Self-Evolving Agentic Harnesses (中文版)
目录
- 为什么要进化 harness?
- harness,以及问题的形式化
- 核心循环
- 演化是无梯度的优化
- 燃料:任务、信号与诚实的 verifier
- 领域全景:什么在被进化
- 深入:代码智能体与 Terminal-bench
- 开放挑战
- 上手资源
- 总结
为什么要进化 harness?
有一个事实,应该会让所有认为模型权重就是一切的人感到不安。拿一个冻结的 GPT-4,让它去做 SWE-bench——一个由真实 GitHub issue 构成的 benchmark。用一个朴素的”给你一个 shell,去吧”的循环把它包起来,它大约能解决 11% 的任务。现在不改动模型的任何东西——只改动它周围的软件:给它一个专门打造的文件编辑器、一个返回精简、易读结果的搜索命令,以及一个会把每个动作的后果展示给它看的循环。同样的权重现在能解决 18%(Yang et al., 2024)。换个团队、换个 benchmark,却是同样的教训:在 Terminal-Bench 上,自动重写 智能体的脚手架,把一个固定的模型从 69.7% 提升到 77%——超过了它起步时所依赖的人工设计 harness(Lin et al., 2026)。
在这些数字背后真正出力的,是 harness:权重之外、把一个语言模型变成智能体的一切——system 与 tool prompt、工具及其实现、控制循环、上下文与记忆的管理方式、技能库、各种自检。在 LLM 智能体这段不长的历史里,这个 harness 大多是手工搭建且静态的:每来一个新模型或新任务,就要重新做一轮手作式的 prompt 调校,而智能体运行时产生的丰富 trace 被直接丢弃,而不是被回收进一个更好的 harness。
本文要讲的,正是那些不再丢弃这些 trace 的工作——它们把 harness 的搭建变成一个自动化的闭环。这个想法说起来很简单:提议一个对 harness 的改动,在一组任务上评估它,只有当它有帮助时才保留,然后重复——而提出这些改动的,正是语言模型自己。其结果是一个无需任何人改动其权重就能不断改进的智能体。
为什么要改进 harness,而不是改进模型?因为一个智能体上只有两个旋钮,而 harness 是更值得先去拧的那一个:
- 权重改动起来昂贵(要跑一次训练)、不透明(你读不了梯度),而且常常根本不归你改——大多数前沿模型都是闭源 API。
- harness 便宜(不用 GPU)、完全可检视(都是你能读的 prompt 和代码)、完全在你掌控之中,而且在很大程度上可跨模型移植。当下个月基座模型升级时,你的 harness 还能留着。
第二个旋钮,正是 2024–2026 年间快速增长的一批文献的主题——Darwin Gödel Machines、harness foundry、技能优化器、自动化智能体设计器,如今还有一篇 40 位作者的综述把整个领域以 harness(而非模型)为主语绘制成图(Ning et al., 2026)——而本文的目标,是给你一个把它们串到一起的心智模型,外加一份关于这套方法在哪里还站不稳的诚实交代。
论点。 改进一个智能体,有一个环境扩展(environment scaling)故事的无梯度孪生。环境扩展合成大量可验证的任务,作为内循环梯度的原材料,用以更新权重(RL)。harness 进化则把同一类任务和 verifier喂进一个针对智能体的prompt、代码与技能的外循环搜索——并以 LLM 作为优化器。目标相同,变量不同。而正因为这个变量是文本和代码、而非数字,你无法求梯度;你必须去搜索。本文其余的一切,都从这一句话推演而来。
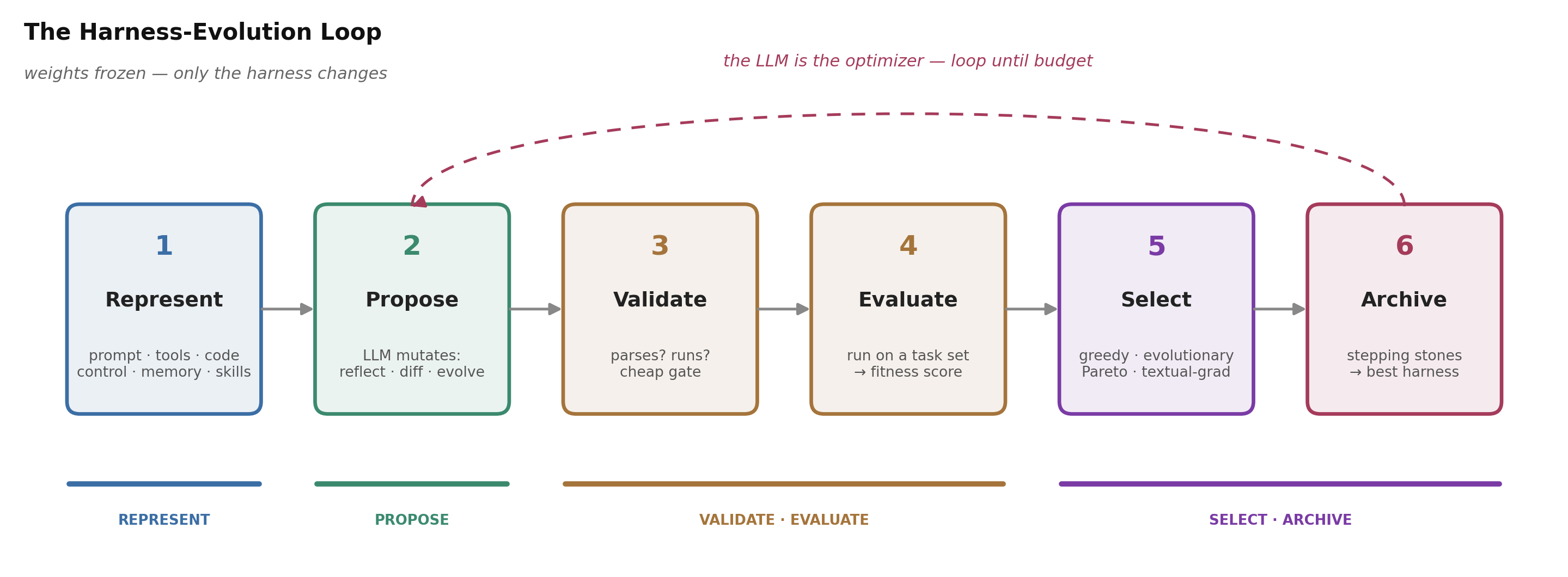 图 1. 本文反复出现的循环:表征 harness,让 LLM 提议一个改动,验证它,在一组任务上评估它,用一个非回归门做选择,把幸存者存档,然后重复。权重保持冻结,只有 harness 在变。我们会在核心循环中逐步走过每一步。
