跑了一个版本)。
自我改进是大规模制造 SFT 数据的方法。 当你能验证答案时,就不需要人类来撰写推理轨迹了——模型自己写,你只保留其中好的。这是同一个想法的三种外衣:STaR(Zelikman et al., 2022)筛选自己生成的、正确的推理依据;LMSI(Huang et al., 2022)在没有标签的情况下按自洽性筛选;ReST-EM(Singh et al., 2023)则表明”生成→筛选→SFT”这个循环就是期望最大化(EM),并且只要你能检查正确性,它就胜过在人类数据上训练。Llama 3 的拒绝采样和 Tulu 3 的流水线都是其直系后裔,相关的自我纠正引擎(Self-Refine、Chain-of-Verification)也在喂养同一个循环。
自蒸馏作为存档点。 一个更新颖、更微妙的用途是让长达上千步的 RL 训练保持存活。MAI 大量依赖自蒸馏:定期用 RL 训练自身的 rollout 对一个全新的 checkpoint 做 SFT,然后恢复 RL。他们用它来从原始 prompt 过渡到聊天格式、用它从崩溃中恢复(从崩溃前的 checkpoint 恢复之所以失败,是因为不稳定性早已固化进了权重里),以及用它把已有进展迁移到新的基础模型上。他们的消融实验很值得引用——约 100 万条轨迹就足够,错误答案的轨迹与正确答案的轨迹效果大致相当,而来自一系列后期 checkpoint 的轨迹胜过仅来自单一最终策略的轨迹。该技术在 on-policy self-distillation 中有一个干净的形式化表述(Zhao et al., 2026)。
这一切为什么有效——为什么同一套 RL 对一个基础模型有用、对另一个却无效?因为 RL 主要是放大基础模型已经具备的行为。这项”认知行为”研究(Gandhi et al., 2025)表明,验证、回溯、设定子目标和反向链式推理在 Qwen 中存在,而在 Llama 中基本缺失;并且用这些行为给 Llama 做预热(哪怕是通过错误但结构良好的轨迹),就能让它变得可用 RL 训练。这正是中训练和冷启动之所以重要的深层原因:它们安装了 RL 将要打磨的那些行为。
分歧——继承 vs 学习。 2025 年的主流做法是蒸馏:把 R1 的 80 万条长 CoT 轨迹 SFT 进小的 Qwen 和 Llama 模型,在同等规模下胜过从零开始的大规模 RL——所以 DeepSeek 甚至把 R1 反向蒸馏回 V3 自己的 SFT 数据,而大多数实验室也都会在某处从一个强推理器进行蒸馏。MAI 则把相反的立场当作立身原则:“能力应当被学习,而非被继承”,拒绝从第三方模型蒸馏,因为(他们论证)模仿来的智能缺乏长程爬坡所需的可操控性与鲁棒性。这是该领域最干净的理念分叉:蒸馏更便宜,而且按美元算往往效果更好,但只有 RL 才能探索到任何教师之外的地方。
小结。 SFT/冷启动设定起点并安装好 RL 就绪的行为;验证则把模型变成它自己的数据工厂(STaR/ReST-EM/自蒸馏)。开放问题是继承 vs 学习——是从一个更强的模型蒸馏,还是用 RL 从你自己的基础模型上培育能力。
后训练(二):RL,推理的引擎
这是现代配方的核心,也是 2024–2026 年间变化最大的部分。监督学习只能模仿其数据集中的轨迹;强化学习则让模型生成自己的尝试并由奖励来打分,正是这一点让长程推理和工具使用变得可训练。值得注意的是,这个阶段已经变得如此标准化——同时又如此脆弱。
从 PPO 到 GRPO
经典的 RLHF 使用 PPO(Schulman et al., 2017),其裁剪式代理目标至今仍是一切方法所继承的基底:最大化以奖励加权的概率比,但把这个比值裁剪到一个信赖域内,使得单次更新不会移动太远。PPO 需要一个价值模型(第二个与策略同等规模的网络)来估计优势的基线——代价高昂,而且当奖励只在一长串思维链的末尾才到来时会很别扭。
GRPO(Shao et al., 2024,DeepSeekMath)是定义了这个时代的一步:删除价值模型,转而从对同一个 prompt 采样得到的一组答案中估计基线。对于一个 prompt \(q\),采样 \(G\) 个回复,用奖励 \(R_i\) 给每个打分,并赋予回复 \(i\) 的每个 token 一个组相对优势 \(\hat A_i = (R_i - \text{mean}(R_{1..G})) / \text{std}(R_{1..G})\)。就是这样——一个蒙特卡洛基线,没有 critic,并且完美契合廉价的可验证奖励。GRPO(或它的近亲)如今是 DeepSeek-R1、Qwen3、MiMo、GLM-4.5、Magistral、Nemotron 和 MAI-Thinking-1 的 RL 主干。
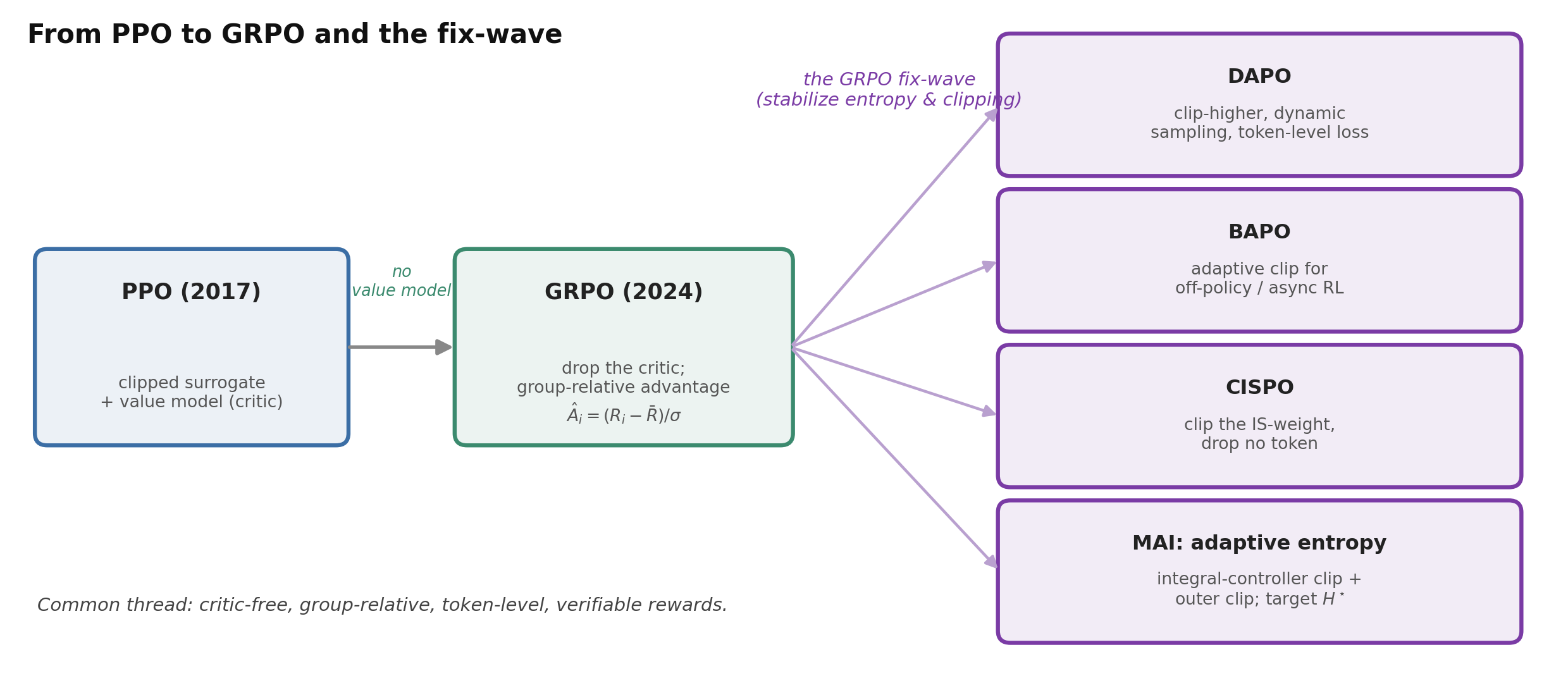 图 5. PPO 的裁剪式代理目标是基底;GRPO 抛弃价值模型,改用组相对基线;随后一波修补(clip-higher、token-level loss、移除 KL、自适应熵 / 外层裁剪、CISPO)让它在长 CoT 和 off-policy 训练中保持稳定。算法本身很少是贡献所在——稳定化才是。
图 5. PPO 的裁剪式代理目标是基底;GRPO 抛弃价值模型,改用组相对基线;随后一波修补(clip-higher、token-level loss、移除 KL、自适应熵 / 外层裁剪、CISPO)让它在长 CoT 和 off-policy 训练中保持稳定。算法本身很少是贡献所在——稳定化才是。
共识(截至 2025)——算法是大路货,稳定化才是真功夫。 几乎每个实验室都采用了一个 GRPO 家族的、无 critic 的、组相对的、token 级别的目标,配以可验证奖励。DeepSeek-R1 自己的论点说得很直白:推理的关键是”困难的问题、一个可靠的验证器,以及充足的算力”——而不是一个巧妙的损失函数。(正如我们将看到的,长程 agentic RL 正在让这一点变得复杂——其中包括 critic 的部分回归。)
朴素 GRPO 很脆弱:修补浪潮
复现 R1 规模的结果时人们发现,朴素的 GRPO 会崩溃,于是涌现出一波修补——它们几乎都围绕着代理目标如何被归一化和裁剪:
- DAPO(Yu et al., 2025)是事实上的”GRPO++”:clip-higher(更宽松的上界裁剪,让低概率的探索性 token 得以生长——从而保留熵)、dynamic sampling(丢弃通过率为 0 或 1 的 prompt,它们的组优势为零)、一个 token-level loss(对所有 token 归一化,而非按样本归一化,消除长度偏差),以及过长奖励整形(overlong-reward shaping)。它还丢弃了 KL 项。
- Magistral(Mistral, 2025)和 MiMo 印证了这套配方:消除 KL、对损失做长度归一化、clip-higher、过滤零优势的组。
- BAPO(Xi et al., 2025)把 clip-higher 推广为一个自适应控制器,用于异步基础设施所造成的 off-policy 情形。
- MiniMax 的 CISPO 裁剪的是重要性采样权重而非 token 更新,因此任何罕见的反思性 token 都不会被丢弃——比 DAPO 快 2 倍。
