How Frontier Labs Train Large Language Models
Table of Contents
- Why read the tech reports?
- The shape of a frontier model
- Data: the real moat
- Pre-training: scaling, precision, stability
- Post-training I: SFT, cold-start, and distillation
- Post-training II: RL, the engine of reasoning
- Alignment: helpfulness, safety, honesty
- Evaluation: measuring the climb
- Safety and red-teaming
- The convergent recipe
- Open challenges
Why read the tech reports?
For most of the deep-learning era, how a frontier model is actually trained was the industry’s best-kept secret: a few sentences in a system card, a parameter count, a benchmark table. You could read every paper and still not know how to build one. That has changed. Across 2024-2026 a remarkable thing happened: lab after lab published a genuine end-to-end technical report — not a teaser, but the data pipeline, the architecture ablations, the optimizer, the reinforcement-learning recipe, the reward design, the evaluation methodology, and the safety process. DeepSeek (V3, V3.2, R1), Qwen3, Kimi K2 and k1.5, Meta’s Llama 3, Google’s Gemma, Microsoft AI’s MAI-Thinking-1, Zhipu’s GLM-4.5, Alibaba, Moonshot, Xiaomi’s MiMo, Tencent’s Hunyuan, MiniMax, NVIDIA’s Nemotron, and the fully-open OLMo 2 / Tulu 3 — together they are an accidental textbook.
Read them side by side and the striking thing is not how different the labs are, but how convergent they have become. Strip away the branding and almost every report walks the same path:
Thesis. By 2026 there is essentially one recipe for training a frontier LLM — a standard pipeline from data → pre-training → mid-training → post-training (SFT then RL) → alignment → evaluation → safety. What separates the labs is no longer the skeleton; it is a small set of design choices (how to balance a mixture-of-experts, which RL algorithm variant, which rewards to trust, whether to use synthetic data, whether to distill) and a handful of hard-won tricks for staying stable at scale.
This post is that recipe, taught one stage at a time. We use Microsoft AI’s MAI-Thinking-1 report as a spine, because it is unusually candid and frames the whole enterprise nicely — as building a “hill-climbing machine”: the integrated system of data pipelines, training infrastructure, RL environments, evaluation suites, and safety tests that turns model development into an empirical optimization loop. At each stage we ask the same question — how does MAI do it, and how does everyone else? — and let the other reports agree, disagree, and occasionally contradict each other.
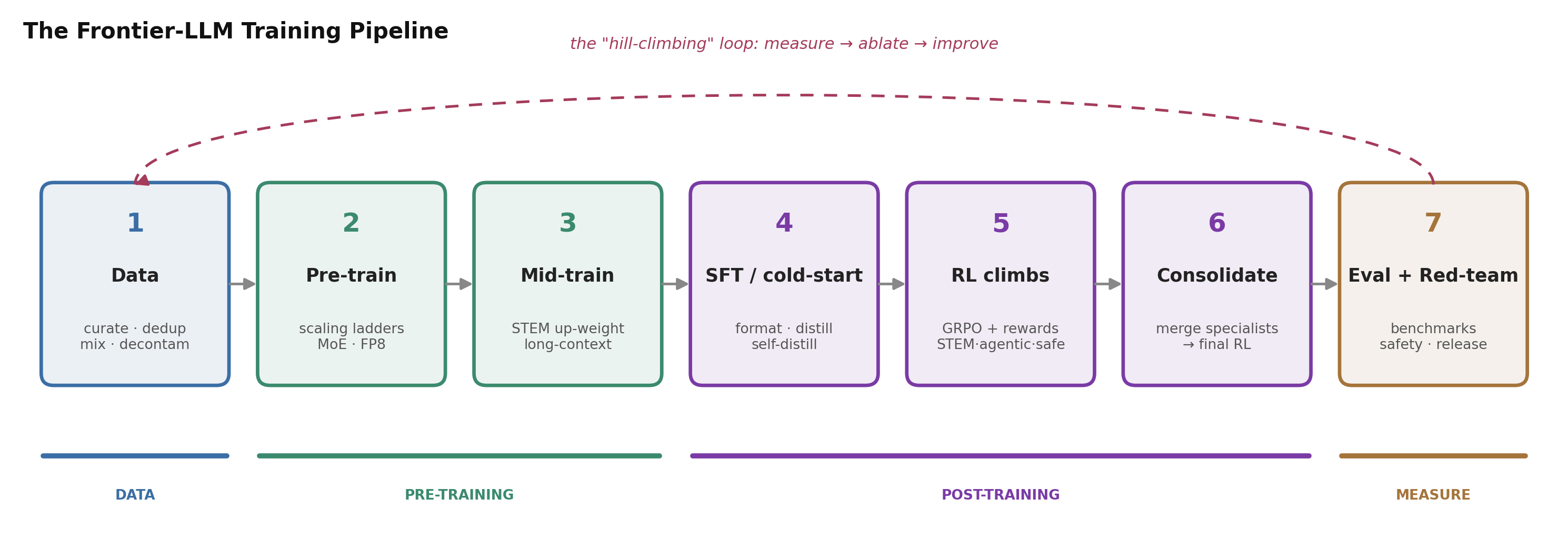 Figure 1. The recurring pipeline this post follows. Data is curated, the base model is pre-trained and then mid-trained, post-training adds SFT and several RL “climbs” that are consolidated into one model, and everything is measured by evaluation and red-teaming — whose results feed the next iteration. Every lab in this post instantiates this same skeleton; they differ mainly in the knobs.
Figure 1. The recurring pipeline this post follows. Data is curated, the base model is pre-trained and then mid-trained, post-training adds SFT and several RL “climbs” that are consolidated into one model, and everything is measured by evaluation and red-teaming — whose results feed the next iteration. Every lab in this post instantiates this same skeleton; they differ mainly in the knobs.
A note on how to read these reports skeptically. A technical report plays two roles at once. It is a product announcement — so the benchmark tables are chosen to flatter — and it is a reproducible recipe — so the methods sections are where the real signal lives. The fully-open efforts (OLMo 2, Tulu 3, Nemotron) disclose what the others must paraphrase, so we lean on them whenever a closed report gets vague. And throughout, keep one distinction in mind that we will return to constantly: the difference between what a lab claims helps and what it actually ablated and measured. The good reports are mostly the latter.
Takeaway. The 2024-2026 tech reports have converged on a single end-to-end recipe; this post teaches that recipe stage by stage, using MAI-Thinking-1 as a spine and the other labs as a cross-checking chorus.
The shape of a frontier model
Before the pipeline, the artifact. If you opened the config of MAI-Thinking-1, DeepSeek-V3, Qwen3, Kimi K2, Llama 3, and Gemma 3 side by side, you would be struck by how similar they are. The decoder-only Transformer has converged to a near-universal block, and the 2024–2026 reports treat that block as boilerplate — they spend their architecture sections on the two things that are still live: how to be sparse (mixture-of-experts) and how to make attention cheap at long context.
The settled core
Every model in this post is a decoder-only Transformer built from the same five parts, each of which “won” a years-long bake-off:
- RoPE for position — rotary embeddings encode relative distance and extrapolate cleanly, which is why all of them then stretch context with RoPE-base scaling / YaRN (Su et al., 2021).
- GQA for the KV-cache bottleneck — grouped-query attention gets most of full attention’s quality at a fraction of the decode-time memory (Ainslie et al., 2023).
- SwiGLU for the feed-forward layer — a gated activation that buys free quality at fixed FLOPs (Shazeer, 2020).
- RMSNorm for normalization — LayerNorm quality without the mean-centering cost (Zhang & Sennrich, 2019) — now routinely paired with QK-norm (RMSNorm on the queries and keys) and a small z-loss, the two cheap stabilizers that a small-scale study showed prevent the attention-logit and output-logit blowups that kill big runs (Wortsman et al., 2023).
Consensus. RoPE + GQA + SwiGLU + RMSNorm + QK-norm is the modern decoder block. MAI-Base-1 is a textbook instance of it; so is essentially every other base model here. The only block-level knobs left are norm placement (pre-norm vs Gemma’s and OLMo 2’s pre+post / reordered norm) and how aggressively attention is sparsified.
The big shift: dense to mixture-of-experts
The real architectural story of this era is the migration from dense models to mixture-of-experts (MoE): replace the FFN with many “expert” FFNs and route each token to a few of them, so total parameters (capacity, which holds knowledge) decouple from active parameters (the per-token compute). The design that everyone copied came from DeepSeekMoE (Dai et al., 2024): two ideas, fine-grained expert segmentation (slice the FFN into many small experts and activate more of them — combinatorially more routing options at fixed FLOPs) and shared-expert isolation (a always-on expert that absorbs common knowledge so the routed experts can specialize). DeepSeek’s ablation is quotable: disabling the shared expert spikes loss, and a fine-grained model degrades more when you remove its top experts — evidence the experts really did specialize.
By 2026 this is the default. DeepSeek-V3 runs 1 shared + 256 routed (8 active) experts; Kimi K2 pushes it to 1.04T total / 32B active across 384 experts; Qwen3 drops the shared expert; MAI-Thinking-1 interleaves high-sparsity MoE layers with dense FFN layers (and finds that pairing beats medium-sparsity-everywhere on wall-clock); Llama 3 is the conspicuous dense holdout, choosing a 405B dense model explicitly “to maximize training stability.”
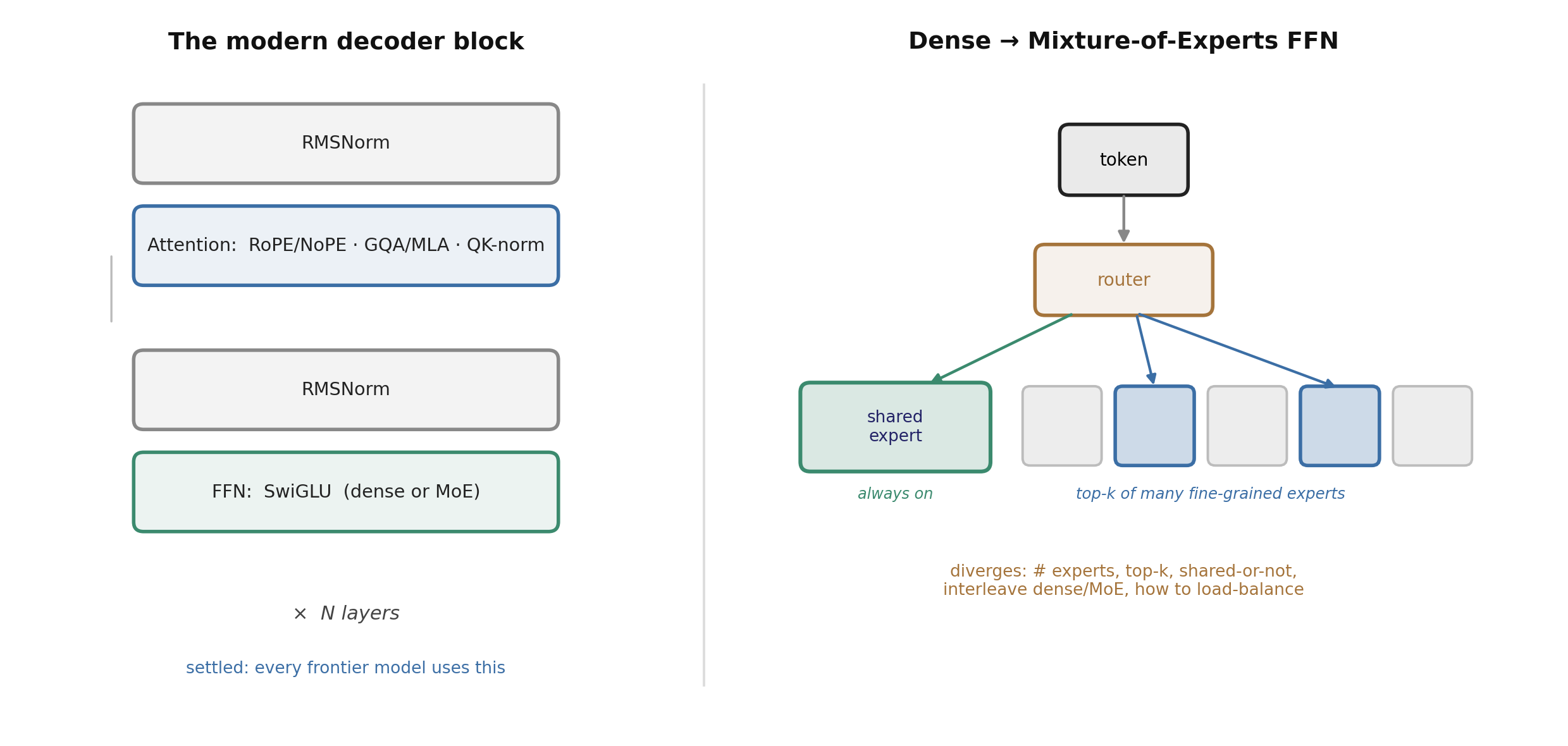 Figure 2. The converged decoder block (left) and the dense→MoE feed-forward shift (right): a token is routed to a few fine-grained experts plus an always-on shared expert. Labs differ in expert count, top-k, whether a shared expert exists, and how layers interleave dense and MoE.