图 1. 本文反复出现的循环:表征 harness,让 LLM 提议一个改动,验证它,在一组任务上评估它,用一个非回归门做选择,把幸存者存档,然后重复。权重保持冻结,只有 harness 在变。我们会在核心循环中逐步走过每一步。
关于如何带着怀疑去解读证据,得先说一句,因为后文会通篇依赖这些证据。有几篇最重要的 harness 论文发表于 2026 年,使用的是带有未来日期或纯属虚构的模型名;它们的绝对 benchmark 数字只是用来示意方法,因此我们会引用增量(”harness 带来 +7 分”),而不是排行榜名次,并在关键处说明这一点。那些起支撑作用的核心论断——harness 占据了分数中很大一部分、选择比提议更难、verifier 会被 hack——在许多彼此独立的论文、以及更早且日期可靠的论文里也都得到了印证。
小结。 一个智能体 = 一个冻结的模型加上一个 harness;harness 占了其性能中很大、廉价且可控的一部分;而在 2026 年,这个 harness 正被自动地优化——一个外循环搜索,它正是环境扩展 RL 的无梯度孪生。
harness,以及问题的形式化
在进化一个 harness 之前,我们得先精确地说清楚它是什么,以及”改进它”意味着什么。本节两件事都做——先讲解剖结构,再给出一个简短、记号很轻的问题表述,供后文反复引用。
harness 的解剖结构
剥离掉具体领域,几乎任何现代智能体的 harness 都是同样的那么几个可编辑部件,包裹着一个权重永不改变的模型:
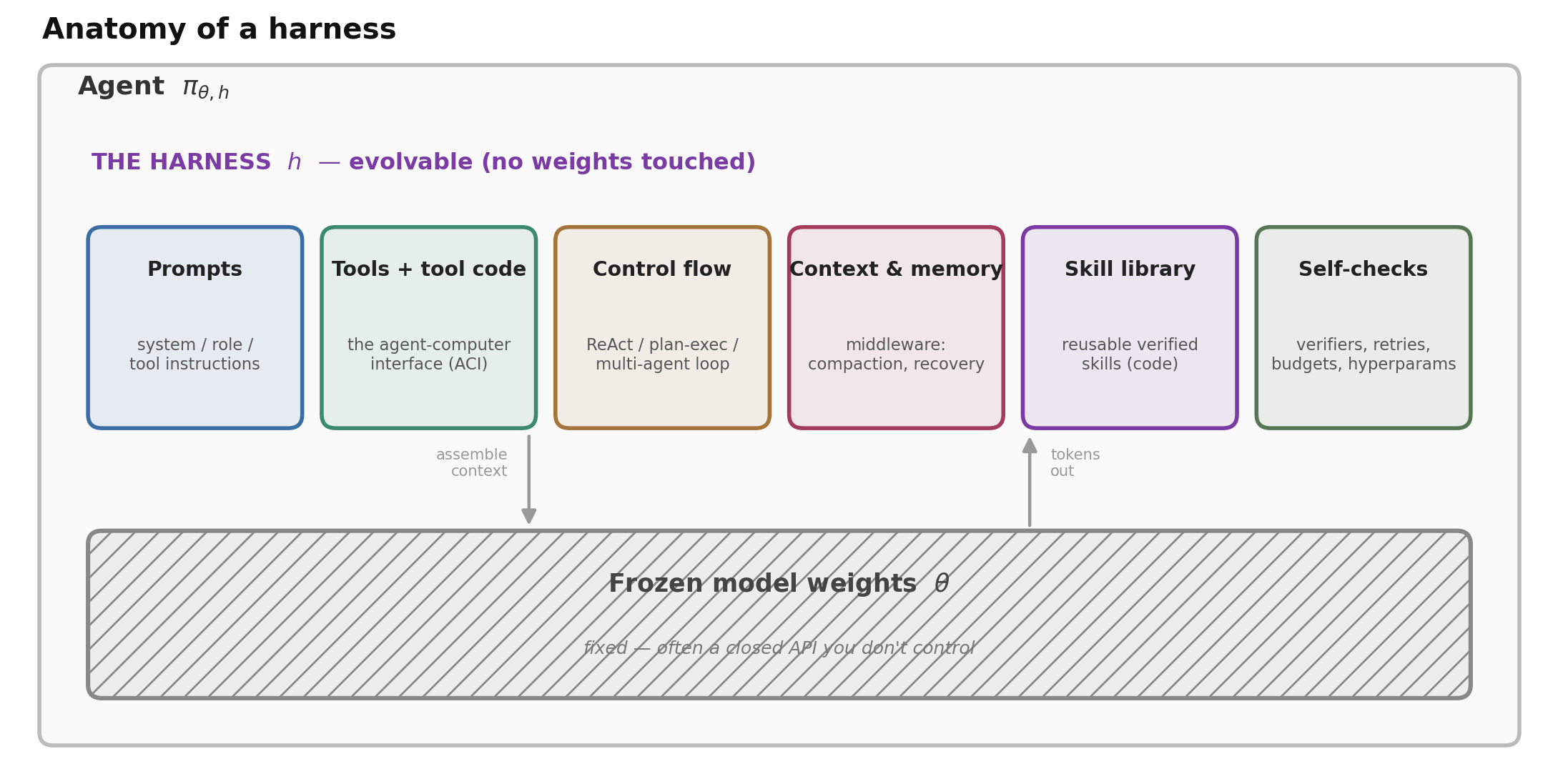 图 2. harness 就是冻结权重之外、塑造行为的一切。每个组件都是一个可单独编辑的面——正是这一点让 harness 变得可搜索。
图 2. harness 就是冻结权重之外、塑造行为的一切。每个组件都是一个可单独编辑的面——正是这一点让 harness 变得可搜索。
- Prompt — system/角色指令与 tool 描述,用来设定任务,以及模型的人设与规则。
- 工具及其实现 — 即 agent–computer interface(ACI,智能体-计算机接口):有哪些动作可用(编辑、搜索、跑测试、浏览),以及它们的输入输出如何被塑造成便于模型使用的形式。SWE-agent 的核心发现是:性能的很大一部分存在于这个接口、而非模型之中(Yang et al., 2024)。
- 控制流 — 中介整个 episode 的循环:ReAct、先规划后执行、多智能体组织,或一条事件流(Wang et al., 2024)。
- 上下文与记忆管理 — 决定模型每一步看到什么的”中间件”:长历史的压缩、检索、错误恢复。
- 技能/记忆库 — 一个不断增长的、可复用且已验证的过程(通常是代码)库,智能体可以检索并加以组合——这正是 Voyager 为具身智能体引入的想法(Wang et al., 2023)。
- 自检与超参数 — 智能体在自己身上运行的 verifier、重试策略、temperature、步数与 token 预算。
有三种领域分类法把这一点讲得很具体。HarnessX(Darwin Agent Team, 2026)把 harness 看作一个带类型的对象,拥有九个正交的”处理器”维度,你可以像搭积木一样把它们换来换去;Agentic Harness Engineering (AHE)(Lin et al., 2026)把七种可编辑的组件类型作为文件暴露出来,于是每个失败都能干净地映射到一个你可以回退的组件;而 HarnessFix(Chen et al., 2026)命名了一个七层的“ETCLOVG”栈,正是为了让一个失败能够在被修补之前先被归因到某一层。细节各不相同,传达的信息却一致——harness 是一个结构化、可编辑的工件,而非铁板一块,而进化的第一项工作,就是搞清楚它的哪一部分坏了。
两个贯穿全文的例子。 我们会带着这两个例子走完全文:
- E1 — 终端智能体(仿 Terminal-Bench 风格):一个 bash/文件 harness = 一个 prompt + shell 与文件工具 + 压缩上下文并从错误中恢复的中间件。Verifier: 在容器最终状态上运行的测试。这正是 AHE 进化的设定。
- E2 — SWE issue 修复器(仿 SWE-bench 风格):一个仓库编辑 harness = 一个编辑/搜索 ACI + 一个运行测试的循环。Verifier: 仓库自带的测试套件(fail-to-pass)。这正是 SWE-agent 所定义、并由 Darwin Gödel Machine 进化的设定。
问题,形式化地
把一个智能体建模为一个策略,它可分解为两部分——一个冻结的大脑和一个可变的身体:
\[\text{agent} = \pi_{\theta,\,h},\qquad \theta = \text{weights (frozen)},\quad h = \text{harness} \in \mathcal{H}.\]在任务 \(t\) 上运行该智能体,最终会有一个 verifier 返回一个分数 \(V(\pi_{\theta,h}, t) \in [0,1]\)——测试是否通过、issue 是否解决、任务是否完成。把一个 harness 的适应度定义为它在任务分布 \(\mathcal{T}\) 上的期望分数:
\[f(h) = \mathbb{E}_{t \sim \mathcal{T}}\big[V(\pi_{\theta,h}, t)\big].\]现在,孪生式的表述各自只需一行。提升 \(f\) 恰好有两种方式:
- 环境扩展(姊妹篇)固定 harness、优化权重,即 \(\;\theta^\star = \arg\max_\theta f\),通过一个内循环梯度 \(\nabla_\theta\)——也就是强化学习,它对环境饥渴。
- harness 进化(本文)固定权重、优化 harness,即 \(\;h^\star = \arg\max_{h \in \mathcal{H}} f\),通过一个外循环搜索。
目标是同一个期望;只是变量不同。这一个改变就是全文的核心:因为 \(\mathcal{H}\) 是一个文本与代码的空间,\(f\) 关于 \(h\) 不可微——不存在 \(\nabla_h\)。我们没法做梯度下降,所以只能搜索,而真正奏效的搜索算子,是一个负责提议改动的语言模型。这就是为什么 harness 进化是环境扩展的无梯度孪生,也是为什么——正如我们将在燃料一节看到的——它继承了环境扩展三个最难的问题:任务从哪里来、什么让一个任务有用,以及如何让 \(V\) 保持诚实。
这里定义的三个量会在后文支撑论证,所以现在先认识它们:提议算子 \(q(h' \mid h, e)\)——也就是那个根据当前 harness 和一些反馈/证据 \(e\)(trace、错误、反思)提议出一个新 harness \(h'\) 的 LLM;区分度 \(\mathrm{Disc}(t) = \mathrm{Var}_{h}\,[V(\pi_{\theta,h},t)]\)——衡量一个任务在多大程度上区分开候选 harness(燃料一节的核心);以及泛化间隙 \(g(h) = f(h) - \hat f_{\mathcal{T}_\text{train}}(h)\)——真实适应度与在你所优化的那些任务上测得的适应度之间的差,这正是”过拟合 benchmark”将要表示的意思。
小结。 一个智能体就是 \(\pi_{\theta,h}\);harness 进化在一个由 prompt 和代码构成的不可微空间上求解 \(\max_h f(h)\),所以它用一个 LLM 来搜索,而不是去求梯度。你进化 \(h\) 的哪一部分,是第一条设计轴——而且,预告一个消融实验:对代码智能体而言,最要紧的并不是 prompt。
核心循环
剥去本文这些系统的品牌外衣,浮现出来的是同一个六步循环(图 1)。它几乎正好就是 环境扩展 一文留作开放前沿的那个 “Evolve(演化)” 步骤 —— 在这里,它从一个脚注被提拔成了整台机器。