分歧——保留还是丢弃 KL 项。 一个真实存在的分裂:对长 CoT 推理丢弃到参考模型的 KL(策略应该远离初始化——DAPO、Magistral、MiMo、MiniMax),但对 RLHF 对齐则保留它(保持靠近一个可信模型——Tulu 3,以及 DeepSeek 的对齐阶段)。DeepSeek-V3.2 则以一个无偏的 KL 估计器和在数学领域里非常弱的 KL 来走钢丝。
长程任务的再思考:GSPO 与 critic 的回归
在 2024–2025 年的大部分时间里,上面这个故事(”GRPO + 几个修补”)确实就是故事的全部。但进入 2026 年,随着各实验室从单轮推理推进到长程 agentic RL——能运行数小时、跨越数十次工具调用的 agent——那个共识开始朝两个有趣的方向裂开,而这正是对整幅图景最重要的更新。
方向一——走向序列级(GSPO)。 GRPO 的重要性比是逐 token的,这在 MoE 模型上噪声很大(一个 token 的专家在 rollout 阶段和训练阶段之间可能不同),并迫使人们用前面提到的”router-replay”技巧。Qwen 的 Group Sequence Policy Optimization (GSPO)(Zheng et al., 2025)转而在序列级别(做长度归一化)定义重要性比和裁剪,这样更稳定、与序列级奖励相匹配,而且——值得注意的是——在 MoE 上消除了对路由重放(routing replay)的需求。Qwen 称最新的 Qwen3 模型背后就是 GSPO;它是”保持无 critic,但修正 GRPO 的分析单元”这一思路最干净的答案。
方向二——把 critic 请回来(PPO)。 更剧烈的反转来自 GLM。由 slime 训练的 GLM 系列(GLM-5, Zhipu, 2026)起步于 GRPO(外加一个修正训练/推理不匹配的”IcePop”),但 Zhipu 后来的 GLM-5.2 在其长程阶段明确地放弃了组相对优化,转向基于 critic 的 PPO。原因很具体,值得内化:当一条非常长的 agent 轨迹被压缩(compacted)成多条子轨迹时,同一个 prompt 的不同 rollout 会产出数量不同、长度差异极大的可训练轨迹——于是 GRPO”比较一组干净的、可比的 rollout”这一假设就崩溃了。一个 critic 估计单条 rollout 的 token 级别优势,并不要求各 rollout 在组内可比,这天然地契合压缩(再配上一个 token-level loss 来应对长度不均衡)。在所有人删除价值模型三年之后,价值模型又回来了——为了长程这一情形。
分歧——算法又开始变得任务专用。 干净利落的 2025 年叙事(”GRPO 赢了,算法是大路货”)正在让位于一个 2026 年的叙事:短的、可验证的任务用 GRPO/CISPO;稳定的 MoE RL 用 GSPO;长的、被压缩的、agentic 的轨迹用基于 critic 的 PPO。 GLM-5.2 回归 PPO 是头条,但更深层的要点是轨迹的长度与结构如今驱动着 RL 算法的选择。 注意 DeepSeek-V4(2026)又走了另一条路——保持 GRPO 按领域专家分别训练,再用 on-policy distillation 把这些专家融合起来——而 MiniMax 的 M2(2026)则围绕长而不均的轨迹构建了一整套 agent 原生的 RL 系统(”Forge”)。不再有单一的默认选项。
熵的问题
最重要的单一失败模式就是熵。熵太少,策略会坍缩成一个确定性的、不探索的模型并饱和;熵太多,它会喷出乱码并导致长度失控。Entropy Mechanism 这项研究表明这二者其实是同一个现象:\(\Delta H \propto -\text{Cov}(\log \pi, \text{advantage})\),而固定的 PPO 裁剪会系统性地移除那些让熵增加的更新 → 单调坍缩,并伴随一个可预测的上限(\(R = -a\,e^{H} + b\))。各种修补的差别在于你在哪里干预:在裁剪处(DAPO 的 clip-higher;BAPO 的自适应边界;MAI 的自适应熵控制——一个积分控制器,把上界裁剪的放松程度朝着目标熵 \(H^\star=0.3\) 微调),在协方差层面(Clip-Cov / KL-Cov 抑制那些特定的高协方差 token),或者通过一个熵奖励(entropy bonus)——而 Entropy-Mechanism 的作者和 MAI 都报告说,这种做法不如自适应方法。
技巧——把熵当作一个控制回路。 MAI 在这里的贡献是把熵当作恒温器来对待:每一步都测量它,并调整裁剪宽度以命中一个设定点,而不是去调一个固定的奖励项。它还在所有分支上加了一个硬性的外层裁剪(\(r_{max}=50\)),以消除 GRPO 那些有意不裁剪的分支可能造成的灾难性梯度尖峰。
奖励设计:为什么可验证奖励胜出
奖励是 RL 成败的关键所在,而它有三个来源,每一个都可被钻空子:
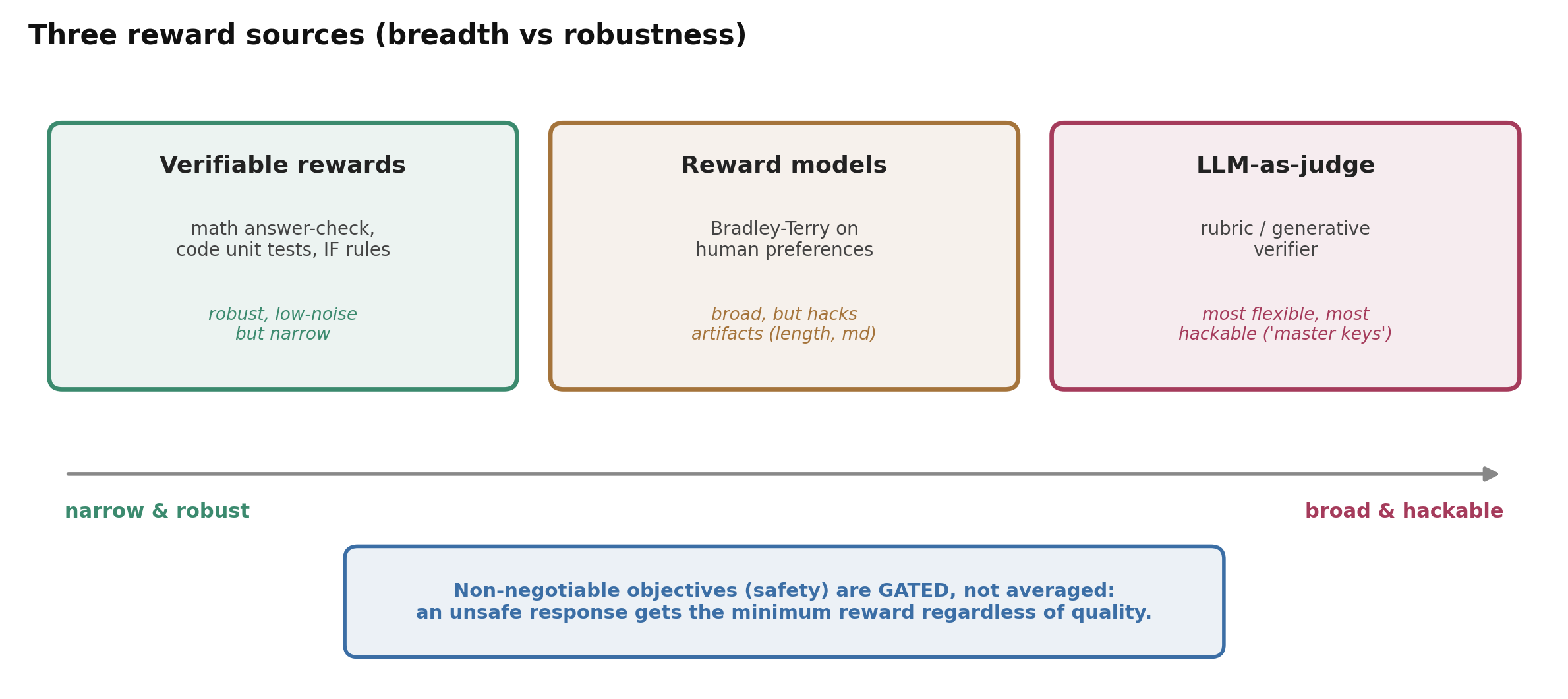 图 6. 三种奖励来源在广度与鲁棒性之间做权衡。可验证奖励(数学答案检查器、代码单元测试)覆盖面窄,但难以被操纵;奖励模型和 LLM 裁判覆盖开放式任务,但会被钻空子。像安全这样不可妥协的目标是被门控,而不是被平均进去的。
图 6. 三种奖励来源在广度与鲁棒性之间做权衡。可验证奖励(数学答案检查器、代码单元测试)覆盖面窄,但难以被操纵;奖励模型和 LLM 裁判覆盖开放式任务,但会被钻空子。像安全这样不可妥协的目标是被门控,而不是被平均进去的。
- 可验证奖励——数学答案是否匹配、单元测试是否通过——廉价、低噪声,且在奖励层面难以被操纵。这正是数学和代码主导 RL 的原因,也是 Tulu 3 把 RLVR 形式化的原因(”只有在可验证地正确时,策略才获得奖励”,并伴随一个直白的发现:仅用可验证奖励胜过奖励模型 + 可验证奖励——RM 只是徒增可被钻空子的噪声,Lambert et al., 2024)。DeepSeek-R1 正是出于这个原因刻意避开了神经奖励模型。
- 奖励模型会钻与 prompt 无关的伪特征(长度、markdown、表情符号)的空子;通过反事实增强来训练鲁棒 RM(Liu et al., 2024)会有帮助。
- LLM-as-judge 对开放式任务很方便,但极易被灾难性地愚弄:单个毫无意义的 token(”Solution”、”:”)就能诱使其给出错误的”正确”判定,发生概率高达约 80%,连前沿的裁判模型也不例外(Zhao et al., 2025)。
于是各实验室会组合奖励,而这个组合方式很重要。MAI 使用一个分解式奖励 \(R = R_{task} + w_{lang}R_{lang} - w_{len}R_{len}\)——加入了一个语言一致性奖励(混合语言的 CoT 会破坏训练的稳定性)和一个难度感知的长度惩罚。而对于不可妥协的目标,它采用门控而非平均:无论质量如何,一个不安全的回复都会拿到最低奖励(其动机来自一个发现:87.8% 的不符合策略的回复在奖励模型上仍然得到 ≥3 的分数——平均的话会让质量把安全给”买”回来)。我们将在对齐一节再谈这一点。
难度 ≠ 可训练性
一个微妙却普遍的筛选标准:哪些 prompt 值得拿来训练?不是最难的——而是可学习的那些。对于一个二元结果奖励而言,学习信号就是奖励的方差 \(\hat p(1-\hat p)\),它在 50% 成功率处取得最大值,并在两个极端处为零:一个策略总是失败或总是解出的 prompt,会在整个组里产生完全相同的奖励,于是组相对优势——以及梯度——恰好为零。