Figure 2. The converged decoder block (left) and the dense→MoE feed-forward shift (right): a token is routed to a few fine-grained experts plus an always-on shared expert. Labs differ in expert count, top-k, whether a shared expert exists, and how layers interleave dense and MoE.
Where labs still disagree
Two axes remain genuinely contested, and they are where the engineering effort goes.
Attention efficiency. GQA is the baseline, but the frontier is a menagerie of ways to shrink the KV cache or the quadratic cost: DeepSeek’s Multi-head Latent Attention (MLA) (DeepSeek-V2) compresses KV into a low-rank latent (a smaller cache than GQA at better quality), later extended with DeepSeek Sparse Attention to make long-context attention sub-quadratic (DeepSeek-V3.2); Gemma 3 and MAI interleave 5 local : 1 global attention layers so only every sixth layer pays the long-range cost; MiniMax-M1 goes furthest with a 7:1 lightning(linear)-attention hybrid that makes 1M-token context — and cheap long-CoT RL — affordable; Hunyuan combines GQA with cross-layer attention for ~95% KV savings; gpt-oss adds attention sinks. MAI even drops positional encoding entirely on its global layers (NoPE), finding it as good as RoPE but cheaper. By 2026 this had become the race: sparse/compressed attention plus 1M-token context is now table stakes — DeepSeek-V4 ships a Compressed-Sparse + Heavily-Compressed Attention hybrid, GLM-5 adopts DeepSeek’s DSA (and GLM-5.2 adds “IndexShare” to cut 1M-context FLOPs ~2.9×), all chasing the same goal of long context that’s cheap enough to train RL on, not just serve.
MoE load balancing. Routed experts must stay balanced or training collapses and GPUs idle. There have been three eras of the same problem: the original auxiliary-loss (add a balance penalty to the objective — GShard); DeepSeek’s auxiliary-loss-free scheme (move balancing out of the gradient into a per-expert routing bias, which gives better quality and more specialization, Wang et al., 2024); and Qwen’s global-batch aggregation insight that the bug nobody noticed was computing the balance loss per micro-batch, which silently destroys expert specialization (Qiu et al., 2025).
Divergence — what you balance over matters more than how. MAI runs a GShard-style loss but aggregates expert frequencies across the global batch, and reports the punchline directly: “the aggregation strategy matters much more than the load-balancing-loss type.” So the modern answer is less about loss-vs-bias and more about balancing over a diverse enough population of tokens.
One last trick worth knowing because it recurs: multi-token prediction (MTP), where the model is trained to predict the next few tokens. DeepSeek-V3 introduced it for denser training signal and a free ~1.8× speculative-decoding speedup; MiMo and Nemotron adopt it. The standout optimizer story — Muon and Kimi’s MuonClip — belongs to the next section.
| Axis | The consensus | Where labs diverge |
|---|---|---|
| Position | RoPE (+ YaRN/ABF scaling) | NoPE on global layers (MAI); none in attention (Nemotron’s Mamba) |
| Attention | GQA | MLA (DeepSeek, Kimi K2); periodic local/global (Gemma 3, MAI 5:1); lightning/linear (MiniMax 7:1); sparse DSA (DeepSeek-V3.2); sinks (gpt-oss); GQA+CLA (Hunyuan) |
| FFN / Norm | SwiGLU; RMSNorm + QK-norm | pre vs pre+post / reordered norm (Gemma, OLMo 2); logit soft-cap (Gemma 2) |
| Sparsity | fine-grained + shared-expert MoE | dense (Llama 3); no shared expert (Qwen3); interleaved dense/MoE (MAI); LatentMoE (Nemotron, MAI); Mamba-MoE (Nemotron) |
| Balancing | global-batch aggregation | aux-loss → aux-loss-free bias → global-batch |
Table 1. The architecture has ~80% converged; the remaining knobs are MoE shape and attention efficiency, and that is exactly where each lab spends its cleverness.
Takeaway. The block is settled (RoPE/GQA/SwiGLU/RMSNorm/QK-norm); the live architecture game is mixture-of-experts shape and cheap long-context attention, where a handful of distinct bets (MLA, local/global, linear/lightning, sparse) coexist.
Data: the real moat
If architecture is ~80% commoditized, data is where models actually differ — and, not coincidentally, it is the stage every lab is most guarded about. The closed reports give you a token count and a sentence (“a diverse mixture of public and licensed data”); the fully-open recipes (OLMo 2, Tulu 3, Nemotron) give you the whole funnel. Put together, the pipeline is remarkably consistent: a raw crawl is filtered and deduplicated down by more than an order of magnitude, then re-mixed by a quantitative recipe.
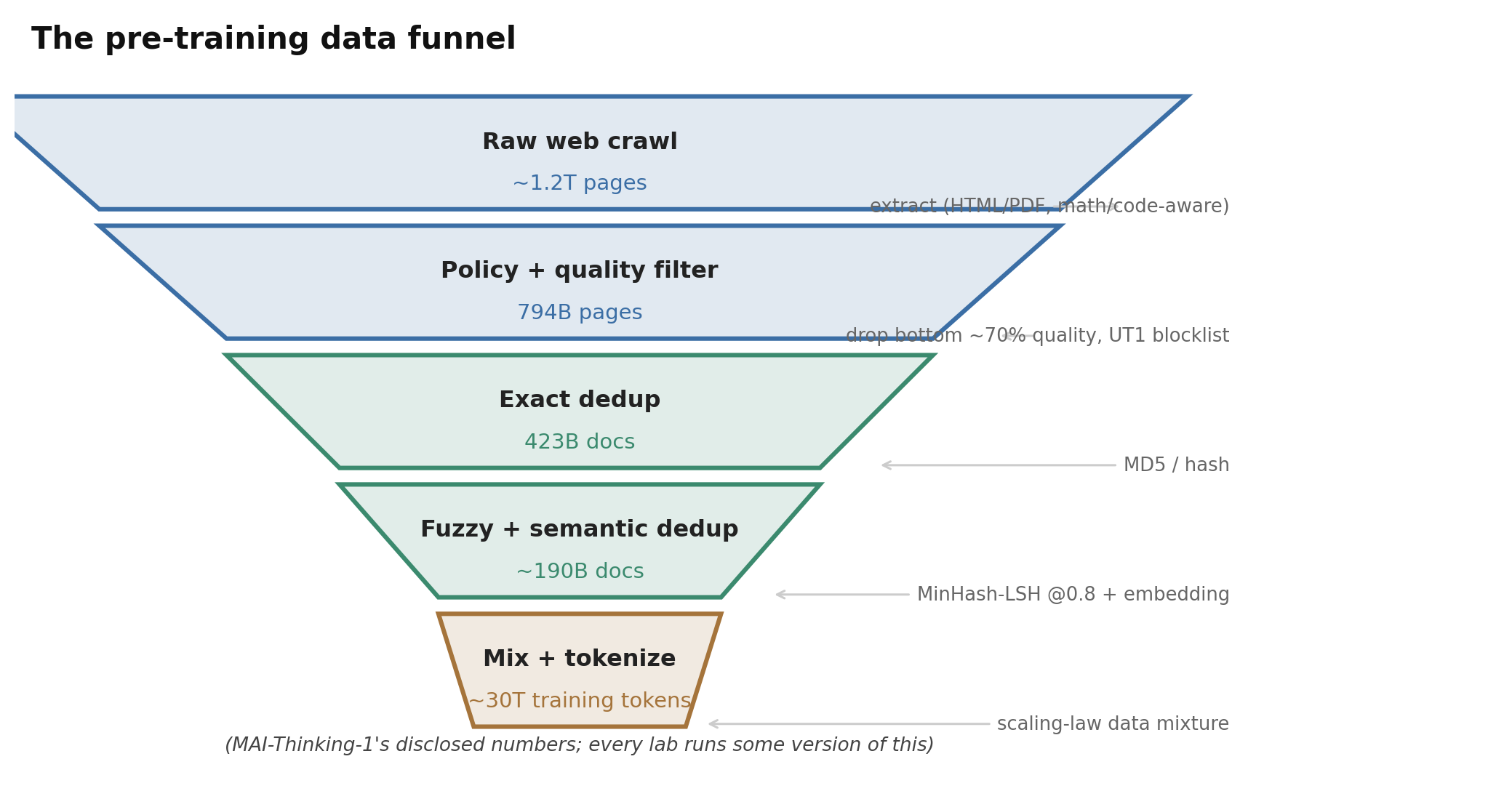 Figure 3. The data funnel, with MAI-Thinking-1’s disclosed numbers as the concrete example: ~1.2T crawled pages are filtered for policy and quality, deduplicated several ways, and re-mixed into the ~30T training tokens. Every lab runs some version of this; the percentages and the synthetic-data policy are where they part ways.
Figure 3. The data funnel, with MAI-Thinking-1’s disclosed numbers as the concrete example: ~1.2T crawled pages are filtered for policy and quality, deduplicated several ways, and re-mixed into the ~30T training tokens. Every lab runs some version of this; the percentages and the synthetic-data policy are where they part ways.
Extraction is underrated. The content labs most want — math, code, tables — is exactly what naive HTML-to-text pipelines mangle. So the good reports describe bespoke extractors: MAI normalizes MathML and LaTeX to Markdown and uses an LLM that may only keep or remove spans (never add synthetic text); Llama 3 built a custom parser that preserves code/math structure and even keeps image alt text for equations; MiMo and Llama both note that generic filters wrongly throw away math/code-heavy pages. The payoff shows up in purpose-built corpora — StarCoder2 / The Stack v2 for code, Nemotron-CC-Math for mathematics — where careful extraction is most of the value.
Deduplication is multi-stage and load-bearing. The reports converge on a stack: boilerplate removal, exact (hash) dedup, MinHash-LSH fuzzy dedup (~0.8 similarity), templated-page skeletonization, and increasingly embedding/semantic dedup in the lineage of SemDeDup and D4, which showed you can drop ~half of web data with no quality loss, and that smart repetition beats random fresh tokens. MAI runs all of these plus a cross-dataset drop-order so the same document isn’t counted twice across sources; it reports the funnel explicitly (1.2T pages → 794B after filtering → 423B after exact dedup → ~190B after fuzzy).
Filtering and categorization turn a pile into a controllable corpus. Labs score every document with cheap classifiers — fastText and embedding models for language, topic, educational value/level, and quality — so the corpus becomes a set of labeled buckets they can mix. Essential AI’s Essential-Web takes this to its logical end: label the whole web once with a distilled taxonomy classifier, then curate any domain with a SQL-style filter instead of training a new classifier each time — exactly MAI’s “organize the corpus into interpretable dimensions” philosophy.