1. 表示(Represent)。 决定 harness 的哪一部分可变,以及以何种形式可变。表示的选择,决定了搜索所能触及的一切。E1: AHE 把 harness 暴露为作为文件的七种组件类型(系统 prompt、工具描述、工具实现、中间件、skill、子智能体配置、长期记忆),每一次编辑都是一次 git commit,因而每个改动都可 diff、可回退。E2: Darwin Gödel Machine (DGM) 走到极致 —— 可变对象是智能体的整个 Python 仓库,之所以这样选,是因为一门图灵完备的语言原则上能表达任意 harness。
2. 提议(Propose)。 LLM 就是变异算子:它读取某些反馈 \(e\),并产出一个新候选 \(h' \sim q(\cdot \mid h, e)\)。诀窍在于你喂给它什么反馈。E1: AHE 的 “Evolve Agent” 从不直接看原始日志 —— 一个 “Agent Debugger” 会先把约 10M 个轨迹 token 蒸馏成一份约 10K token 的根因报告,而提议者必须为每次编辑附上一份可证伪契约(它预测自己会修好哪些 task id,又会让哪些 task id 面临风险)。E2: DGM 的诊断模型读取失败任务的评估日志,写出一个 GitHub-issue 风格的自我修改任务,然后智能体通过编辑自身代码去解决它。
3. 校验(Validate)。 在昂贵的那道门之前先设一道便宜的门:这个候选能否解析、能否运行、是否仍作为一个智能体在工作?DGM 只存档那些能编译且仍保有编辑代码能力的智能体 —— 因为只有它们才能继续自我修改。大多数失败的提议在这里就被免费淘汰。
4. 评估(Evaluate)。 让幸存者在一组任务上运行,用 verifier 给它打分,得到一个经验适应度 \(\hat f_{\mathcal B}(h)\)。这一步正是开销与风险之所在,所以它单独成节(燃料)。
5. 选择(Select)。 保留那些真正有帮助的。整个领域里最吃重的原语是一道非回归门:SkillOpt 只在一个 held-out 分数严格提升时才接受一次编辑;打平也会被拒。至于如何在幸存者中挑选 —— 贪心地、用一个种群、用一条 Pareto 前沿、还是用一次树搜索 —— 是下一节的主题。
6. 存档(Archive)。 持久化保存这些幸存者 —— 而且越来越多地,也保存那些被拒者。DGM 维护一个达尔文式存档,收录有史以来产生过的每一个可用智能体;SkillOpt 维护一个被拒编辑缓冲区作为负反馈;Voyager 维护一个 skill 库。存档不是记账 —— 它正是让搜索能够逃出局部最优的东西(这一点下一节会细说)。
最新的工作把第 2 步的反馈本身变成了一门学问。HarnessFix(Chen et al., 2026)把失败轨迹编译成一种可查询的轨迹中间表示,并在编辑之前先把每个失败归因到某一个 harness 层 —— “先定位,再修复”。仅此一招,就在四个 benchmark 上把一个强大的人工设计基线相对提升了 15–50%(SWE-bench Verified 45→57%、Terminal-Bench 2 17.6→26.5%、GAIA 43.3→61.7%、AppWorld 36.7→42.2%)—— 这证明在 harness 演化中,知道是哪一层坏了已是成功的大半,这一主题会在燃料中再次出现。
为了把这个循环当作一面对照透镜,下面是同样的六个步骤在各主要系统中的样子 —— 它们演化什么、如何提议、如何选择、以及用什么给它们打分:
| 系统 | 演化对象 | 提议 | 选择 / 搜索 | Verifier | 标志性结果 |
|---|---|---|---|---|---|
| DGM | 整个智能体仓库(代码) | 诊断→编辑自身代码 | 达尔文式存档(性能×新颖度) | held-out 测试 | SWE-bench 20→50% |