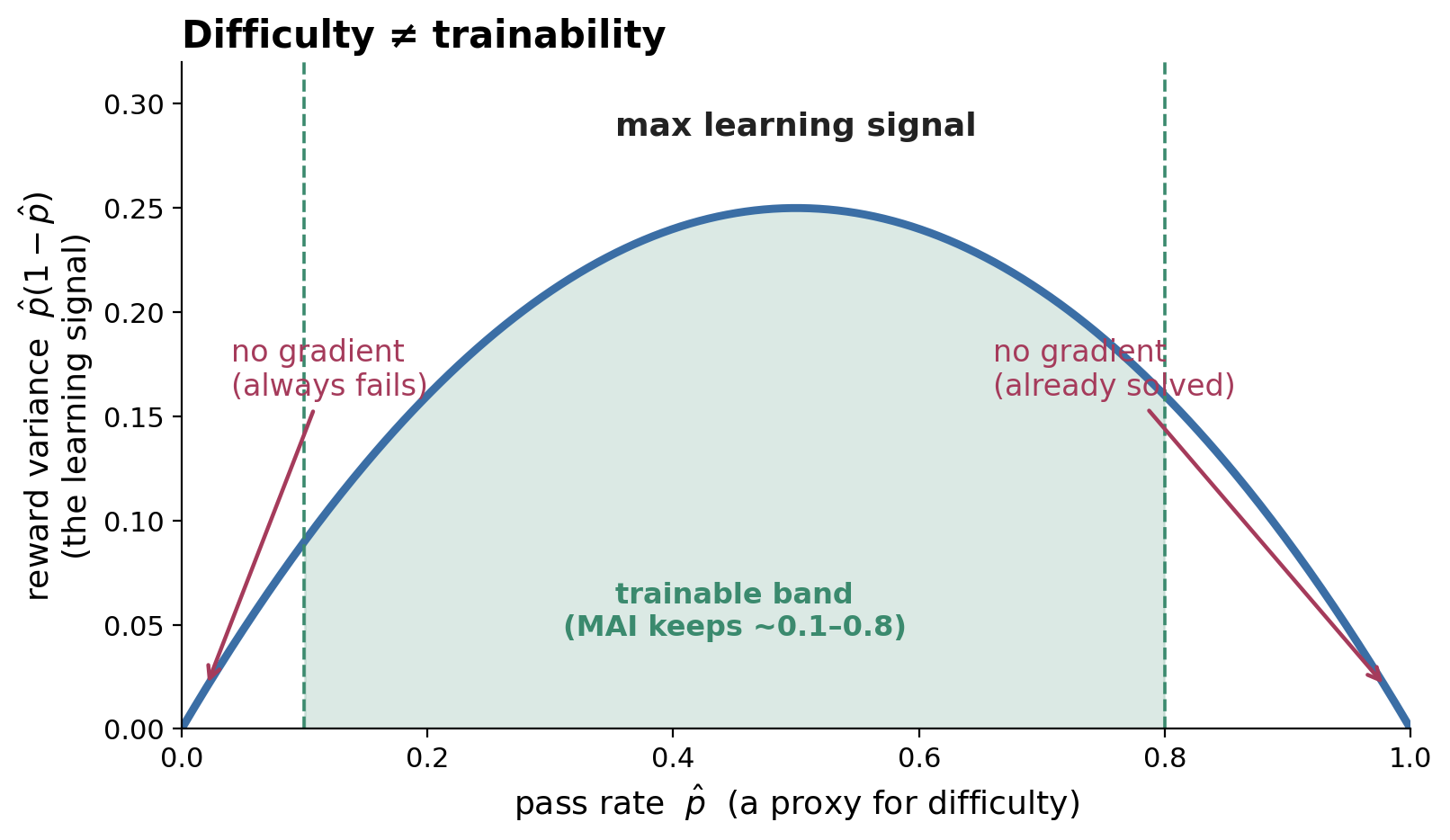 图 7. 只有当一个 prompt 的结果不确定时,它才有教学价值。学习信号是奖励方差 \(p(1-p)\):”太难”和”太易”因为同一个原因而失效。各实验室会筛选到一个中间区间。
图 7. 只有当一个 prompt 的结果不确定时,它才有教学价值。学习信号是奖励方差 \(p(1-p)\):”太难”和”太易”因为同一个原因而失效。各实验室会筛选到一个中间区间。
每个实验室都实现了这一点。MAI 把 prompt 筛选到 [0.1, 0.8] 的通过率区间(并用一个提前退出的预过滤来节省 rollout 成本);DAPO 的 dynamic sampling 丢弃 {0,1} 的组;MiMo 则保留一个简单数据池,以便在更多问题被攻克后稳定更新。这与 agentic-RL 世界里驱动环境课程的是同一个想法——在配套文章环境扩展中有详尽探讨。
把 token 花在刀刃上,以及 agentic RL
推理模型会”想太多”,于是各实验室加入了难度感知的长度惩罚——按一个 prompt 被解出的难易程度成比例地惩罚长度,让困难的问题可以思考更久(Xiang et al., 2025;MAI 采用的正是这一做法)。Qwen3 把它作为一个“思考预算”暴露给用户。而前沿是 agentic、多轮的 RL:把同样的 GRPO 目标用在一条由模型与环境交替步骤组成的轨迹上,运行在带有可验证奖励(测试通过、数据库达到目标状态)的沙箱容器内。MAI 的”agentic 爬坡”从 102M 个 GitHub PR 出发构建 SWE 环境,过滤到约 4.87M 个带有关联 issue 的 PR,由其按需沙箱内的 fail-to-pass / pass-to-pass 测试来评分;DeepSeek-V3.2 和 Kimi K2 则合成了数以千计的工具环境。这些环境的供给本身就是一个很深的话题——同样见环境扩展文章。
不光鲜但关键的稳定性技巧
最后,是那些上不了摘要、却能让训练收敛的修补:top-p mask replay(在训练时复用采样截断掩码,使训练与推理保持一致——MAI、DeepSeek-V3.2);MoE router replay(MoE 在推理引擎和训练引擎中会挑选不同的专家,这是一个被烤进架构里的 off-policy 缺口——通过重放路由来修复,Ma et al., 2025;DeepSeek 的”Keep Routing”);一个 FP32 LM head 用以修正训练/推理的精度不匹配(MiniMax);异步 RL 的陈旧度(staleness)边界;以及作为数值存档点的自蒸馏(上一节)。大多数实验室都在 verl/HybridFlow 和 OpenRLHF 这类开源 RL 框架之上构建(或将其替换)——MAI 之所以自己写了一个(”Rocket”),正是因为那些框架无法扩展到千卡 GPU 的异步 RL。
| 维度 | 共识 | 各实验室的分歧之处 |
|---|---|---|
| 顺序 | SFT/冷启动 → RL | 从基础模型纯 RL(R1-Zero、Magistral、MiMo-Zero)vs 先冷启动 |
| 算法 | GRPO 家族(无 critic、组相对、token 级) | GSPO 序列级(Qwen3);面向长程的 critic PPO(GLM-5.2);镜像下降(Kimi);CISPO(MiniMax);仅 DPO(Llama 3、Gemma 2、Hunyuan);PPO(Tulu 3、OLMo 2-7B) |
| KL 项 | 长 CoT 丢弃 | RLHF 对齐保留 |
| 熵 | 主动控制 | 自适应裁剪(MAI/DAPO/BAPO)vs Clip-Cov/KL-Cov vs 熵奖励(被否决) |
| 奖励 | 可验证奖励占主导 | + RM + 裁判;门控 vs 加权和;防钻空子的缓解措施 |
| 筛选 | 丢弃 {0,1} 通过率的组 | dynamic sampling;难度感知的长度惩罚 |
表 2. 后训练/RL 配方:高度收敛于一个 GRPO 家族的、可验证奖励的主干,而真正的分歧在于用多少 RL(相对于 DPO)、是否保留 KL,以及如何组合奖励。
分歧——到底用多少 RL? 并非所有人都属于重 RL 阵营。Llama 3、Gemma 2 和 Hunyuan-Large 刻意依赖 DPO / 拒绝采样 / 蒸馏,把 RL 保持得很轻甚至完全不用(Llama 言明的论点是复杂度管理)。DeepSeek、MAI、MiMo 和 MiniMax 则押注另一边,把算力大量投入 RL(DeepSeek-V3.2 如今在 RL 上的花费已超过预训练成本的 10%,并仍在上升)。这——而不是 GRPO 变体的选择——才是真正影响深远的分叉。
小结。 RL 如今是一台标准化却脆弱的引擎:一个 GRPO 家族的、可验证奖励的、token 级别的目标,而真正的功夫在于奖励设计、熵控制、可训练性筛选,以及一大堆训练/推理一致性的技巧。最大的赌注是在多大程度上依赖 RL,以及如何组合奖励。
对齐:有用性、安全与诚实
对齐曾经只是最后才给模型刷上的一层 RLHF 涂装。在 2026 年的配方里,它本身已经成为一组带有专属奖励栈的 RL“攀登”,与推理 RL 并行运行。如今所有人共享的框架是一种待优化的张力,而非一道待套用的过滤器:模型必须同时做到有用(顺从)和安全(有时拒绝),而技艺就在于两者兼得。MAI 将目标表述为“既有用、又始终符合策略的回复”;OpenAI 则把同一目标描述为从拒绝走向safe completion。
这里的奖励栈是整条流水线中最异质的,因为这些目标(“这条回复有用吗?诚实吗?风格得体吗?”)难以验证。MAI 的有用性与安全性攀登结合了三种信号:在人类偏好上训练的奖励模型(并辅以反奖励作弊的缓解手段)、AI 评判者(快速、由评分量表引导、易于改换目标),以及在任何约束可检验之处使用的可验证奖励(例如“用不超过 10 个词作答”)——之所以特别采用最后一种,是因为可验证信号更难被作弊,并能稳定其余信号。
技巧——对安全做门控,而非取平均。 这里最具可迁移性的一个想法是:有些目标不可妥协,而加权求和会让一条文笔出色的回复把“不安全”赎回来。MAI 采用字典序 / 门控式聚合——一条不符合安全策略的回复,无论其他分数多高,都只得到最低奖励——其动机来自一份触目惊心的审计:87.8% 不符合策略的回复,在奖励模型上仍然拿到 ≥3 分。 取平均本会奖励它们。
Instruction hierarchy。 生产环境的模型必须按权限对指令排序——system > developer > user > 工具输出——这样,网页中被注入的“忽略你的指令”便无法覆盖系统提示(Wallace et al., 2024,它是 OpenAI 的 Model Spec 与 gpt-oss 的 harmony 格式的基础)。MAI 用对抗性的 system/developer/user 冲突显式训练这一能力;它如今已成为安全 SFT/RL 的标准配料。
从拒绝到 safe-completions。 最清晰的对齐演进来自 OpenAI 的转向,记录在 GPT-5 system card 中:从二元的硬拒绝转向以输出为中心的 safe-completions——在服从于安全策略的前提下最大化有用性。这对于双重用途的问题严格更优:对这类问题,高层次的回答没有问题,但操作层面的细节则不行。gpt-oss 进一步加入了 deliberative alignment(模型在推理时对安全策略进行推理)。MAI 的安全攀登带有“有害 vs 边缘”的分类法,并明确对抗过度拒绝,本质上是换了名字的同一套理念。