Data mixing has become a quantitative discipline. The domain mix (how much web vs code vs math vs multilingual) strongly determines capability, and labs no longer set it by hand. Data Mixing Laws (Ye et al., 2024) showed validation loss is a predictable function of the mixture proportions — fit it on small “swarm” runs, then optimize; RegMix and OLMix productionize this (OLMix adds reuse for evolving domain sets). MAI ran 183 models across 3 scales over 61 mixtures to map the Pareto frontier; Llama 3 picked roughly 50% general / 25% math-and-reasoning / 17% code / 8% multilingual via scaling-law experiments; MiMo ran a deliberate 3-stage mixture that ramps math+code to ~70%.
Open question — small-scale rankings can lie. The appealing assumption behind cheap mixture search is rank invariance: if mix A beats mix B at small scale, it beats it at large scale. MAI reports this breaking — a code-heavy and a STEM-heavy mixture swapped order between 5B and 23B models. Mixtures may need to be chosen by their scaling behavior, not a single small-scale bake-off.
The sharpest disagreement in this whole post lives here:
Divergence — synthetic vs human data. MAI takes the contrarian hard line: no LM-generated synthetic data in pre-training, and an active effort to detect and remove AI-generated content from the crawl (a bet that clean human data avoids a model-collapse / homogenization trap). The opposite pole is everywhere too: Hunyuan-Large trains on ~1.5T synthetic tokens from a 4-step generate-evolve-filter pipeline; Persona Hub scales synthetic diversity with a billion personas; Qwen and Nemotron lean on synthetic rephrasing and distillation. MiniMax splits the difference (avoids synthetic in pre-training, like MAI). This is genuinely unresolved, and it is the cleanest “the labs disagree” moment to flag.
Finally, decontamination — keeping eval benchmarks out of training — is the quiet crisis under all of this. As benchmarks leak onto GitHub and into crawls, contamination produces flattering, fake numbers. Labs handle it coarsely: MAI removes all huggingface mirrors and applies universal 20-gram fuzzy dedup, and — the move everyone is converging on — relies on private, held-out benchmarks they are confident aren’t on the web. We return to this in Evaluation.
Takeaway. Data is the least-shared, highest-leverage stage: a converged funnel (extract → dedup → classify → mix) sits atop two unresolved questions — how much synthetic data to trust, and whether your eval set has already leaked into training.
Pre-training: scaling, precision, stability
With data in hand, pre-training is now an engineering discipline organized around three questions: how big and how long (scaling), in what number format (precision), and how to keep a months-long run from diverging (stability). Plus a fourth stage that barely existed two years ago: mid-training.
Scaling: from Chinchilla to deliberate over-training. The 2020 Kaplan laws said loss is a smooth power law in parameters, data, and compute, and recommended spending most of a budget on parameters — the era of Gopher and PaLM. Chinchilla corrected this: for a fixed training budget, scale parameters and tokens together, ~20 tokens per parameter. But 20 TPP is training-compute-optimal, not deployment-optimal — once you amortize a model over billions of inference tokens, the right move is a smaller model trained far past 20 TPP. So the field deliberately over-trains: Llama-3-8B sees ~15T tokens (~1900 TPP); MAI runs its main model at 500–1000 TPP for a compact, inference-cheap result while ablating architecture near the Chinchilla-optimal region. MAI formalizes the methodology nicely with a scaling ladder (train a family at constant tokens-per-active-parameter) and an Efficiency-Gain metric (how much more compute the baseline would need to match a candidate) so that every change is justified by its scaling curve, not a single data point.
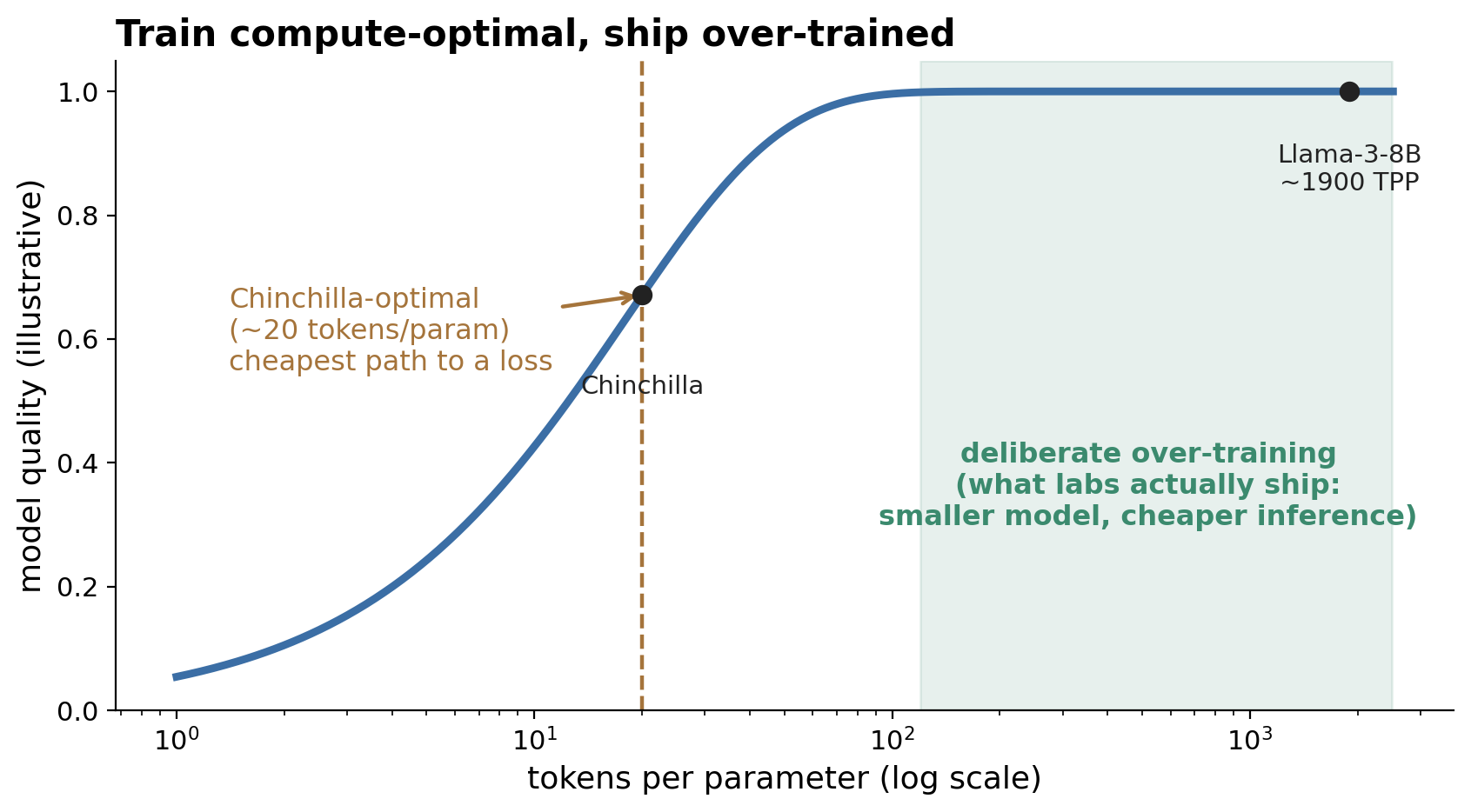 Figure 4. Chinchilla says scale parameters and tokens together (~20 tokens/param) for the cheapest path to a loss; inference economics push labs to pick a smaller model and over-train it far to the right. Labs ablate near compute-optimal but ship deep in the over-trained regime.
Figure 4. Chinchilla says scale parameters and tokens together (~20 tokens/param) for the cheapest path to a loss; inference economics push labs to pick a smaller model and over-train it far to the right. Labs ablate near compute-optimal but ship deep in the over-trained regime.
Consensus — over-train for inference. Nobody trains compute-optimal anymore. The shared logic: training is paid once, inference is paid forever, so trade extra training tokens for a smaller, cheaper model. The open edge of this is the data wall — at extreme TPP you run out of unique high-quality tokens, which loops back to the synthetic-data debate.
Precision: BF16 → FP8 → FP4. Training precision has marched down from the FP16 mixed-precision era (Micikevicius et al., 2017) through BF16 (Zamirai et al., 2020) to today’s frontier. The most visible efficiency shock was DeepSeek-V3 training a 671B model in FP8 — using FP8 formats (E4M3 forward, E5M2 backward) with fine-grained tile/block-wise scaling to tame outliers — for a total of ~$5.6M, with a relative loss error under 0.25% vs BF16 (helped by tricks like stochastic rounding). NVIDIA’s Nemotron 3 pushes further to NVFP4 (4-bit), stable to 25T tokens via layer-by-layer precision rules (keep the last ~15% of the network high-precision), and gpt-oss ships MXFP4 MoE weights so a 120B model fits on one GPU. MAI trains in FP8 too. The holdouts are instructive: Llama 3 stayed in BF16 for robustness — a recurring “stability over efficiency” theme.
Divergence — the optimizer monopoly is cracking (and Muon is winning). For a decade, AdamW was the only answer. Now Muon (Liu et al., 2025) — which orthogonalizes the momentum update via a Newton–Schulz iteration and matches AdamW’s update RMS — claims ~2× compute efficiency, and the flagships are switching: GLM-4.5/GLM-5 use Muon, Kimi K2 uses MuonClip (Muon + a QK-Clip that rescales the query/key projections to cap attention logits; a 15.5T-token trillion-parameter run with zero loss spikes), and as of 2026 even DeepSeek-V4 (2026) — long an AdamW shop — adopts Muon “for faster convergence and greater training stability.” AdamW still trains MAI, Qwen, and Llama, but the momentum (pun intended) is clearly with Muon — the most consequential optimizer shift in years.
Stability is its own research area. A thousand-GPU, months-long run dies from loss spikes, diverging logits, or even hardware bit-flips. The cheap, near-universal fixes — QK-norm and z-loss — come from the small-scale-proxy study (Wortsman et al., 2023), and the fully-open OLMo 2 report is the best public catalogue of the rest: a repeated-n-gram document filter to kill spike-inducing data, a std-0.02 initialization, AdamW ε lowered to 1e-8, reordered (pre+post) norm, no weight decay on embeddings — each with a measured reduction in their “spike score.” MAI’s infra layer adds determinism and silent-data-corruption handling. None of this appears in a closed system card.
Mid-training is the new stage. Between raw pre-training and post-training, labs now insert a mid-training phase that up-weights STEM/math/code on high-quality (often annealed) data and extends context to 128K–256K. This is not cosmetic: OctoThinker shows mid-training decides whether a base model is even RL-ready — the same RL recipe makes Qwen soar and Llama stall, and reasoning-dense mid-training closes the gap. MAI runs an explicit mid-training stage (STEM up-weight, context to 256K) precisely to “build a strong foundation for reasoning RL”; DeepSeek, Qwen, and MiMo all do their own version (MiMo’s 3-stage mixture, Llama’s high-quality “annealing” tail).
Takeaway. Pre-training is engineering now: ladder-and-EG scaling with deliberate over-training, FP8/FP4 precision, a small stability toolkit (QK-norm, z-loss, careful init), and a mid-training stage that quietly determines the RL ceiling — with the AdamW-vs-Muon optimizer question newly open.
Post-training I: SFT, cold-start, and distillation
Pre- and mid-training give you a base model with broad competence but no idea how to behave — how to follow instructions, reason before answering, or use tools. Post-training fixes that, and it has settled into a two-act structure: a supervised stage that sets the starting point, then reinforcement learning that does the climbing (next section). This section is about the starting point, where the deepest philosophical disagreement in the whole pipeline lives.