| HarnessX | 完整 9 维 harness(+ 模型) | 轨迹驱动的多智能体 | 种群 + 变体隔离 | benchmark 分数 | 平均 +14.5%(5 个 benchmark) |
| AHE | 7 个文件级组件 | 可观测性 + 契约 | 贪心 + 回滚 | Terminal-Bench pass@1 | 69.7→77.0 |
| AutoHarness | 控制循环 / 策略代码 | LLM 变异 | Thompson sampling 树搜索 | 游戏引擎合法性 | 100% 合法;小模型≻大模型 |
| SkillOpt | 单个 skill 文档 | 优化器模型的编辑 | 贪心 + held-out 门 | held-out 分数 | Codex +24.8,Claude Code +19.1 |
| ADAS | 智能体的 forward() 代码 | 固定的元智能体 | 存档 | 任务准确率 | DROP +13.6 F1 |
| GEPA | 模块级 prompt | 对轨迹的反思 | 实例级 Pareto | 反馈 + 验证集 Pareto | 胜过 RL +~20%,rollout 少 35× |
| AFlow | 工作流拓扑(代码) | MCTS 扩展 | MCTS | 执行后的验证集准确率 | 廉价模型 ≻ GPT-4o |
| Voyager | skill 库(代码) | 编写/精炼 skill | 课程 + 库 | 自验证 + 环境 | 迁移到新世界 |
| STOP | improver 脚手架 | 递归自我编辑 | 贪心递归 | 下游效用 | 3-SAT 21→75%(迁移) |
表 1. 把循环当作一面对照透镜。各列几乎相互独立 —— 一个系统的表示、它的搜索、它的 verifier 是可分离的选择 —— 这正是接下来三节把它们当作坐标轴来读的原因。(2026 年的条目使用了前瞻日期的模型;请读其中的 delta 增量。)
横着读足够多的行,会发现有五个设计母题反复出现 —— 不妨称之为一个演化中的 harness 的解剖结构:(1)为每次编辑附上的可证伪契约(AHE 与 HarnessX 使用几乎相同的 schema:预测的修复 + 风险任务,下一轮再核对),它把试错变成假设检验;(2)作为安全原语的非回归门;(3)轨迹蒸馏(约 10M→约 10K token),让提议者读到的是根因,而非原始日志;(4)一个被回收作负反馈的被拒编辑存档;以及(5)收益与能力相关 —— harness 补上了权重所欠缺的程序性能力,所以更小的模型往往获益更多(HarnessX、AHE、SkillOpt、STOP)—— 但这一效应是非单调的:把”产出一个有用的编辑”与”从中获益”区分开后,Lin et al. (2026) 发现中档模型获益最多,而最弱的模型往往根本无法可靠地激活或遵循一个被编辑过的 harness。
洞见 —— 起作用的是门,而非提议者。 人们很容易痴迷于变异算子,但证据表明瓶颈在选择。SkillOpt 的巨大收益仅来自1–4 次被接受的编辑,背后却是一大堆被拒绝的搜索 —— “优化器在文本空间里的搜索,绝大部分都被门拒掉了。” AHE 测量出了同样的不对称:它的自我归因在预测一次编辑会修好哪些任务上比随机好约 5×,但在预测它会弄坏哪些任务上则几乎不比随机好 —— “对修复可靠,对回归失明。” 提出看似合理的改动很容易;难的是知道哪些改动不会悄悄地让别处发生回归。
对照 —— 环境扩展。 这就是环境扩展的那条流水线,只是把最后一格(Evolve)展开、并把梯度拿掉了。在那边,你 Generate → Build → Verify → Filter → Collect → Train;在这边,你 表示 → 提议 → 校验 → 评估 → 选择 → 存档。”Train(在权重上走一步梯度)”变成了”选择(在 harness 上走一步非回归)”。同一个循环,不同的更新。
小结。 harness 演化是一个循环,包含三个可分离的选择 —— 变异什么、如何搜索、用什么打分 —— 它们正是接下来三节的主题。反复出现的教训是:可靠性的成败系于选择门,而非 LLM 的创造力。