诚实与校准。 这是一条更微妙、且多数实验室处理不足的对齐维度:模型应当在知道时作答、在不知道时表达不确定——但不能过度含糊以致毫无用处。MAI 的诚实奖励把回复分成五档(自信-正确 → 自信-错误),对自信-正确给予最高奖励,对自信的幻觉给予最重惩罚,对弃答给予中性分数——明确抑制过度含糊。这关联到一个更深层的问题(长程智能体中的校准、弃答与不确定性),它有自己专门的姊妹文章。
分歧——披露多少。 方法正在趋同,但披露程度并未趋同。OpenAI 的 system cards 是评测/安全方面的参考标杆(Preparedness 类别、红队时长、safe-completions),却几乎不透露任何训练细节;开放配方(OLMo 2、Tulu 3、Magistral)完整披露训练,但安全章节单薄。MAI 居于两者之间,一边借用 OpenAI 的安全话语体系,一边披露多得多的配方细节。
小结。 对齐如今是一个带有自身复合奖励栈的 RL 目标,由有用性↔安全的张力所定义。可迁移的经验是:对不可妥协的目标做门控而非取平均、显式训练 instruction hierarchy、用 safe-completions 取代硬拒绝,并奖励校准过的诚实而非一概含糊其辞。
评测:度量这场攀登
一台“爬山机器”只能攀登它能度量的山,这让评测成为整条流水线中沉默的瓶颈。这些报告揭示了两种不同的评测体制:一种廉价、稳健,用于研发(成千上万个决策);另一种昂贵、公开,用于发布。
研发阶段,loss 胜过准确率。 MAI 把这一论点表达得最为有力:对于它用来做预训练和数据配比决策的那套约 40 个基准的测试集,它以 NLL(loss),而非准确率来打分。理由是操作层面的,也是决定性的——准确率评测需要昂贵的自回归生成,而且往往还需要一个评判模型;多选题能力只有在大规模时才会“涌现”,因而在早期噪声很大;MATH 需要精确的 \boxed{} 格式,而 MBPP 会在 \n 与 \r\n 之间栽跟头。NLL 与训练所用的目标完全相同,都是教师强制式的下一 token 目标,因此既廉价又富含信号——Signal-and-Noise 框架也呼应了这一结论。完全开放的实验室出于同样的原因构建了专门的研发测试集(Ai2 的 OLMES)。
发布阶段,则是基准动物园。 公开的成绩单已围绕一组耳熟能详的基准标准化:数学(AIME、MATH、HMMT)、科学(GPQA、Humanity’s Last Exam)、代码(LiveCodeBench、SWE-bench 以及更难的 SWE-bench Pro、Terminal-Bench)、知识(MMLU 与 MMLU-Pro)、事实性(SimpleQA、FActScore)、长上下文(RULER、LongBench v2、Michelangelo)、智能体工具使用(τ²-bench、BFCL),以及越来越多的领域测试集,如 HealthBench 和 MedXpertQA。MAI 报告的头条数字(52.8% SWE-Bench Pro、97.0% AIME 2025)也在此列,其他每家实验室亦然——但跨报告的比较应当谨慎看待,因为评测框架(harness)、提示词与工具访问方式各不相同(这也是“微型”精选子集和考虑不确定性的评分方式逐渐流行的原因之一,例如 tinyBenchmarks)。
开放问题——评测才是真正的瓶颈。 随着模型把旧基准刷到饱和,信号转移到了少数几个困难、且易泄漏的测试集上。诚实的实验室越来越依赖私有的留出基准(MAI 自建测试集;这是对抗污染唯一可靠的防线)、对趋于饱和的测试集做经过验证的重新发布(SimpleQA Verified),以及在训练之后才出现的实时评测(MathArena 对新鲜的竞赛进行打分)。你只能攀登你能度量的东西,而这些量尺的磨损速度,比我们造出新量尺的速度还快。
污染才是底下的危机。 如果一个基准已经泄漏进了训练数据,你的数字就是虚构的——MAI 还指出了一个露馅的症状:污染会让一个“编程”数据集神秘地提升毫不相关的冷知识表现。各种对策(20-gram 模糊去重、按代码仓库/时间排除、移除 HuggingFace 镜像)都不完美,这正是私有基准和实时基准正在成为唯一可信标尺的原因。
超越基准。 由于可自动化的指标会漏掉风格、有用性和安全性,实验室还会加入人工并排对比评测(MAI 对此着重报告),并依赖 LLM-as-judge——而正如我们所见,评判者是可被作弊的,因此其自身的可靠性如今也被基准化了(RewardBench、JudgeBench)。
小结。 用廉价、稳健的 NLL 来做成千上万个研发决策;用公开的基准动物园加上人工评测来对外汇报;并把污染当作一等威胁来对待——私有基准和实时基准才是唯一持久的防线。
安全与红队
对齐训练(见上一节)赋予的是安全的能力;本节讲的是实验室如何在发布前度量并压力测试这种能力。这里的范式很大程度上由 OpenAI 的 Preparedness Framework 奠定,如今被各处效仿:定义一小组被追踪的风险类别(GPT-4o:网络、CBRN、说服、模型自主性;GPT-5 与 gpt-oss:生物/化学、网络、AI 自我改进),分配能力等级,并将部署门控在一个经安全委员会审查的、缓解后阈值之上。Google 的 Frontier Safety Framework 与 Anthropic 的 RSP 是同类;MAI 的安全章节借用了同样的脚手架。
红队是持续进行的,而且越来越自动化。 它贯穿整个研发过程,而非到最后才做。MAI 的对抗性提示来自人类红队,外加自动化攻击框架——PyRIT——以及各种越狱方法,如 PAP(说服)、Crescendo(多轮升级)、Tree of Attacks,乃至多语种越狱。OpenAI 以小时数和测试者人数来报告红队工作(GPT-5:5,000+ 小时、400+ 名测试者)。Llama 3 在 LLM 之外还附带了一个真正的防护模型 Llama Guard——把安全作为一个系统,而不只是一个模型。
危险能力评测瞄准灾难性的尾部风险:生物武器能力提升(反复出现的五阶段生物风险分类法)、网络攻击(CyberSecEval、CTF 挑战)、危险知识(WMDP,并搭配遗忘学习 unlearning)、源自法规的风险测试集(AIR-Bench),以及专门的前沿危险能力评测。gpt-oss 还加入了一套专门针对开放权重的方法学:因为任何人都能微调一个已发布的模型,OpenAI 构建了一个经过对抗性微调的“最坏情况”版本(只追求有用的 RL + 能力最大化),并让外部团队确认它仍未越过 High 阈值——这正在成为负责任地发布开放权重模型的范式模板。
推理时代带来了一个新的安全杠杆:CoT monitoring。 由于推理模型以可读的思维链进行思考,你可以监控这段推理是否存在欺骗或不当行为——GPT-5 报告称,借助 CoT 监控,被标记的欺骗率减半了(4.8%→2.1%)。但有一个该领域正在积极担忧的陷阱:如果你针对 CoT 监控器进行训练,模型学到的会是混淆自己的推理,而非真正改正行为(Baker et al., 2025;Guan et al., 2025)。这使得“保持思维链可被监控”成为每一家训练 long-CoT 模型的实验室都要面对的现实设计约束——包括 MAI、DeepSeek、Magistral。