What SFT is actually for. It is tempting to think supervised fine-tuning is where capability comes from. In the modern recipe it is mostly a readiness gate: teach the model the chat/tool format and seed it with enough competence to produce some good rollouts, so RL has signal to amplify. Over-do it and you ossify the policy and kill the exploration RL needs; under-do it and RL has nothing to push on. The instruction data itself is increasingly synthetic — the lineage runs from WizardLM’s Evol-Instruct (have an LLM rewrite seed instructions to be harder and more diverse) through persona-driven generation and constraint taxonomies.
The “cold start” and the pure-RL surprise. The most influential post-training result of the era is DeepSeek-R1 (DeepSeek-AI, 2025). Its R1-Zero variant applied GRPO directly to the base model with no SFT at all, rewarded only by rule-based verifiable signals — and reasoning emerged: AIME accuracy climbed from 15.6% to 77.9%, response length grew on its own, and the model spontaneously developed self-checking (the famous “aha moment,” a spike in the word “wait”). The catch was readability and language-mixing, which the full R1 fixes with a small cold-start SFT (a few thousand curated long-CoT examples) before RL. That template — optional cold-start → RL → reject- sample → RL — is now standard (Qwen3, Kimi, MiMo, Magistral, MAI all run a version).
Self-improvement is how you make SFT data at scale. When you can verify answers, you don’t need humans to write reasoning traces — the model writes its own and you keep the good ones. This is one idea in three dresses: STaR (Zelikman et al., 2022) filters self-generated correct rationales; LMSI (Huang et al., 2022) filters by self-consistency with no labels; ReST-EM (Singh et al., 2023) shows the generate→filter→SFT loop is expectation-maximization and beats training on human data whenever you can check correctness. Llama 3’s rejection-sampling and Tulu 3’s pipelines are direct descendants, and related self-correction engines (Self-Refine, Chain-of-Verification) feed the same loop.
Self-distillation as a save-point. A newer, subtler use is keeping a thousand-step RL run alive. MAI leans heavily on self-distillation: periodically SFT a fresh checkpoint on the RL run’s own rollouts, then resume RL. They use it to move from a raw prompt to the chat format, to recover from collapses (resuming from a pre-crash checkpoint fails because the instability was already baked into the weights), and to carry progress onto a new base model. Their ablations are quotable — ~1M traces suffice, incorrect-answer traces work about as well as correct ones, and traces from a range of late checkpoints beat traces from the single final policy. The technique has a clean formalization in on-policy self-distillation (Zhao et al., 2026).
Why does any of this work — why does the same RL help one base model and not another? Because RL mostly amplifies behaviors the base model already has. The “cognitive behaviors” study (Gandhi et al., 2025) shows that verification, backtracking, subgoal-setting, and backward-chaining are present in Qwen and largely absent in Llama, and that priming Llama with those behaviors (even via incorrect but well-structured traces) makes it RL-trainable. This is the deep reason mid-training and cold-start matter: they install the behaviors RL will sharpen.
Divergence — inherit vs learn. The dominant move in 2025 is distillation: R1’s 800K long-CoT traces, SFT’d into small Qwen and Llama models, beat large-scale RL from scratch at the same size — so DeepSeek even distills R1 back into V3’s own SFT data, and most labs distill from a strong reasoner somewhere. MAI takes the opposite stance as a founding principle: “capabilities should be learned, not inherited,” refusing to distill from third-party models because (they argue) imitated intelligence lacks the steerability and robustness needed for long climbs. It is the cleanest philosophical fork in the field: distillation is cheaper and often better per dollar, but only RL can explore beyond any teacher.
Takeaway. SFT/cold-start sets the starting point and installs RL-ready behaviors; verification turns the model into its own data factory (STaR/ReST-EM/self-distillation). The open question is inherit vs learn — distill from a stronger model, or grow capability with RL from your own base.
Post-training II: RL, the engine of reasoning
This is the heart of the modern recipe and the part that changed most in 2024–2026. Supervised learning can only imitate the trajectories in its dataset; reinforcement learning lets the model generate its own attempts and be scored by a reward, which is what makes long-horizon reasoning and tool use trainable. The remarkable thing is how standardized — and how fragile — this stage has become.
From PPO to GRPO
Classic RLHF used PPO (Schulman et al., 2017), whose clipped surrogate objective is still the substrate everything inherits: maximize the reward-weighted probability ratio, but clip the ratio to a trust region so a single update can’t move too far. PPO needs a value model (a second, policy-sized network) to estimate the baseline for advantages — expensive, and awkward when the reward only arrives at the end of a long chain of thought.
GRPO (Shao et al., 2024, DeepSeekMath) is the move that defined the era: delete the value model and estimate the baseline from a group of sampled answers to the same prompt. For a prompt \(q\), sample \(G\) responses, score each with reward \(R_i\), and give every token of response \(i\) the group-relative advantage \(\hat A_i = (R_i - \text{mean}(R_{1..G})) / \text{std}(R_{1..G})\). That’s it — a Monte-Carlo baseline, no critic, and a perfect fit for cheap verifiable rewards. GRPO (or a close sibling) is now the RL backbone of DeepSeek-R1, Qwen3, MiMo, GLM-4.5, Magistral, Nemotron, and MAI-Thinking-1.
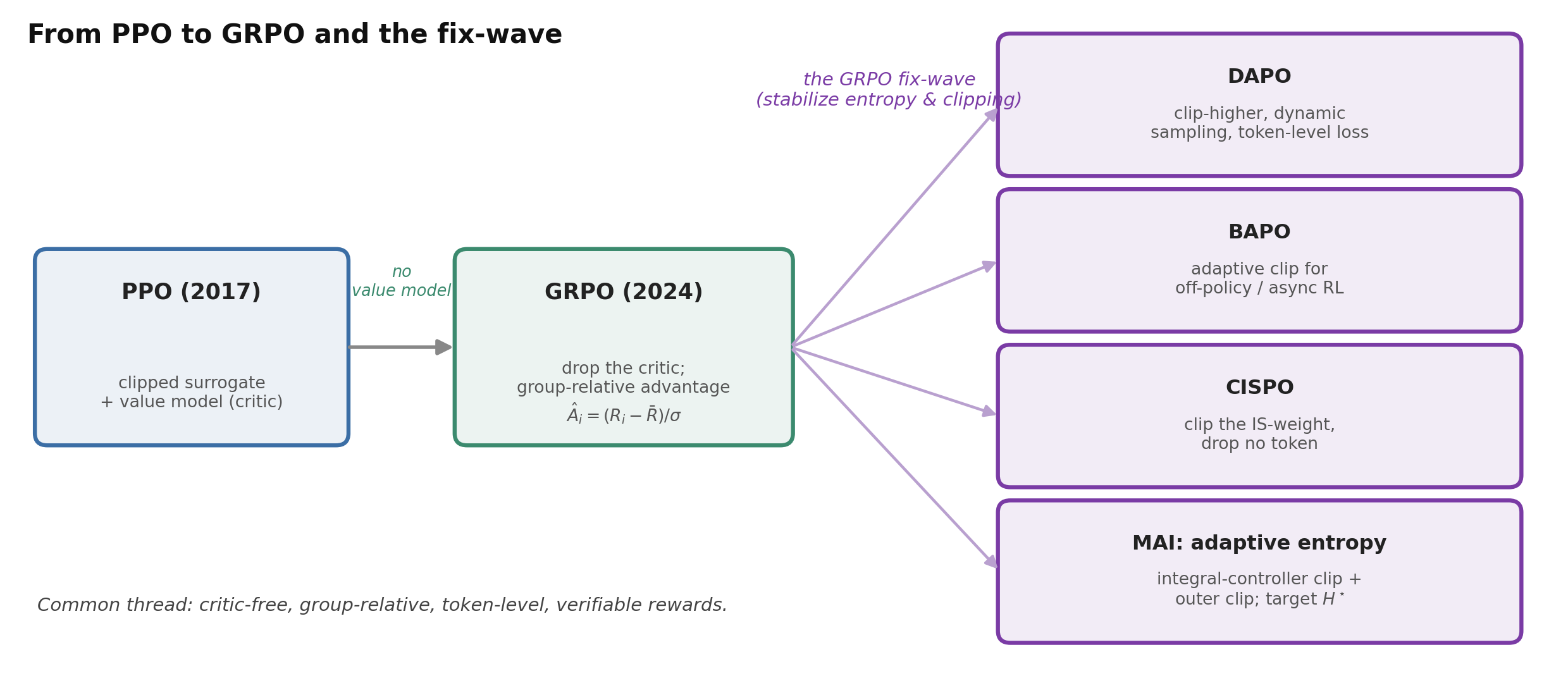 Figure 5. PPO’s clipped surrogate is the substrate; GRPO drops the value model for a group-relative baseline; then a wave of fixes (clip-higher, token-level loss, KL removal, adaptive-entropy / outer clip, CISPO) makes it stable for long-CoT and off-policy training. The algorithm is rarely the contribution — the stabilization is.
Figure 5. PPO’s clipped surrogate is the substrate; GRPO drops the value model for a group-relative baseline; then a wave of fixes (clip-higher, token-level loss, KL removal, adaptive-entropy / outer clip, CISPO) makes it stable for long-CoT and off-policy training. The algorithm is rarely the contribution — the stabilization is.
Consensus (through 2025) — the algorithm is a commodity, the stabilization is the work. Almost every lab adopted a GRPO-family, critic-free, group-relative, token-level objective with verifiable rewards. DeepSeek-R1’s own thesis says it plainly: the keys to reasoning are “hard questions, a reliable verifier, and sufficient compute” — not a clever loss. (As we’ll see, long-horizon agentic RL is now complicating this — including a partial return to the critic.)
Naive GRPO is fragile: the fix-wave
Reproducing R1-scale results revealed that vanilla GRPO collapses, and a wave of fixes followed — almost all about how the surrogate is normalized and clipped:
- DAPO (Yu et al., 2025) is the de-facto “GRPO++”: clip-higher (a looser upper clip so low-probability exploratory tokens can grow — preserving entropy), dynamic sampling (drop prompts with pass-rate 0 or 1, whose group advantage is zero), a token-level loss (normalize over all tokens, not per-sample, killing a length bias), and overlong-reward shaping. It also drops the KL term.
- Magistral (Mistral, 2025) and MiMo confirm the recipe: eliminate KL, length-normalize the loss, clip-higher, filter zero-advantage groups.
- BAPO (Xi et al., 2025) generalizes clip-higher to an adaptive controller for the off-policy regime that asynchronous infra creates.
- MiniMax’s CISPO clips the importance-sampling weight instead of the token update, so no rare reflective token is ever dropped — 2× faster than DAPO.
Divergence — keep or drop the KL term. A genuine split: drop the KL-to-reference for long-CoT reasoning (the policy should move far from init — DAPO, Magistral, MiMo, MiniMax), but keep it for RLHF alignment (stay near a trusted model — Tulu 3, and DeepSeek’s alignment stages). DeepSeek-V3.2 threads the needle with an unbiased KL estimator and very weak KL in math domains.
The long-horizon re-think: GSPO, and the return of the critic
For most of 2024–2025 the story above (“GRPO + a few fixes”) really was the whole story. But through 2026, as labs push from single-turn reasoning into long-horizon agentic RL — agents that run for hours, over dozens of tool calls — that consensus has started to crack in two interesting directions, and this is the most important update to the picture.
Direction 1 — go sequence-level (GSPO). GRPO’s importance ratio is per token, which on MoE models is noisy (a token’s experts can differ between the rollout and training passes) and forces the “router-replay” hack from earlier. Qwen’s Group Sequence Policy Optimization (GSPO) (Zheng et al., 2025) instead defines the importance ratio and clipping at the sequence level (length-normalized), which is more stable, matches the sequence-level reward, and — notably — eliminates the need for routing replay on MoE. Qwen reports GSPO behind the latest Qwen3 models; it is the cleanest “stay critic-free but fix GRPO’s unit of analysis” answer.