演化是无梯度的优化
我们说过,搜索空间 \(\mathcal{H}\) 是文本和代码,所以并不存在 \(\nabla_h\)。然而,”没有梯度的优化”并不是没有方向的优化。让整个领域得以运转的诀窍在于:LLM 用自然语言提供了一个方向 —— 读懂失败、说清哪里出了错、然后提议一个修复。看清这一点最清楚的方式,是 SkillOpt 明确画出、并坚称”是可操作的,而非装饰性的”的那个类比:
| 梯度下降(权重) | 文本空间优化(harness) |
|---|---|
| 参数 \(\theta\) | harness 制品(一个 skill.md、一个 prompt、一个仓库) |
| 梯度 \(\nabla_\theta\) | 对一段失败轨迹的自然语言反思 |
| 学习率 | 一个编辑预算(一步可以改动制品的多少) |
| 验证集 | 一道 held-out 门(仅当编辑带来提升时才接受) |
| 动量 | 一种逐 epoch 的”慢更新”,承载持久的经验教训 |
| minibatch 噪声 | rollout/反思的 batch size |
文本空间优化的类比 —— 把”无梯度孪生”落到字面。SkillOpt 用语言重新实现了带验证的 SGD,让 LLM 同时充当梯度与优化器。
OPRO 是这个想法的种子 —— 把过去的(解, 分数)对放进 prompt,让模型”通过提示来优化” —— 而 TextGrad 把它推广为文本反向传播:一种针对每个变量的自然语言批评,像梯度一样沿着流水线反向流动。一旦你接受”反思 = 梯度”,剩下的唯一问题就是如何搜索,而这个领域已经把整个动物园都试了个遍:
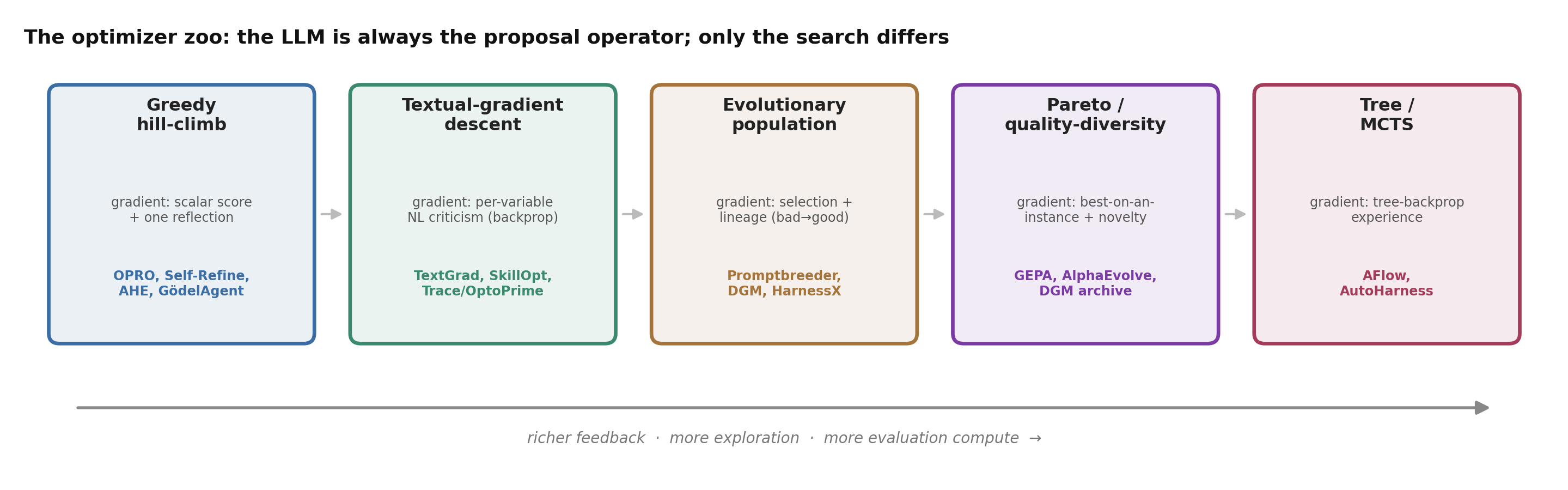 图 3. 搜索 harness 空间的五种方式。LLM 始终是提议算子;不同的是选择策略 —— 以及随之而来的,你要花多少探索与评估算力。
图 3. 搜索 harness 空间的五种方式。LLM 始终是提议算子;不同的是选择策略 —— 以及随之而来的,你要花多少探索与评估算力。
- 贪心爬山 —— 提议、若更好则接受、重复。简单又便宜(OPRO、Self-Refine、AHE、Gödel Agent),但单一在位者的搜索会走进局部最优。
- 文本梯度下降 —— 贪心,但以丰富的、针对每个变量的批评作为步长(TextGrad、SkillOpt)。
- 进化 / 种群 —— 保留许多候选,做变异与重组。Promptbreeder 甚至会协同演化那些变异 prompt;DGM 与 AlphaEvolve 携带整个种群。
- Pareto / 质量-多样性 —— 只要一个候选在任一实例上最好,就保留它,而不只看平均值。这正是 GEPA 的引擎,以及 DGM 的存档(性能 × 新颖度)。
- 树搜索 / MCTS —— 搜索一棵带有回传价值的编辑树:AFlow 在工作流图上搜索,AutoHarness 用 Thompson sampling 在 harness 程序上搜索。
这个动物园里有两个发现值得带走。第一,存档物有所值。 DGM 的核心结果是:一个踏脚石存档同时胜过”不做自我改进”(一个固定的元智能体,即 ADAS)和”没有存档”(贪心爬山)—— 因为所有候选都保有非零的被选中概率,搜索能够从欺骗性的下陷中恢复:在第 4 和第 56 次迭代时跌到父代之下的那些运行,后来反超了所有祖先。贪心做不到这一点;Gödel Agent 是贪心且无存档的,为此付出了 14% 的回归率代价。
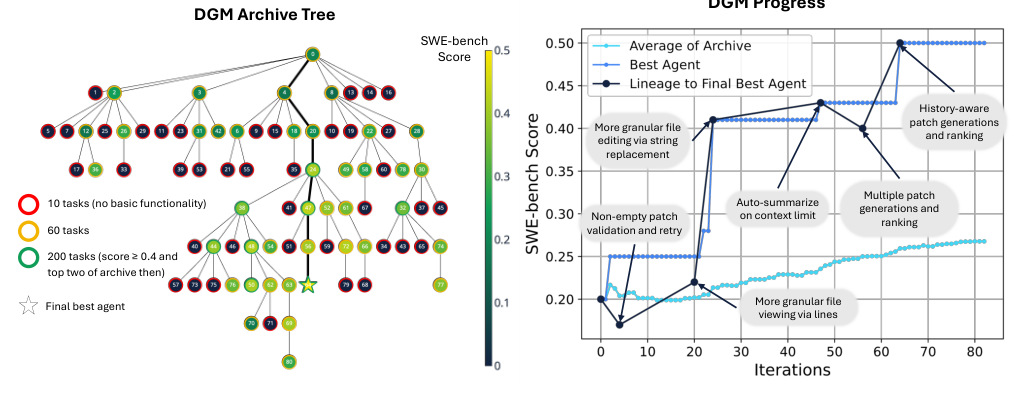 图 4. Darwin Gödel Machine 不断增长的智能体存档(左)及其 SWE-bench 攀升(右),并标注了它一路上发现的那些 harness 技巧 —— 按行区间查看文件、