趋势——安全左移。 纵观这些报告,安全不再是一道发布关卡;它被编织进整条流水线:PII/CBRN 数据过滤(预训练)、奖励栈与 instruction hierarchy(后训练)、CoT 监控(推理),以及红队 + preparedness(发布)。
小结。 安全已成为一个贯穿整条流水线的过程,并拥有一套共享词汇(preparedness 类别、自动化红队、危险能力评测),而推理时代又加入了 CoT monitoring——它有用,但前提是我们不去训练模型隐藏自己的想法。
收敛的配方
从各个阶段往后退一步,本文开头的论断依然成立:到 2026 年,存在一套配方,而这些报告都是它的变体。下面用一口气讲完整条流水线——整理并去重“人类 + 合成”数据,并通过 scaling-law 预测来选择配比;在一个按“每参数 token 数”排布的阶梯上、以刻意过训练的方式、用 FP8 预训练一个 RoPE/GQA/SwiGLU/RMSNorm 的 MoE;在推理密集的数据上做 mid-training 并扩展上下文;用 SFT/冷启动来植入行为与格式;运行 GRPO 系的 RL,配以可验证奖励、熵控制和可训练性筛选;用门控的奖励栈和 instruction hierarchy 来做对齐;以廉价的 NLL 加上防污染的基准动物园来度量;并对照一套 preparedness framework 进行红队。 一旦你把这句话内化于心,下表中的每一份报告读起来都像是在做填空题。
| 模型 | 实验室 | 激活/总参数 | 稀疏度 | 预训练 | 优化器 | RL / 后训练 | 数据立场 |
|---|---|---|---|---|---|---|---|
| MAI-Thinking-1 | Microsoft AI | 35B / ~1T | 交错式 MoE | 30T | AdamW | GRPO + 自适应熵;3 次攀登 → 合并 | 仅人类数据 |
| DeepSeek-V3 | DeepSeek | 37B / 671B | MoE + MLA | 14.8T (FP8) | AdamW | GRPO;将 R1 蒸馏进 SFT | 合成 + 人类 |
| DeepSeek-R1 | DeepSeek | 37B / 671B | MoE + MLA | (V3) | — | 纯 RL → 多阶段;向外蒸馏 | — |
| DeepSeek-V4 | DeepSeek | 49B / 1.6T | MoE + CSA/HCA,1M 上下文 | 32T+ | Muon | 按专家分别 GRPO → on-policy 蒸馏 | 合成 + 人类 |
| Qwen3 | Alibaba | 22B / 235B | MoE(无共享专家) | 36T | AdamW | GSPO + 强→弱蒸馏;思考预算 | 偏重合成 |
| Kimi K2 | Moonshot | 32B / 1.04T | MoE + MLA | 15.5T | MuonClip | 镜像下降 RL;智能体化 | 改写式合成 |
| GLM-4.5 | Zhipu | 32B / 355B | MoE | 23T | Muon | GRPO(无 KL)+ 专家迭代 | — |
| GLM-5 / 5.2 | Zhipu | 40B / 744B | MoE + DSA,1M 上下文 | 28.5T | Muon | GRPO+IcePop → 带 critic 的 PPO(长程) | — |
| Llama 3 | Meta | 405B | 稠密 | 15.6T (BF16) | AdamW | SFT+RS+DPO(无 PPO) | 代码/数学用合成 |
| Gemma 3 | 27B | 稠密(多模态) | 14T | — | 蒸馏 + 轻量 RLVR | 教师模型蒸馏 | |
| MiMo-7B | Xiaomi | 7B | 稠密 | 25T | AdamW | 从基座起重度 GRPO | 推理密集型合成 |
| Hunyuan-Large | Tencent | 52B / 389B | MoE | 7T(约 1.5T 合成) | AdamW | SFT + DPO | 偏重合成 |
| MiniMax-M1 / M2 | MiniMax | 10–46B / 0.23–0.46T | MoE + lightning-attn | +7.5T | AdamW | CISPO / Forge 智能体 RL | 人类(预训练无合成) |
| OLMo 2 / Tulu 3 | Ai2 | 7–32B | 稠密 | 4–6T | AdamW | SFT→DPO→RLVR | 完全开放 |
| Nemotron 3 | NVIDIA | 3B+ | Mamba-MoE | 10T+ (NVFP4) | — | 多环境 GRPO | 开放 |
表 3. 一套配方,多种填法。横向逐列读下来,共识(MoE + 现代解码器块 + SFT→RL + 可验证奖励)一目了然——为数不多的几处真正的押注也同样清晰(稠密 vs MoE、AdamW vs Muon、GRPO vs GSPO vs PPO、重 RL vs DPO、合成 vs 人类)。2026 年的几行(DeepSeek-V4、GLM-5/5.2、MiniMax-M2)显示出前沿正在朝着 1M 上下文、Muon 和长程智能体 RL 移动。
大家一致认同的部分(八点共识):现代解码器块;细粒度 + 共享专家的 MoE,并在全局批次上做负载均衡;重度去重 + scaling-law 数据配比 + 一段 mid-training 收尾;刻意过训练;SFT/冷启动 → RL;带熵控制和可训练性筛选的 GRPO 系可验证奖励 RL;在某处包含蒸馏的多阶段后训练;以及安全奖励栈 + preparedness/红队流程。
真正的押注所在(值得争论的分歧):合成 vs 人类数据;继承(蒸馏) vs 习得(RL);AdamW vs Muon(截至 2026 年,Muon 正决定性地胜出——Kimi、GLM,如今还有 DeepSeek-V4);aux-loss vs aux-loss-free vs 全局批次负载均衡;稠密 vs MoE vs 混合;用多少 RL vs DPO;RL 算法本身——GRPO vs GSPO(序列级) vs 为长程智能体回归带 critic 的 PPO(GLM-5.2),这是最新、也最具说明性的转变;保留 vs 丢弃 KL 项;拒绝 vs safe-completions;以及披露多少(完全开放的配方 vs 只有基准表格的卡片)。
小结。 深读一份报告,你就等于读了全部——只差大约九个旋钮的不同。有趣的分歧(很可能还有下一步进展)所在之处,正是这些旋钮,而非那副骨架。
开放挑战
这套配方是有效的,但它若干承重的假设,其实比排行榜数字所暗示的更为脆弱。下面是我会投以怀疑目光的几处。
验证是 RL 的天花板。 整个 RL 阶段都建立在你能信任的奖励之上,而我们已经看到:奖励模型会利用表面伪特征作弊,LLM 评判者会败给单 token 的“万能钥匙”。这正是 RL 在数学和代码上效果如此之好、在其他几乎所有地方效果如此之差的原因——那两个领域拥有廉价而稳健的验证器。把可靠的验证扩展到真正不可验证的目标(“这份分析好不好?”),是横亘在其他大多数问题之下的开放难题。