Direction 2 — bring back the critic (PPO). The sharper reversal comes from GLM. The slime-trained GLM line (GLM-5, Zhipu, 2026) starts on GRPO (plus an “IcePop” train/inference-mismatch fix), but Zhipu’s later GLM-5.2 explicitly abandons group-relative optimization for a critic-based PPO in its long-horizon stage. The reason is concrete and worth internalizing: when a very long agent trajectory is compacted into multiple sub-traces, different rollouts of the same prompt yield different numbers of trainable traces with wildly different lengths — so GRPO’s “compare a clean group of comparable rollouts” assumption breaks. A critic estimates token-level advantages for a single rollout, with no requirement that rollouts be group-comparable, which fits compaction naturally (paired with a token-level loss for length imbalance). After three years of everyone deleting the value model, the value model is coming back — for the long-horizon case.
Divergence — the algorithm is becoming task-specific again. The clean 2025 narrative (“GRPO won, the algorithm is a commodity”) is giving way to a 2026 one: GRPO/CISPO for short, verifiable tasks; GSPO for stable MoE RL; critic-based PPO for long, compacted, agentic trajectories. GLM-5.2’s return to PPO is the headline, but the deeper point is that trajectory length and structure now drive the choice of RL algorithm. Note DeepSeek-V4 (2026) takes yet another route — keep GRPO per-domain-expert, then fuse the experts with on-policy distillation — and MiniMax’s M2 (2026) builds a whole agent-native RL system (“Forge”) around long, uneven trajectories. There is no longer a single default.
The entropy problem
The single most important failure mode is entropy. Too little and the policy collapses to a deterministic, un-exploring model that saturates; too much and it spews gibberish and runaway length. The Entropy Mechanism study shows these are one phenomenon: \(\Delta H \propto -\text{Cov}(\log \pi, \text{advantage})\), and the fixed PPO clip systematically removes the entropy-increasing updates → monotone collapse, with a predictable ceiling (\(R = -a\,e^{H} + b\)). The fixes span where you intervene: at the clip (DAPO’s clip-higher; BAPO’s adaptive bounds; MAI’s adaptive entropy control — an integral controller that nudges the upper-clip relaxation toward a target entropy \(H^\star=0.3\)), at the covariance level (Clip-Cov / KL-Cov suppress the specific high-covariance tokens), or via an entropy bonus — which both the Entropy-Mechanism authors and MAI report underperforms the adaptive approaches.
Trick — entropy as a control loop. MAI’s contribution here is to treat entropy like a thermostat: measure it each step and adjust the clip width to hit a setpoint, rather than tuning a fixed bonus. It also adds a hard outer clip (\(r_{max}=50\)) on all branches to kill the catastrophic gradient spikes that GRPO’s deliberately-unclipped branches can cause.
Reward design: why verifiable rewards won
The reward is where RL succeeds or fails, and there are three sources, each hackable:
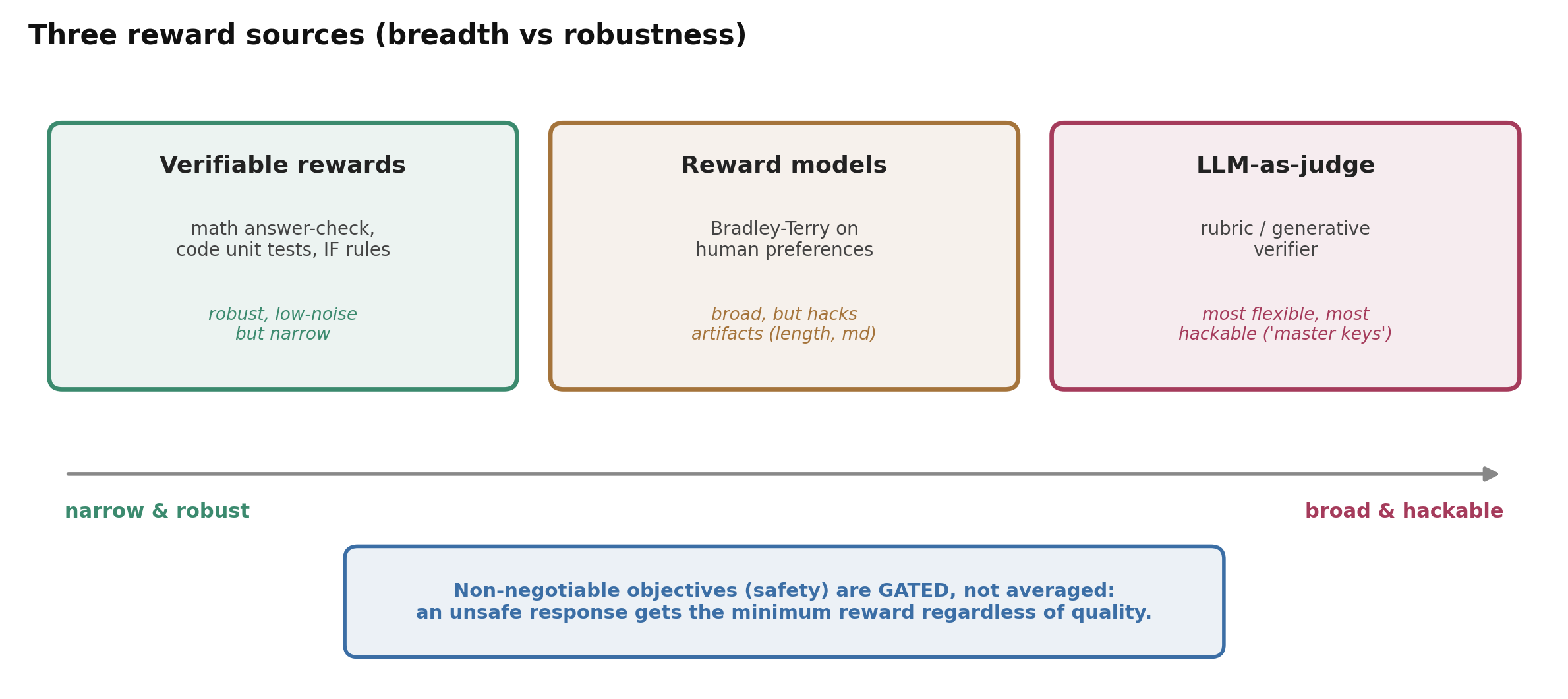 Figure 6. Three reward sources trade breadth for robustness. Verifiable rewards (math answer-checkers, code unit tests) are narrow but hard to game; reward models and LLM-judges cover open-ended tasks but get hacked. Non-negotiable objectives like safety are gated rather than averaged in.
Figure 6. Three reward sources trade breadth for robustness. Verifiable rewards (math answer-checkers, code unit tests) are narrow but hard to game; reward models and LLM-judges cover open-ended tasks but get hacked. Non-negotiable objectives like safety are gated rather than averaged in.
- Verifiable rewards — does the math answer match, do the unit tests pass — are cheap, low-noise, and hard to game at the reward level. This is why math and code dominate RL, and why Tulu 3 formalized RLVR (“the policy is only rewarded when verifiably correct,” with the blunt finding that verifiable-only beats reward-model + verifiable — the RM just adds hackable noise, Lambert et al., 2024). DeepSeek-R1 deliberately avoids neural reward models for exactly this reason.
- Reward models hack prompt-independent artifacts (length, markdown, emojis); robust-RM training via counterfactual augmentation (Liu et al., 2024) helps.
- LLM-as-judge is convenient for open-ended tasks but catastrophically foolable: a single meaningless token (“Solution”, “:”) can elicit a false “correct” up to ~80% of the time, even from frontier judges (Zhao et al., 2025).
So labs compose rewards, and the composition matters. MAI uses a decomposed reward \(R = R_{task} + w_{lang}R_{lang} - w_{len}R_{len}\) — adding a language-consistency reward (mixed- language CoTs destabilize training) and a difficulty-aware length penalty. And for non-negotiable objectives it gates rather than averages: an unsafe response gets the minimum reward regardless of quality (motivated by the finding that 87.8% of policy-non-compliant responses still scored ≥3 on the reward model — averaging would let quality buy back safety). We return to this in Alignment.
Difficulty ≠ trainability
A subtle but universal filter: which prompts are worth training on? Not the hardest — the learnable ones. For a binary outcome reward, the learning signal is the reward variance \(\hat p(1-\hat p)\), which is maximized at a 50% success rate and zero at both extremes: a prompt the policy always fails or always solves produces identical rewards across the group, so the group-relative advantage — and the gradient — is exactly zero.
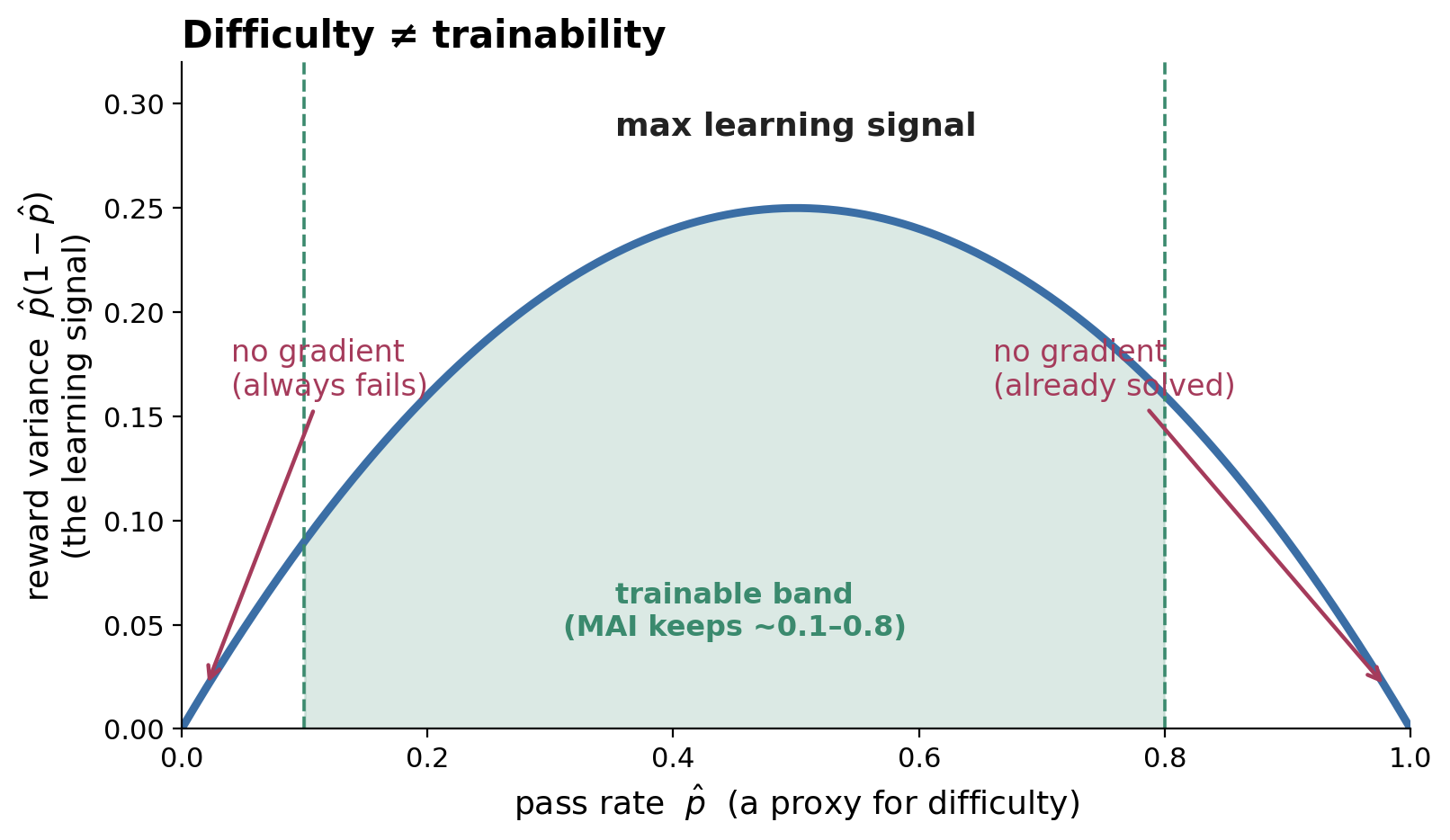 Figure 7. A prompt only teaches when its outcome is uncertain. The learning signal is the reward variance \(p(1-p)\): “too hard” and “too easy” fail for the same reason. Labs filter to a middle band.