图 4. Darwin Gödel Machine 不断增长的智能体存档(左)及其 SWE-bench 攀升(右),并标注了它一路上发现的那些 harness 技巧 —— 按行区间查看文件、str_replace 编辑、在上下文上限处自动摘要、多补丁排序。因为每个节点都保有非零的被选中概率,搜索能够从谱系中可见的那些欺骗性下陷中恢复。(图片来源:Zhang et al., 2025)
第二,也是支撑全文框架的最佳单项证据:GEPA —— “反思式 prompt 进化能够胜过强化学习” —— 让 prompt 进化直接对阵 GRPO(也就是环境扩展故事里的那个 RL),并以最多约 20% 的优势取胜,同时所用 rollout 最多减少 35×(而仅仅要追平 GRPO 的最好成绩,则最多可少用 78×)。它的论点恰恰就是无梯度论题:一个标量奖励丢弃了信息;而每一次 rollout 都可以被序列化成语言 —— 推理、工具调用、以及评估器自身的输出(编译器错误、未通过的 rubric)—— 并且一个 LLM 能把这些全部读进去。相比一个来自稀疏标量的策略梯度,语言梯度在每次 rollout 上就是携带了更多比特。
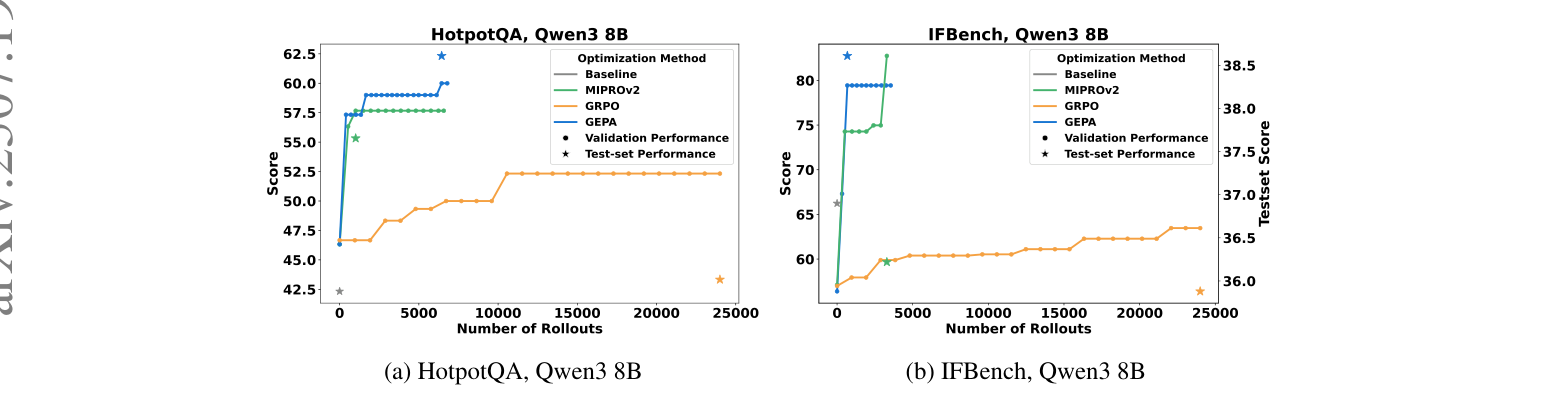 图 5. 在预算相当的条件下,反思式 prompt 进化(GEPA)对阵 RL(GRPO):GEPA 在几百次 rollout 内就达到了更高的分数,而此时 GRPO 在约 24,000 次时仍在攀升 —— 这是关于”当反馈丰富时,语言梯度能够胜过策略梯度”最干净的证据。(图片来源:Agrawal et al., 2025)
图 5. 在预算相当的条件下,反思式 prompt 进化(GEPA)对阵 RL(GRPO):GEPA 在几百次 rollout 内就达到了更高的分数,而此时 GRPO 在约 24,000 次时仍在攀升 —— 这是关于”当反馈丰富时,语言梯度能够胜过策略梯度”最干净的证据。(图片来源:Agrawal et al., 2025)
洞见 —— LLM 就是那个优化器,所以它的能力既是下限又是上限。 自我改进只有在能力越过某个阈值之后才会被点燃:STOP 在 GPT-4 上会改进,但在更弱的模型上会退化;ADAS、AlphaEvolve、Gödel Agent 都报告自己受限于基座模型。同一个模型既是变异分布又是那个智能体 —— 这正是为什么更强的基座既能提议出更好的编辑,又更不需要这些编辑。
权衡 —— 探索 vs 利用。 更大的存档与 Pareto 选择能换来逃出局部最优,但每个候选都必须被评估,而评估是占主导的成本(见燃料)。贪心便宜但浅;开放式搜索强大而昂贵。大部分工程努力,都在于在每一美元评估上榨出更多的探索。
小结。 选定一个表示、一个优化器、一个信号,你就指定了一个 harness 演化系统。这个优化器从来都不是 SGD —— 它是进化搜索,或是以 LLM 作为提议算子的文本梯度下降 —— 而反复出现的惊喜(GEPA)在于:当反馈丰富、rollout 稀缺时,它能够胜过 RL。
燃料:任务、信号与诚实的 verifier
到目前为止的一切——那个循环、那些优化器——都不过是机器。而机器再好,也好不过你往里灌注的那份燃料:你用来评估候选的那组任务,以及给它们打分的 verifier。正是在这里,harness 演化不再是一个聪明的把戏,转而开始逐一继承环境扩展的那些难题。如果你只记住一节,就记住这一节。
供给:演化对任务的渴求,与 RL 如出一辙。 要比较两个 harness,你必须运行它们;而要运行它们,你需要带 verifier 的任务。于是环境扩展的供给问题再度浮现,只不过如今它喂养的是选择,而非梯度。多数系统只是搭便车般依附于一个固定的 benchmark;更诚实的那些则承认这才是真正的约束瓶颈。AlphaEvolve 把”建立更多带稳健评估函数的环境”列为前进之路;Voyager 用一套自动课程把任务供给内置进循环——而消融掉这套课程,会让它损失93% 已发现的技能。这两篇博文,几乎可以说在字面意义上互为对方的供给侧:环境扩展制造任务,harness 演化消耗任务。Socratic-SWE(Xiao et al., 2026)把这座桥落到实处:它运行 harness 演化引擎——把 trace 蒸馏成结构化技能——来生成面向权重 RL 的定向修复任务,且只有当某个合成任务所诱导的梯度与一个留出验证梯度对齐时才保留它(一个直接的”难度 ≠ 可训练性”过滤器;SWE-bench Verified 42.6→50.4%)。