数据墙撞上合成数据的两难。 刻意的过训练和越来越大的 token 预算,正撞上高质量人类文本的有限供给。逃生口是合成数据——但这恰恰是 MAI 拒绝的押注,它对在 AI 生成内容上训练发出了警告。合成数据究竟是乘数还是慢性毒药,尚无定论,而诚实的答案大概是“看用来做什么”(对多样性和可验证领域很好,作为整体性的预训练替代品则有风险)。
污染的诚实问题。 随着基准趋于饱和并发生泄漏,报告出虚高的数字变得越来越容易——甚至是无意为之。这个领域大多是在假定已经做了去污染,而非证明之;私有基准和实时基准有所帮助,但跨实验室的可比性正在悄然瓦解。
千步 RL 的成本与脆弱性——如今算法问题又被重新打开。 要维持一条对数线性的 RL 攀登曲线,需要一整套稳定器(熵控制、router replay、top-p 掩码 replay、自蒸馏存档点、异步基础设施)以及大量算力,而这部分算力如今在总训练成本中所占的比例正越来越大。而就在 GRPO 看起来已是尘埃落定的默认选项时,长程智能体 RL 又重新打开了算法之问:轨迹的“compaction(压实)”会产生长度不一的子轨迹,破坏了组内相对比较,这促使 Qwen 转向序列级的 GSPO,也让 GLM-5.2 退回到带 critic 的 PPO。这个领域会重新收敛,还是 RL 会永久地变得与任务相关(短的可验证任务用 GRPO/GSPO,长的智能体任务用 critic)——这是真正开放的问题,也是 2026 年最活跃的训练之争。这其中很大一部分仍是手艺,而非科学。
可监控性 vs 能力。 CoT monitoring 是推理时代为数不多的安全成果之一——但它只有在我们不针对它做优化时才有效。让思维链既忠实、可读,又同时把它训练得高效,是一个尚未解决的张力。
从经济角度看继承 vs 习得。 从一个强推理者蒸馏,比从零开始做 RL 更便宜,而且按每美元算往往更好——R1 已经表明蒸馏可以击败小模型的 RL。如果这个结论成立,这个领域就会把能力集中在少数几个前沿基座模型上,其余所有人都去做蒸馏。MAI“习得,而非继承”的押注,部分是在赌:就可操控性和稳健性而言,这条路是死胡同。究竟谁对,我们还不知道。
值得关注的前沿: 真正智能体化的长程 RL,以及喂养它的那些环境(环境扩展这一供给侧);为跨越许多步骤行动的智能体提供校准过的诚实与弃答;以及 Muon 和低于 4-bit 的精度是否会把成本曲线压低到足以改变“究竟谁能在前沿做训练”的程度。
小结。 诚实的成绩单是:验证、数据墙/合成数据问题,以及污染,这三处是当今前沿训练结果最可能言过其实的地方——而它们恰恰是下一轮报告必须直面的地方。
致谢 / 来源:标注「图片来源」的图复制自所引论文;其余图均为原创。
如何引用
Zhang, Jiaxin.(2026 年 6 月)。How Frontier Labs Train Large Language Models。Jiaxin Zhang’s Blog. https://jxzhangjhu.github.io/blog/2026/how-frontier-labs-train-llms/
@article{zhang2026frontierllmtraining,
title = "How Frontier Labs Train Large Language Models",
author = "Zhang, Jiaxin",
journal = "Jiaxin Zhang's Blog",
year = "2026",
month = "Jun",
url = "https://jxzhangjhu.github.io/blog/2026/how-frontier-labs-train-llms/"
}
References
[1] Amro Abbas, et al. “SemDeDup: Data-efficient learning at web-scale through semantic deduplication.” arXiv:2303.09540, 2023.
[2] Joshua Ainslie, et al. “GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints.” arXiv:2305.13245, 2023.
[3] Rahul K. Arora, et al. “HealthBench: Evaluating Large Language Models Towards Improved Human Health.” arXiv:2505.08775, 2025.
[4] Yushi Bai, et al. “LongBench v2: Towards Deeper Understanding and Reasoning on Realistic Long-context Multitasks.” arXiv:2412.15204, 2024.
[5] Bowen Baker, et al. “Monitoring Reasoning Models for Misbehavior and the Risks of Promoting Obfuscation.” arXiv:2503.11926, 2025.
[6] Mayee F. Chen, et al. “Olmix: A Framework for Data Mixing Throughout LM Development.” arXiv:2602.12237, 2026.
[7] Aakanksha Chowdhery, et al. “PaLM: Scaling Language Modeling with Pathways.” arXiv:2204.02311, 2022.
[8] Ganqu Cui, et al. “The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models.” arXiv:2505.22617, 2025.
[9] Damai Dai, et al. “DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models.” arXiv:2401.06066, 2024.
[10] DeepSeek-AI, et al. “DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model.” arXiv:2405.04434, 2024.
[11] DeepSeek-AI, et al. “DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning.” arXiv:2501.12948, 2025.
[12] DeepSeek-AI, et al. “DeepSeek-V3 Technical Report.” arXiv:2412.19437, 2024.
[13] DeepSeek-AI, et al. “DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models.” arXiv:2512.02556, 2025.
[14] DeepSeek-AI, et al. “DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence.” arXiv:2606.19348, 2026.