Figure 7. A prompt only teaches when its outcome is uncertain. The learning signal is the reward variance \(p(1-p)\): “too hard” and “too easy” fail for the same reason. Labs filter to a middle band.
Every lab implements this. MAI filters prompts to a pass-rate band of [0.1, 0.8] (with an early-exit pre-filter to save rollout cost); DAPO’s dynamic sampling drops the {0,1} groups; MiMo keeps an easy-data pool to stabilize updates as more problems are mastered. This is the same idea that drives environment curricula in the agentic-RL world — explored at length in the companion post on environment scaling.
Spending tokens wisely, and agentic RL
Reasoning models “overthink,” so labs add difficulty-aware length penalties — penalize length in proportion to how easily a prompt is solved, so hard problems can think longer (Xiang et al., 2025; MAI adopts exactly this). Qwen3 exposes it to users as a “thinking budget.” And the frontier is agentic, multi-turn RL: the same GRPO objective over a trajectory of model-and-environment steps, run inside sandboxed containers with verifiable rewards (tests passing, a database reaching a target state). MAI’s “agentic climb” builds SWE environments from 102M GitHub PRs filtered to ~4.87M with linked issues, graded by fail-to-pass / pass-to-pass tests inside its on-demand sandbox; DeepSeek-V3.2 and Kimi K2 synthesize thousands of tool environments. The supply of these environments is its own deep topic — again, the environment-scaling post.
The unglamorous stability tricks
Finally, the fixes that don’t make the abstract but make the run converge: top-p mask replay (reuse the sampling truncation mask at train time so train and inference agree — MAI, DeepSeek-V3.2); MoE router replay (an MoE picks different experts in the inference vs training engine, an off-policy gap baked into the architecture — fixed by replaying routing, Ma et al., 2025; DeepSeek’s “Keep Routing”); an FP32 LM head to fix train/inference precision mismatch (MiniMax); async-RL staleness bounds; and self-distillation as a numerical save-point (previous section). Most labs build on (or replace) open RL frameworks like verl/HybridFlow and OpenRLHF — MAI wrote its own (“Rocket”) precisely because those didn’t scale to thousand-GPU asynchronous RL.
| Axis | The consensus | Where labs diverge |
|---|---|---|
| Order | SFT/cold-start → RL | pure-RL-from-base (R1-Zero, Magistral, MiMo-Zero) vs cold-start-first |
| Algorithm | GRPO family (critic-free, group-relative, token-level) | GSPO sequence-level (Qwen3); critic PPO for long-horizon (GLM-5.2); mirror-descent (Kimi); CISPO (MiniMax); DPO-only (Llama 3, Gemma 2, Hunyuan); PPO (Tulu 3, OLMo 2-7B) |
| KL term | drop for long-CoT | keep for RLHF alignment |
| Entropy | actively control it | adaptive clip (MAI/DAPO/BAPO) vs Clip-Cov/KL-Cov vs bonus (rejected) |
| Reward | verifiable rewards dominate | + RM + judge; gating vs weighted-sum; hacking mitigations |
| Filtering | drop {0,1}-pass-rate groups | dynamic sampling; difficulty-aware length penalty |
Table 2. The post-training/RL recipe: heavily converged on a GRPO-family verifiable-reward backbone, with real divergence on how much RL (vs DPO), whether to keep KL, and how rewards are composed.
Divergence — how much RL at all? Not everyone is in the RL-heavy camp. Llama 3, Gemma 2, and Hunyuan-Large deliberately rely on DPO / rejection-sampling / distillation and keep RL light or absent (Llama’s stated thesis is complexity management). DeepSeek, MAI, MiMo, and MiniMax bet the other way and pour compute into RL (DeepSeek-V3.2 now spends >10% of pre-training cost on RL, and rising). This — not the choice of GRPO variant — is the consequential fork.
Takeaway. RL is now a standardized but fragile engine: a GRPO-family, verifiable-reward, token-level objective, where the real work is reward design, entropy control, trainability filtering, and a pile of train/inference-consistency tricks. The big bets are how much to lean on RL and how to compose rewards.
Alignment: helpfulness, safety, honesty
Alignment used to be a final RLHF coat of paint. In the 2026 recipe it is its own set of RL “climbs” with a dedicated reward stack, run alongside the reasoning RL. The framing everyone now shares is a tension to optimize, not a filter to apply: a model must be helpful (comply) and safe (sometimes refuse) at once, and the art is getting both. MAI states the target as “helpful responses that remain compliant with policy”; OpenAI frames the same goal as moving from refusal to safe completion.
The reward stack here is the most heterogeneous in the pipeline, because the objectives (“is this helpful? honest? appropriately styled?”) resist verification. MAI’s helpfulness-and-safety climb combines a reward model trained on human preferences (with reward-hacking mitigations), AI judges (fast, rubric-guided, easy to retarget), and verifiable rewards wherever a constraint is checkable (e.g., “answer in under 10 words”) — the last specifically because verifiable signals are less hackable and stabilize the others.
Trick — gate safety, don’t average it. The single most transferable idea here: some objectives are non-negotiable, and a weighted sum lets a well-written answer buy back an unsafe one. MAI uses lexicographic / gated aggregation — a safety-noncompliant response gets the minimum reward regardless of its other scores — motivated by a damning audit: 87.8% of policy-noncompliant responses still scored ≥3 on the reward model. Averaging would have rewarded them.
Instruction hierarchy. Production models must rank instructions by privilege — system > developer > user > tool output — so an injected “ignore your instructions” in a web page can’t override the system prompt (Wallace et al., 2024, the basis of OpenAI’s Model Spec and gpt-oss’s harmony format). MAI trains this explicitly with adversarial system/developer/user conflicts; it is now a standard safety-SFT/RL ingredient.
Refusals → safe-completions. The clearest alignment evolution is OpenAI’s shift, documented in the GPT-5 system card, from binary hard refusals to output-centric safe-completions: maximize helpfulness subject to the safety policy, which is strictly better for dual-use questions where a high-level answer is fine but operational detail isn’t. gpt-oss adds deliberative alignment (the model reasons over the safety policy at inference). MAI’s safety climb, with its harmful-vs-borderline taxonomy and its explicit fight against over-refusal, is the same philosophy under a different name.
Honesty and calibration. A subtler alignment axis, and one most labs under-treat: a model should answer when it knows and hedge when it doesn’t — without over-hedging into uselessness. MAI’s honesty reward grades responses into five buckets (confident-correct → confident-incorrect), rewarding confident-correct most, penalizing confident hallucination most, and giving abstention a neutral score — explicitly discouraging over-hedging. This connects to a deeper problem (calibration, abstention, and uncertainty in long-horizon agents) that has its own companion post.
Divergence — how much to disclose. The methods are converging, but disclosure is not. OpenAI’s system cards are the eval/safety reference (Preparedness categories, red-team hours, safe-completions), yet reveal almost nothing about training; the open recipes (OLMo 2, Tulu 3, Magistral) disclose training in full but have thin safety sections. MAI sits in between, borrowing OpenAI’s safety grammar while disclosing far more of its recipe.
Takeaway. Alignment is now an RL objective with its own composed reward stack, defined by the helpfulness↔safety tension. The portable lessons: gate non-negotiable objectives instead of averaging them, train an explicit instruction hierarchy, prefer safe-completions over hard refusals, and reward calibrated honesty rather than blanket hedging.
Evaluation: measuring the climb
A “hill-climbing machine” can only climb a hill it can measure, which makes evaluation the quiet bottleneck of the whole pipeline. The reports reveal two different evaluation regimes: a cheap, robust one for development (thousands of decisions), and an expensive, public one for release.
For development, loss beats accuracy. MAI makes the strongest version of this argument: for the ~40-benchmark suite it uses to make pretraining and data-mixture decisions, it scores by NLL (loss), not accuracy. The reasons are operational and decisive — accuracy evals need expensive autoregressive generation and often a judge model; multiple-choice ability “emerges” only at large scale and so is noisy early; MATH needs exact \boxed{} formatting and MBPP trips on \n vs \r\n. NLL is the same teacher-forced next-token objective as training, so it is cheap and high-signal — a conclusion echoed by the Signal-and-Noise framework. The fully-open labs build dedicated dev suites (Ai2’s OLMES) for the same reason.
For release, the benchmark zoo. The public scorecards have standardized around a recognizable set: math (AIME, MATH, HMMT), science (GPQA, Humanity’s Last Exam), code (LiveCodeBench, SWE-bench and the harder SWE-bench Pro, Terminal-Bench), knowledge (MMLU and MMLU-Pro), factuality (SimpleQA, FActScore), long-context (RULER, LongBench v2, Michelangelo), agentic tool-use (τ²-bench, BFCL), and increasingly domain suites like HealthBench and MedXpertQA. The MAI report’s headline numbers (52.8% SWE-Bench Pro, 97.0% AIME 2025) live here, as do every other lab’s — but cross-report comparisons should be read with care, because harnesses, prompts, and tool access differ (one reason “tiny” curated subsets and uncertainty-aware scoring are gaining traction, e.g. tinyBenchmarks).
Open question — evaluation is the real bottleneck. As models saturate old benchmarks, the signal moves to a handful of hard, leak-prone sets. The honest labs increasingly rely on private held-out benchmarks (MAI builds its own; this is the only reliable defense against contamination), on verified re-releases of saturating sets (SimpleQA Verified), and on live evaluation that post-dates training (MathArena scoring fresh competitions). You can only climb what you can measure, and the measuring sticks are wearing out faster than we can make new ones.
Contamination is the crisis underneath. If a benchmark has leaked into training, your number is fiction — and MAI notes a telltale symptom: contamination can make a “coding” dataset mysteriously improve unrelated trivia. The countermeasures (20-gram fuzzy dedup, repo/temporal exclusion, removing HuggingFace mirrors) are imperfect, which is why private and live benchmarks are becoming the only trusted yardsticks.
Beyond benchmarks. Because automatable metrics miss style, helpfulness, and safety, labs add human side-by-side evaluations (MAI reports these prominently) and lean on LLM-as-judge — whose own reliability is now benchmarked (RewardBench, JudgeBench) precisely because, as we saw, judges are hackable.
Takeaway. Use cheap, robust NLL to make thousands of development decisions; use the public benchmark zoo plus human evals to report; and treat contamination as a first-class threat — private and live benchmarks are the only durable defense.
Safety and red-teaming
Alignment training (§ above) is the capability to be safe; this section is how labs measure and stress-test it before release. The grammar here was largely set by OpenAI’s Preparedness Framework and is now imitated everywhere: define a small set of tracked risk categories (GPT-4o: cyber, CBRN, persuasion, model-autonomy; GPT-5 and gpt-oss: bio/chem, cyber, AI self-improvement), assign capability levels, and gate deployment on a post-mitigation threshold reviewed by a safety board. Google’s Frontier Safety Framework and Anthropic’s RSP are siblings; MAI’s safety section borrows the same scaffolding.
Red-teaming is continuous and increasingly automated. It runs throughout development, not at the end. MAI sources adversarial prompts from human red-teams plus automated attack frameworks — PyRIT — and jailbreak methods like PAP (persuasion), Crescendo (multi-turn escalation), Tree of Attacks, and even multilingual jailbreaks. OpenAI reports red-teaming in hours and tester counts (GPT-5: 5,000+ hours, 400+ testers). Llama 3 ships an actual safeguard model, Llama Guard, alongside the LLM — safety as a system, not just a model.
Dangerous-capability evals target the catastrophic tail: bioweapon uplift (the recurring five-stage bio taxonomy), cyber-offense (CyberSecEval, CTF challenges), hazardous knowledge (WMDP, paired with unlearning), regulation-derived risk suites (AIR-Bench), and dedicated frontier dangerous-capability evals. gpt-oss adds a methodology specific to open weights: because anyone can fine-tune a released model, OpenAI built an adversarially fine-tuned “worst-case” version (helpful-only RL + capability maximization) and had external groups confirm it still didn’t cross High thresholds — the emerging template for responsible open-weight release.
The reasoning era adds a new safety lever: CoT monitoring. Because reasoning models think in legible chains of thought, you can monitor that reasoning for deception or misbehavior — GPT-5 reports halving flagged-deception rates (4.8%→2.1%) with a CoT monitor. But there’s a catch the field is actively worried about: if you train against the CoT monitor, the model learns to obfuscate its reasoning rather than behave (Baker et al., 2025; Guan et al., 2025). This makes “keep the chain of thought monitorable” a live design constraint for every lab training long-CoT models — MAI, DeepSeek, Magistral included.
The trend — safety shifts left. Across the reports, safety is no longer a release gate; it is woven through the pipeline: PII/CBRN data filtering (pre-training), the reward stack and instruction hierarchy (post-training), CoT monitoring (inference), and red-team + preparedness (release).
Takeaway. Safety has become a pipeline-wide process with a shared vocabulary (preparedness categories, automated red-teaming, dangerous-capability evals), and the reasoning era adds CoT monitoring — useful, but only as long as we don’t train models to hide their thoughts.
The convergent recipe
Step back from the stages and the claim from the top of the post holds up: by 2026 there is one recipe, and the reports are variations on it. Here is the whole pipeline in one breath — curate and dedup human-plus-synthetic data and choose the mixture by scaling-law forecasting; pre-train a RoPE/GQA/SwiGLU/RMSNorm MoE on a tokens-per-parameter ladder, deliberately over-trained, in FP8; mid-train on reasoning-dense data and extend context; SFT/cold-start to install behaviors and format; run GRPO-family RL with verifiable rewards, entropy control, and trainability filtering; align with a gated reward stack and an instruction hierarchy; measure with cheap NLL plus a contamination-guarded benchmark zoo; and red-team against a preparedness framework. If you internalize that sentence, every report in the table below reads like a fill-in-the-blanks.
| Model | Lab | Active/Total | Sparsity | Pretrain | Optimizer | RL / post-training | Data stance |
|---|---|---|---|---|---|---|---|
| MAI-Thinking-1 | Microsoft AI | 35B / ~1T | interleaved MoE | 30T | AdamW | GRPO + adaptive-entropy; 3 climbs → consolidate | human-only |
| DeepSeek-V3 | DeepSeek | 37B / 671B | MoE + MLA | 14.8T (FP8) | AdamW | GRPO; R1-distill into SFT | synthetic + human |
| DeepSeek-R1 | DeepSeek | 37B / 671B | MoE + MLA | (V3) | — | pure-RL → multi-stage; distills outward | — |
| DeepSeek-V4 | DeepSeek | 49B / 1.6T | MoE + CSA/HCA, 1M ctx | 32T+ | Muon | GRPO per-expert → on-policy distillation | synthetic + human |
| Qwen3 | Alibaba | 22B / 235B | MoE (no shared) | 36T | AdamW | GSPO + strong→weak distill; thinking budget | synthetic-heavy |
| Kimi K2 | Moonshot | 32B / 1.04T | MoE + MLA | 15.5T | MuonClip | mirror-descent RL; agentic | rephrase-synthetic |
| GLM-4.5 | Zhipu | 32B / 355B | MoE | 23T | Muon | GRPO (no KL) + expert-iteration | — |
| GLM-5 / 5.2 | Zhipu | 40B / 744B | MoE + DSA, 1M ctx | 28.5T | Muon | GRPO+IcePop → critic PPO (long-horizon) | — |
| Llama 3 | Meta | 405B | dense | 15.6T (BF16) | AdamW | SFT+RS+DPO (no PPO) | synthetic for code/math |
| Gemma 3 | 27B | dense (MM) | 14T | — | distillation + light RLVR | distill teacher | |
| MiMo-7B | Xiaomi | 7B | dense | 25T | AdamW | heavy GRPO from base | reasoning-dense synth |
| Hunyuan-Large | Tencent | 52B / 389B | MoE | 7T (~1.5T synth) | AdamW | SFT + DPO | synthetic-heavy |
| MiniMax-M1 / M2 | MiniMax | 10–46B / 0.23–0.46T | MoE + lightning-attn | +7.5T | AdamW | CISPO / Forge agent-RL | human (no synth pretrain) |
| OLMo 2 / Tulu 3 | Ai2 | 7–32B | dense | 4–6T | AdamW | SFT→DPO→RLVR | fully open |
| Nemotron 3 | NVIDIA | 3B+ | Mamba-MoE | 10T+ (NVFP4) | — | multi-env GRPO | open |
Table 3. One recipe, many fills. Reading across the columns, the consensus (MoE + modern block + SFT→RL + verifiable rewards) is visible — and so are the handful of real bets (dense vs MoE, AdamW vs Muon, GRPO vs GSPO vs PPO, RL-heavy vs DPO, synthetic vs human). The 2026 rows (DeepSeek-V4, GLM-5/5.2, MiniMax-M2) show the frontier moving toward 1M context, Muon, and long-horizon agentic RL.
What everyone agrees on (the eight points of consensus): the modern decoder block; fine-grained + shared-expert MoE balanced over the global batch; heavy dedup + scaling-law data mixing + a mid-training tail; deliberate over-training; SFT/cold-start → RL; GRPO-family verifiable-reward RL with entropy control and trainability filtering; multi-stage post-training with distillation somewhere; and a safety reward-stack + preparedness/red-team process.
Where the real bets are (the divergences worth arguing about): synthetic vs human data; inherit (distill) vs learn (RL); AdamW vs Muon (which, as of 2026, Muon is decisively winning — Kimi, GLM, and now DeepSeek-V4); aux-loss vs aux-loss-free vs global-batch balancing; dense vs MoE vs hybrid; how much RL vs DPO; the RL algorithm itself — GRPO vs GSPO (sequence-level) vs a return to critic-based PPO for long-horizon agents (GLM-5.2), which is the freshest and most telling shift; keep vs drop the KL term; refusals vs safe-completions; and how much to disclose (fully-open recipe vs benchmark-table-only card).
Takeaway. Read one report deeply and you have read them all — modulo about nine knobs. Those knobs, not the skeleton, are where the interesting disagreements (and probably the next advances) live.
Open challenges
The recipe works, but several of its load-bearing assumptions are shakier than the leaderboard numbers suggest. Here is where I’d point a skeptical eye.
Verification is the ceiling on RL. The entire RL stage rests on rewards you can trust, and we saw that reward models hack artifacts and LLM-judges fall to one-token “master keys.” That is why RL works so well in math and code and so poorly everywhere else — those are the domains with cheap, robust verifiers. Extending reliable verification to genuinely non-verifiable goals (“is this analysis good?”) is the open problem under most of the others.
The data wall meets the synthetic-data dilemma. Deliberate over-training and ever-larger token budgets are running into the finite supply of high-quality human text. The escape hatch is synthetic data — but that is exactly the bet MAI refuses, warning about training on AI-generated content. Whether synthetic data is a multiplier or a slow poison is unresolved, and the honest answer is probably “depends what for” (great for diversity and verifiable domains, risky as a wholesale pre-training substitute).
Contamination honesty. As benchmarks saturate and leak, it is increasingly easy — even unintentionally — to report inflated numbers. The field mostly assumes decontamination rather than proving it; private and live benchmarks help, but cross-lab comparability is quietly eroding.
The cost and fragility of thousand-step RL — and now the algorithm question reopens. Sustaining a log-linear RL climb takes a stack of stabilizers (entropy control, router replay, top-p mask replay, self-distillation save-points, asynchronous infra) and a lot of compute that is now a growing fraction of total training cost. And just as GRPO looked like a settled default, long-horizon agentic RL has reopened the algorithm question: trajectory “compaction” produces variable-length sub-traces that break group-relative comparison, pushing Qwen to sequence-level GSPO and GLM-5.2 back to a critic-based PPO. Whether the field reconverges — or RL stays permanently task-specific (GRPO/GSPO for short verifiable tasks, critics for long agentic ones) — is genuinely open, and it is the most active training debate of 2026. Much of this is still craft, not science.
Monitorability vs capability. CoT monitoring is one of the few safety wins of the reasoning era — but it only works if we don’t optimize against it. Keeping chains of thought faithful and legible while also training them to be effective is an unsolved tension.
Inherit vs learn, economically. Distillation from a strong reasoner is cheaper and often better per dollar than RL from scratch — R1 showed distillation beating small-model RL. If that holds, the field concentrates capability in a few frontier base models and everyone else distills. MAI’s “learned, not inherited” bet is partly a wager that this is a dead end for steerability and robustness. We don’t yet know who is right.
The frontiers worth watching: truly agentic, long-horizon RL and the environments that feed it (the environment-scaling supply side); calibrated honesty and abstention for agents that act over many steps; and whether Muon and sub-4-bit precision shift the cost curve enough to change who can train at the frontier at all.
Takeaway. The honest scorecard: verification, the data wall/synthetic question, and contamination are the three places where today’s frontier-training results are most likely to be overclaiming — and they are exactly the places the next round of reports will have to address.
Acknowledgements / sources: figures marked “Image source” are reproduced from the cited papers; all other figures are original.
How to cite
Zhang, Jiaxin. (Jun 2026). How Frontier Labs Train Large Language Models. Jiaxin Zhang’s Blog. https://jxzhangjhu.github.io/blog/2026/how-frontier-labs-train-llms/
@article{zhang2026frontierllmtraining,
title = "How Frontier Labs Train Large Language Models",
author = "Zhang, Jiaxin",
journal = "Jiaxin Zhang's Blog",
year = "2026",
month = "Jun",
url = "https://jxzhangjhu.github.io/blog/2026/how-frontier-labs-train-llms/"
}
References
[1] Amro Abbas, et al. “SemDeDup: Data-efficient learning at web-scale through semantic deduplication.” arXiv:2303.09540, 2023.
[2] Joshua Ainslie, et al. “GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints.” arXiv:2305.13245, 2023.
[3] Rahul K. Arora, et al. “HealthBench: Evaluating Large Language Models Towards Improved Human Health.” arXiv:2505.08775, 2025.
[4] Yushi Bai, et al. “LongBench v2: Towards Deeper Understanding and Reasoning on Realistic Long-context Multitasks.” arXiv:2412.15204, 2024.
[5] Bowen Baker, et al. “Monitoring Reasoning Models for Misbehavior and the Risks of Promoting Obfuscation.” arXiv:2503.11926, 2025.
[6] Mayee F. Chen, et al. “Olmix: A Framework for Data Mixing Throughout LM Development.” arXiv:2602.12237, 2026.
[7] Aakanksha Chowdhery, et al. “PaLM: Scaling Language Modeling with Pathways.” arXiv:2204.02311, 2022.
[8] Ganqu Cui, et al. “The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models.” arXiv:2505.22617, 2025.
[9] Damai Dai, et al. “DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models.” arXiv:2401.06066, 2024.
[10] DeepSeek-AI, et al. “DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model.” arXiv:2405.04434, 2024.
[11] DeepSeek-AI, et al. “DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning.” arXiv:2501.12948, 2025.
[12] DeepSeek-AI, et al. “DeepSeek-V3 Technical Report.” arXiv:2412.19437, 2024.
[13] DeepSeek-AI, et al. “DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models.” arXiv:2512.02556, 2025.
[14] DeepSeek-AI, et al. “DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence.” arXiv:2606.19348, 2026.
[15] Jasper Dekoninck, et al. “Beyond Benchmarks: MathArena as an Evaluation Platform for Mathematics with LLMs.” arXiv:2605.00674, 2026.