[15] Jasper Dekoninck, et al. “Beyond Benchmarks: MathArena as an Evaluation Platform for Mathematics with LLMs.” arXiv:2605.00674, 2026.
[16] Yue Deng, et al. “Multilingual Jailbreak Challenges in Large Language Models.” arXiv:2310.06474, 2023.
[17] Xiang Deng, et al. “SWE-Bench Pro: Can AI Agents Solve Long-Horizon Software Engineering Tasks?.” arXiv:2509.16941, 2025.
[18] Shehzaad Dhuliawala, et al. “Chain-of-Verification Reduces Hallucination in Large Language Models.” arXiv:2309.11495, 2023.
[19] Essential AI, et al. “Essential-Web v1.0: 24T tokens of organized web data.” arXiv:2506.14111, 2025.
[20] Kanishk Gandhi, et al. “Cognitive Behaviors that Enable Self-Improving Reasoners, or, Four Habits of Highly Effective STaRs.” arXiv:2503.01307, 2025.
[21] Tao Ge, et al. “Scaling Synthetic Data Creation with 1,000,000,000 Personas.” arXiv:2406.20094, 2024.
[22] Gemma Team, et al. “Gemma 3 Technical Report.” arXiv:2503.19786, 2025.
[23] GLM-4. 5 Team, et al. “GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models.” arXiv:2508.06471, 2025.
[24] GLM-5-Team, et al. “GLM-5: from Vibe Coding to Agentic Engineering.” arXiv:2602.15763, 2026.
[25] GLM-5.2 Team (Zhipu AI). “GLM-5.2: Built for Long-Horizon Tasks.” Zhipu AI / Z.ai, 2026.
[26] Aaron Grattafiori, et al. “The Llama 3 Herd of Models.” arXiv:2407.21783, 2024.
[27] Melody Y. Guan, et al. “Monitoring Monitorability.” arXiv:2512.18311, 2025.
[28] Lukas Haas, et al. “SimpleQA Verified: A Reliable Factuality Benchmark to Measure Parametric Knowledge.” arXiv:2509.07968, 2025.
[29] David Heineman, et al. “Signal and Noise: A Framework for Reducing Uncertainty in Language Model Evaluation.” arXiv:2508.13144, 2025.
[30] Dan Hendrycks, et al. “Measuring Mathematical Problem Solving With the MATH Dataset.” arXiv:2103.03874, 2021.
[31] Dan Hendrycks, et al. “Measuring Massive Multitask Language Understanding.” arXiv:2009.03300, 2020.
[32] Jordan Hoffmann, et al. “Training Compute-Optimal Large Language Models.” arXiv:2203.15556, 2022.
[33] Jian Hu, et al. “OpenRLHF: An Easy-to-use, Scalable and High-performance RLHF Framework.” arXiv:2405.11143, 2024.
[34] Jiaxin Huang, et al. “Large Language Models Can Self-Improve.” arXiv:2210.11610, 2022.
[35] Naman Jain, et al. “LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code.” arXiv:2403.07974, 2024.
[36] Jared Kaplan, et al. “Scaling Laws for Neural Language Models.” arXiv:2001.08361, 2020.
[37] Kimi Team, et al. “Kimi K2: Open Agentic Intelligence.” arXiv:2507.20534, 2025.
[38] Nathan Lambert, et al. “Tulu 3: Pushing Frontiers in Open Language Model Post-Training.” arXiv:2411.15124, 2024.
[39] Dmitry Lepikhin, et al. “GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding.” arXiv:2006.16668, 2020.
[40] Nathaniel Li, et al. “The WMDP Benchmark: Measuring and Reducing Malicious Use With Unlearning.” arXiv:2403.03218, 2024.
[41] Jingyuan Liu, et al. “Muon is Scalable for LLM Training.” arXiv:2502.16982, 2025.
[42] Tianqi Liu, et al. “RRM: Robust Reward Model Training Mitigates Reward Hacking.” arXiv:2409.13156, 2024.
[43] LLM-Core Xiaomi, et al. “MiMo: Unlocking the Reasoning Potential of Language Model – From Pretraining to Posttraining.” arXiv:2505.07608, 2025.