[16] Yue Deng, et al. “Multilingual Jailbreak Challenges in Large Language Models.” arXiv:2310.06474, 2023.
[17] Xiang Deng, et al. “SWE-Bench Pro: Can AI Agents Solve Long-Horizon Software Engineering Tasks?.” arXiv:2509.16941, 2025.
[18] Shehzaad Dhuliawala, et al. “Chain-of-Verification Reduces Hallucination in Large Language Models.” arXiv:2309.11495, 2023.
[19] Essential AI, et al. “Essential-Web v1.0: 24T tokens of organized web data.” arXiv:2506.14111, 2025.
[20] Kanishk Gandhi, et al. “Cognitive Behaviors that Enable Self-Improving Reasoners, or, Four Habits of Highly Effective STaRs.” arXiv:2503.01307, 2025.
[21] Tao Ge, et al. “Scaling Synthetic Data Creation with 1,000,000,000 Personas.” arXiv:2406.20094, 2024.
[22] Gemma Team, et al. “Gemma 3 Technical Report.” arXiv:2503.19786, 2025.
[23] GLM-4. 5 Team, et al. “GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models.” arXiv:2508.06471, 2025.
[24] GLM-5-Team, et al. “GLM-5: from Vibe Coding to Agentic Engineering.” arXiv:2602.15763, 2026.
[25] GLM-5.2 Team (Zhipu AI). “GLM-5.2: Built for Long-Horizon Tasks.” Zhipu AI / Z.ai, 2026.
[26] Aaron Grattafiori, et al. “The Llama 3 Herd of Models.” arXiv:2407.21783, 2024.
[27] Melody Y. Guan, et al. “Monitoring Monitorability.” arXiv:2512.18311, 2025.
[28] Lukas Haas, et al. “SimpleQA Verified: A Reliable Factuality Benchmark to Measure Parametric Knowledge.” arXiv:2509.07968, 2025.
[29] David Heineman, et al. “Signal and Noise: A Framework for Reducing Uncertainty in Language Model Evaluation.” arXiv:2508.13144, 2025.
[30] Dan Hendrycks, et al. “Measuring Mathematical Problem Solving With the MATH Dataset.” arXiv:2103.03874, 2021.
[31] Dan Hendrycks, et al. “Measuring Massive Multitask Language Understanding.” arXiv:2009.03300, 2020.
[32] Jordan Hoffmann, et al. “Training Compute-Optimal Large Language Models.” arXiv:2203.15556, 2022.
[33] Jian Hu, et al. “OpenRLHF: An Easy-to-use, Scalable and High-performance RLHF Framework.” arXiv:2405.11143, 2024.
[34] Jiaxin Huang, et al. “Large Language Models Can Self-Improve.” arXiv:2210.11610, 2022.
[35] Naman Jain, et al. “LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code.” arXiv:2403.07974, 2024.
[36] Jared Kaplan, et al. “Scaling Laws for Neural Language Models.” arXiv:2001.08361, 2020.
[37] Kimi Team, et al. “Kimi K2: Open Agentic Intelligence.” arXiv:2507.20534, 2025.
[38] Nathan Lambert, et al. “Tulu 3: Pushing Frontiers in Open Language Model Post-Training.” arXiv:2411.15124, 2024.
[39] Dmitry Lepikhin, et al. “GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding.” arXiv:2006.16668, 2020.
[40] Nathaniel Li, et al. “The WMDP Benchmark: Measuring and Reducing Malicious Use With Unlearning.” arXiv:2403.03218, 2024.
[41] Jingyuan Liu, et al. “Muon is Scalable for LLM Training.” arXiv:2502.16982, 2025.
[42] Tianqi Liu, et al. “RRM: Robust Reward Model Training Mitigates Reward Hacking.” arXiv:2409.13156, 2024.
[43] LLM-Core Xiaomi, et al. “MiMo: Unlocking the Reasoning Potential of Language Model – From Pretraining to Posttraining.” arXiv:2505.07608, 2025.
[44] Anton Lozhkov, et al. “StarCoder 2 and The Stack v2: The Next Generation.” arXiv:2402.19173, 2024.
[45] Wenhan Ma, et al. “Stabilizing MoE Reinforcement Learning by Aligning Training and Inference Routers.” arXiv:2510.11370, 2025.
[46] Aman Madaan, et al. “Self-Refine: Iterative Refinement with Self-Feedback.” arXiv:2303.17651, 2023.
[47] Rabeeh Karimi Mahabadi, et al. “Nemotron-CC-Math: A 133 Billion-Token-Scale High Quality Math Pretraining Dataset.” arXiv:2508.15096, 2025.
[48] Anay Mehrotra, et al. “Tree of Attacks: Jailbreaking Black-Box LLMs Automatically.” arXiv:2312.02119, 2023.
[49] Mike A. Merrill, et al. “Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces.” arXiv:2601.11868, 2026.
[50] Paulius Micikevicius, et al. “FP8 Formats for Deep Learning.” arXiv:2209.05433, 2022.
[51] Paulius Micikevicius, et al. “Mixed Precision Training.” arXiv:1710.03740, 2017.
[52] The Microsoft AI Team. “MAI-Thinking-1: Building a Hill-Climbing Machine.” Microsoft AI, 2026.
[53] Sewon Min, et al. “FActScore: Fine-grained Atomic Evaluation of Factual Precision in Long Form Text Generation.” arXiv:2305.14251, 2023.
[54] MiniMax, et al. “MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention.” arXiv:2506.13585, 2025.
[55] MiniMax, et al. “The MiniMax-M2 Series: Mini Activations Unleashing Max Real-World Intelligence.” arXiv:2605.26494, 2026.
[56] Mistral-AI, et al. “Magistral.” arXiv:2506.10910, 2025.
[57] Gary D. Lopez Munoz, et al. “PyRIT: A Framework for Security Risk Identification and Red Teaming in Generative AI System.” arXiv:2410.02828, 2024.
[58] NVIDIA, et al. “NVIDIA Nemotron 3: Efficient and Open Intelligence.” arXiv:2512.20856, 2025.
[59] Kaan Ozkara, et al. “Stochastic Rounding for LLM Training: Theory and Practice.” arXiv:2502.20566, 2025.
[60] Long Phan, et al. “Humanity’s Last Exam.” arXiv:2501.14249, 2025.
[61] Mary Phuong, et al. “Evaluating Frontier Models for Dangerous Capabilities.” arXiv:2403.13793, 2024.
[62] Felipe Maia Polo, et al. “tinyBenchmarks: evaluating LLMs with fewer examples.” arXiv:2402.14992, 2024.
[63] Zihan Qiu, et al. “Demons in the Detail: On Implementing Load Balancing Loss for Training Specialized Mixture-of-Expert Models.” arXiv:2501.11873, 2025.
[64] Jack W. Rae, et al. “Scaling Language Models: Methods, Analysis & Insights from Training Gopher.” arXiv:2112.11446, 2021.
[65] David Rein, et al. “GPQA: A Graduate-Level Google-Proof Q&A Benchmark.” arXiv:2311.12022, 2023.
[66] Mark Russinovich, et al. “Great, Now Write an Article About That: The Crescendo Multi-Turn LLM Jailbreak Attack.” arXiv:2404.01833, 2024.
[67] John Schulman, et al. “Proximal Policy Optimization Algorithms.” arXiv:1707.06347, 2017.
[68] Zhihong Shao, et al. “DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models.” arXiv:2402.03300, 2024.
[69] Noam Shazeer. “GLU Variants Improve Transformer.” arXiv:2002.05202, 2020.
[70] Guangming Sheng, et al. “HybridFlow: A Flexible and Efficient RLHF Framework.” arXiv:2409.19256, 2024.
[71] Avi Singh, et al. “Beyond Human Data: Scaling Self-Training for Problem-Solving with Language Models.” arXiv:2312.06585, 2023.
[72] Aaditya Singh, et al. “OpenAI GPT-5 System Card.” arXiv:2601.03267, 2025.
[73] Jianlin Su, et al. “RoFormer: Enhanced Transformer with Rotary Position Embedding.” arXiv:2104.09864, 2021.
[74] Xingwu Sun, et al. “Hunyuan-Large: An Open-Source MoE Model with 52 Billion Activated Parameters by Tencent.” arXiv:2411.02265, 2024.
[75] Team OLMo, et al. “2 OLMo 2 Furious.” arXiv:2501.00656, 2024.
[76] Kushal Tirumala, et al. “D4: Improving LLM Pretraining via Document De-Duplication and Diversification.” arXiv:2308.12284, 2023.
[77] Kiran Vodrahalli, et al. “Michelangelo: Long Context Evaluations Beyond Haystacks via Latent Structure Queries.” arXiv:2409.12640, 2024.
[78] Eric Wallace, et al. “The Instruction Hierarchy: Training LLMs to Prioritize Privileged Instructions.” arXiv:2404.13208, 2024.
[79] Shengye Wan, et al. “CYBERSECEVAL 3: Advancing the Evaluation of Cybersecurity Risks and Capabilities in Large Language Models.” arXiv:2408.01605, 2024.
[80] Zengzhi Wang, et al. “OctoThinker: Mid-training Incentivizes Reinforcement Learning Scaling.” arXiv:2506.20512, 2025.
[81] Lean Wang, et al. “Auxiliary-Loss-Free Load Balancing Strategy for Mixture-of-Experts.” arXiv:2408.15664, 2024.
[82] Jason Wei, et al. “Measuring short-form factuality in large language models.” arXiv:2411.04368, 2024.
[83] Mitchell Wortsman, et al. “Small-scale proxies for large-scale Transformer training instabilities.” arXiv:2309.14322, 2023.
[84] Zhiheng Xi, et al. “BAPO: Stabilizing Off-Policy Reinforcement Learning for LLMs via Balanced Policy Optimization with Adaptive Clipping.” arXiv:2510.18927, 2025.
[85] Violet Xiang, et al. “Just Enough Thinking: Efficient Reasoning with Adaptive Length Penalties Reinforcement Learning.” arXiv:2506.05256, 2025.
[86] Can Xu, et al. “WizardLM: Empowering large pre-trained language models to follow complex instructions.” arXiv:2304.12244, 2023.
[87] An Yang, et al. “Qwen3 Technical Report.” arXiv:2505.09388, 2025.
[88] Jiasheng Ye, et al. “Data Mixing Laws: Optimizing Data Mixtures by Predicting Language Modeling Performance.” arXiv:2403.16952, 2024.
[89] Qiying Yu, et al. “DAPO: An Open-Source LLM Reinforcement Learning System at Scale.” arXiv:2503.14476, 2025.
[90] Pedram Zamirai, et al. “Revisiting BFloat16 Training.” arXiv:2010.06192, 2020.
[91] Eric Zelikman, et al. “STaR: Bootstrapping Reasoning With Reasoning.” arXiv:2203.14465, 2022.
[92] Yi Zeng, et al. “How Johnny Can Persuade LLMs to Jailbreak Them: Rethinking Persuasion to Challenge AI Safety by Humanizing LLMs.” arXiv:2401.06373, 2024.
[93] Yi Zeng, et al. “AIR-Bench 2024: A Safety Benchmark Based on Risk Categories from Regulations and Policies.” arXiv:2407.17436, 2024.
[94] Biao Zhang and Rico Sennrich. “Root Mean Square Layer Normalization.” arXiv:1910.07467, 2019.
[95] Yulai Zhao, et al. “One Token to Fool LLM-as-a-Judge.” arXiv:2507.08794, 2025.
[96] Siyan Zhao, et al. “Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models.” arXiv:2601.18734, 2026.
[97] Chujie Zheng, et al. “Group Sequence Policy Optimization.” arXiv:2507.18071, 2025.
[98] Yuxin Zuo, et al. “MedXpertQA: Benchmarking Expert-Level Medical Reasoning and Understanding.” arXiv:2501.18362, 2025.