[44] Anton Lozhkov, et al. “StarCoder 2 and The Stack v2: The Next Generation.” arXiv:2402.19173, 2024.
[45] Wenhan Ma, et al. “Stabilizing MoE Reinforcement Learning by Aligning Training and Inference Routers.” arXiv:2510.11370, 2025.
[46] Aman Madaan, et al. “Self-Refine: Iterative Refinement with Self-Feedback.” arXiv:2303.17651, 2023.
[47] Rabeeh Karimi Mahabadi, et al. “Nemotron-CC-Math: A 133 Billion-Token-Scale High Quality Math Pretraining Dataset.” arXiv:2508.15096, 2025.
[48] Anay Mehrotra, et al. “Tree of Attacks: Jailbreaking Black-Box LLMs Automatically.” arXiv:2312.02119, 2023.
[49] Mike A. Merrill, et al. “Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces.” arXiv:2601.11868, 2026.
[50] Paulius Micikevicius, et al. “FP8 Formats for Deep Learning.” arXiv:2209.05433, 2022.
[51] Paulius Micikevicius, et al. “Mixed Precision Training.” arXiv:1710.03740, 2017.
[52] The Microsoft AI Team. “MAI-Thinking-1: Building a Hill-Climbing Machine.” Microsoft AI, 2026.
[53] Sewon Min, et al. “FActScore: Fine-grained Atomic Evaluation of Factual Precision in Long Form Text Generation.” arXiv:2305.14251, 2023.
[54] MiniMax, et al. “MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention.” arXiv:2506.13585, 2025.
[55] MiniMax, et al. “The MiniMax-M2 Series: Mini Activations Unleashing Max Real-World Intelligence.” arXiv:2605.26494, 2026.
[56] Mistral-AI, et al. “Magistral.” arXiv:2506.10910, 2025.
[57] Gary D. Lopez Munoz, et al. “PyRIT: A Framework for Security Risk Identification and Red Teaming in Generative AI System.” arXiv:2410.02828, 2024.
[58] NVIDIA, et al. “NVIDIA Nemotron 3: Efficient and Open Intelligence.” arXiv:2512.20856, 2025.
[59] Kaan Ozkara, et al. “Stochastic Rounding for LLM Training: Theory and Practice.” arXiv:2502.20566, 2025.
[60] Long Phan, et al. “Humanity’s Last Exam.” arXiv:2501.14249, 2025.
[61] Mary Phuong, et al. “Evaluating Frontier Models for Dangerous Capabilities.” arXiv:2403.13793, 2024.
[62] Felipe Maia Polo, et al. “tinyBenchmarks: evaluating LLMs with fewer examples.” arXiv:2402.14992, 2024.
[63] Zihan Qiu, et al. “Demons in the Detail: On Implementing Load Balancing Loss for Training Specialized Mixture-of-Expert Models.” arXiv:2501.11873, 2025.
[64] Jack W. Rae, et al. “Scaling Language Models: Methods, Analysis & Insights from Training Gopher.” arXiv:2112.11446, 2021.
[65] David Rein, et al. “GPQA: A Graduate-Level Google-Proof Q&A Benchmark.” arXiv:2311.12022, 2023.
[66] Mark Russinovich, et al. “Great, Now Write an Article About That: The Crescendo Multi-Turn LLM Jailbreak Attack.” arXiv:2404.01833, 2024.
[67] John Schulman, et al. “Proximal Policy Optimization Algorithms.” arXiv:1707.06347, 2017.
[68] Zhihong Shao, et al. “DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models.” arXiv:2402.03300, 2024.
[69] Noam Shazeer. “GLU Variants Improve Transformer.” arXiv:2002.05202, 2020.
[70] Guangming Sheng, et al. “HybridFlow: A Flexible and Efficient RLHF Framework.” arXiv:2409.19256, 2024.
[71] Avi Singh, et al. “Beyond Human Data: Scaling Self-Training for Problem-Solving with Language Models.” arXiv:2312.06585, 2023.
[72] Aaditya Singh, et al. “OpenAI GPT-5 System Card.” arXiv:2601.03267, 2025.
[73] Jianlin Su, et al. “RoFormer: Enhanced Transformer with Rotary Position Embedding.” arXiv:2104.09864, 2021.
[74] Xingwu Sun, et al. “Hunyuan-Large: An Open-Source MoE Model with 52 Billion Activated Parameters by Tencent.” arXiv:2411.02265, 2024.
[75] Team OLMo, et al. “2 OLMo 2 Furious.” arXiv:2501.00656, 2024.
[76] Kushal Tirumala, et al. “D4: Improving LLM Pretraining via Document De-Duplication and Diversification.” arXiv:2308.12284, 2023.
[77] Kiran Vodrahalli, et al. “Michelangelo: Long Context Evaluations Beyond Haystacks via Latent Structure Queries.” arXiv:2409.12640, 2024.
[78] Eric Wallace, et al. “The Instruction Hierarchy: Training LLMs to Prioritize Privileged Instructions.” arXiv:2404.13208, 2024.
[79] Shengye Wan, et al. “CYBERSECEVAL 3: Advancing the Evaluation of Cybersecurity Risks and Capabilities in Large Language Models.” arXiv:2408.01605, 2024.
[80] Zengzhi Wang, et al. “OctoThinker: Mid-training Incentivizes Reinforcement Learning Scaling.” arXiv:2506.20512, 2025.
[81] Lean Wang, et al. “Auxiliary-Loss-Free Load Balancing Strategy for Mixture-of-Experts.” arXiv:2408.15664, 2024.
[82] Jason Wei, et al. “Measuring short-form factuality in large language models.” arXiv:2411.04368, 2024.
[83] Mitchell Wortsman, et al. “Small-scale proxies for large-scale Transformer training instabilities.” arXiv:2309.14322, 2023.
[84] Zhiheng Xi, et al. “BAPO: Stabilizing Off-Policy Reinforcement Learning for LLMs via Balanced Policy Optimization with Adaptive Clipping.” arXiv:2510.18927, 2025.
[85] Violet Xiang, et al. “Just Enough Thinking: Efficient Reasoning with Adaptive Length Penalties Reinforcement Learning.” arXiv:2506.05256, 2025.
[86] Can Xu, et al. “WizardLM: Empowering large pre-trained language models to follow complex instructions.” arXiv:2304.12244, 2023.
[87] An Yang, et al. “Qwen3 Technical Report.” arXiv:2505.09388, 2025.
[88] Jiasheng Ye, et al. “Data Mixing Laws: Optimizing Data Mixtures by Predicting Language Modeling Performance.” arXiv:2403.16952, 2024.
[89] Qiying Yu, et al. “DAPO: An Open-Source LLM Reinforcement Learning System at Scale.” arXiv:2503.14476, 2025.
[90] Pedram Zamirai, et al. “Revisiting BFloat16 Training.” arXiv:2010.06192, 2020.
[91] Eric Zelikman, et al. “STaR: Bootstrapping Reasoning With Reasoning.” arXiv:2203.14465, 2022.
[92] Yi Zeng, et al. “How Johnny Can Persuade LLMs to Jailbreak Them: Rethinking Persuasion to Challenge AI Safety by Humanizing LLMs.” arXiv:2401.06373, 2024.
[93] Yi Zeng, et al. “AIR-Bench 2024: A Safety Benchmark Based on Risk Categories from Regulations and Policies.” arXiv:2407.17436, 2024.
[94] Biao Zhang and Rico Sennrich. “Root Mean Square Layer Normalization.” arXiv:1910.07467, 2019.
[95] Yulai Zhao, et al. “One Token to Fool LLM-as-a-Judge.” arXiv:2507.08794, 2025.
[96] Siyan Zhao, et al. “Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models.” arXiv:2601.18734, 2026.
[97] Chujie Zheng, et al. “Group Sequence Policy Optimization.” arXiv:2507.18071, 2025.
[98] Yuxin Zuo, et al. “MedXpertQA: Benchmarking Expert-Level Medical Reasoning and Understanding.” arXiv:2501.18362, 2025.