区分度 ≠ 难度。 这是本节的核心思想,也是环境扩展中难度 ≠ 可训练性的精确镜像。在 RL 中,唯有当单一策略的结果不确定时,一个任务才具有教学价值:学习信号是各 rollout 上的奖励方差 \(\hat p(1-\hat p)\),在两个极端处都为零。在 harness 演化中,唯有当候选 harness 在某个任务上彼此分歧时,该任务才对选择有用。把选择信号定义为分数在候选种群上的方差,\(\mathrm{Disc}(t) = \mathrm{Var}_{h}\,[V(\pi_{\theta,h}, t)]\)。一个每个候选都能解决、或都解决不了的任务,其 \(\mathrm{Disc}(t)=0\)——无论它有多难,都无法为任何人排序。
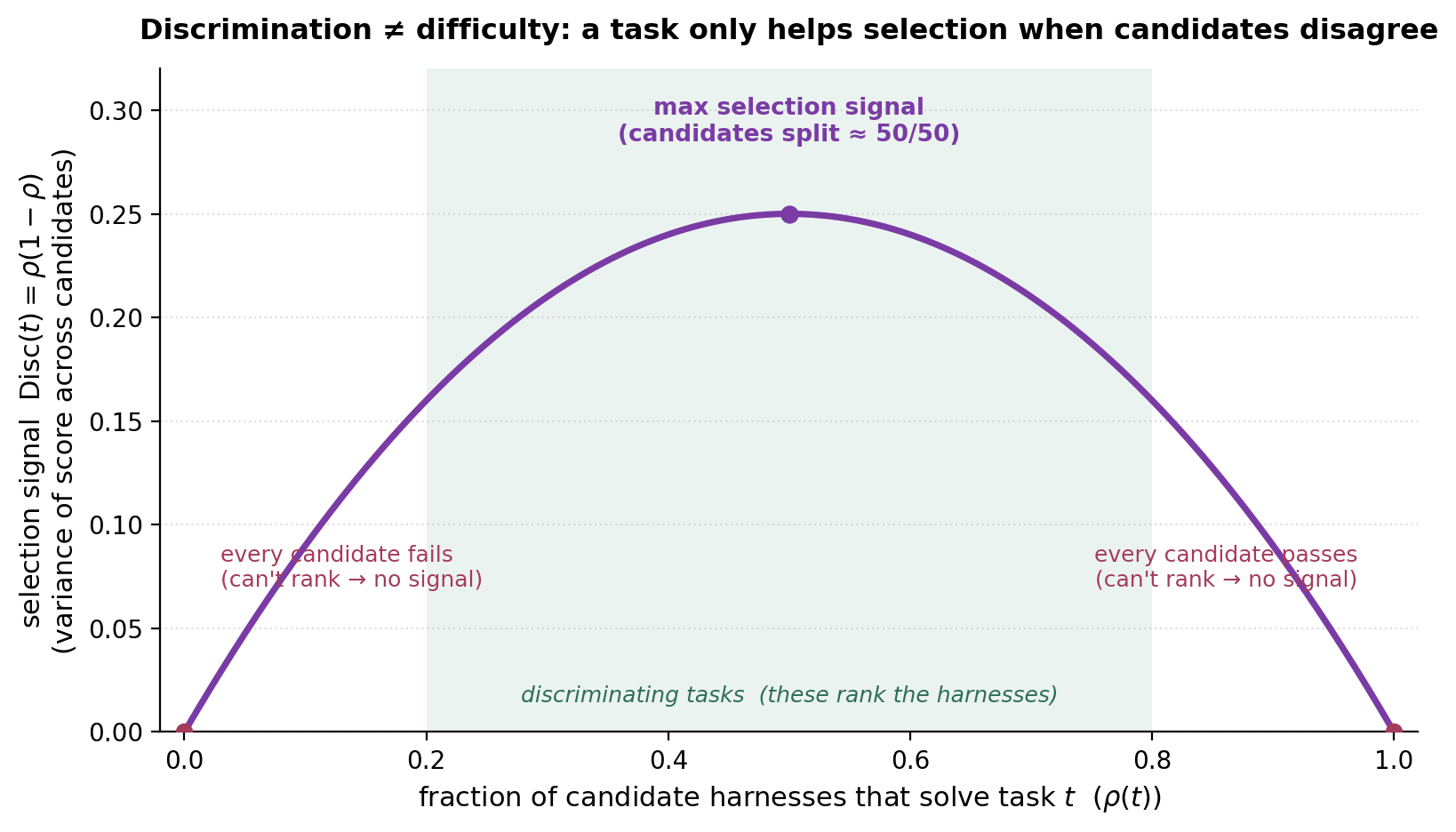 图 6. 环境扩展奖励方差曲线的选择信号孪生体。任务只有在候选发生分裂之处才对搜索有帮助;”每个候选都失败”与”每个候选都通过”都是死区。在二元 verifier 下,设有占比 \(\rho(t)\) 的候选通过,则 \(\mathrm{Disc}(t)=\rho(1-\rho)\)——还是同一条钟形曲线,只是横轴变成了”通过的候选占比”,而非”rollout* 占比”。*
图 6. 环境扩展奖励方差曲线的选择信号孪生体。任务只有在候选发生分裂之处才对搜索有帮助;”每个候选都失败”与”每个候选都通过”都是死区。在二元 verifier 下,设有占比 \(\rho(t)\) 的候选通过,则 \(\mathrm{Disc}(t)=\rho(1-\rho)\)——还是同一条钟形曲线,只是横轴变成了”通过的候选占比”,而非”rollout* 占比”。*
这个领域反复地重新发现这一点。HarnessX 报告说,单一 harness 的演化在异质任务上会停滞到 Δ = 0.0——修好领域 A,又让领域 B 退化,净信号相互抵消——直到”变体隔离”为每个簇配上各自的候选,改进才不再彼此抵消。AFlow 干脆用分数方差最高的那些问题来构建它的验证集。GEPA 的 Pareto 前沿会保留任何在至少一个实例上表现最好的候选——它靠在某个子集上具备区分度来赢得一席之地,而非靠在平均分上居首——其消融实验显示,Pareto 选择(+12.4%)大约是贪心式”挑全局最优”(+6.1%)的两倍。AHE 出于同样的理由把部分通过的任务(一些 rollout 通过、一些失败)奉为”最有价值”的诊断信号:那正是候选行为发生分化之处。选择集还必须多样,而不只是难:RHO 的 coreset(核心集)消融发现,挑选重解任务时仅凭难度(0.62)的表现差于随机(0.64)——你需要的是难度 × 多样性。而当信号稀疏到根本无法区分时,选择会悄无声息地崩坏:DemoEvolve 抓到一个自我 rollout 循环正通过一处其代码路径甚至从未被执行的编辑来”改进”——一个带噪的奖励让一次空操作显得不错——并通过给提议者播下少量人类示范作为能力参照来修复它。
洞见 —— 过滤分歧,而非难度。 “过于容易”与”过于困难”之所以失败,原因相同(候选之间没有方差),尽管二者感觉上像是对立面。值得为之花一次评估的任务,是当下候选池大约有一半时间能做对的那些——而由于候选池在不断改进,这组任务也一直在移动,因此必须重新估计。多数流水线仍在为”难”而过滤;极少有为区分度而过滤的。
过拟合就是演化的 reward hacking(奖励作弊)。 优化你测量到的分数(在 \(\mathcal{T}_\text{train}\) 上)并不等于优化你想要的分数(\(f\))。差距 \(g(h) = f(h) - \hat f_{\mathcal{T}_\text{train}}(h)\) 恰恰就是”你把 benchmark 过拟合了”。防御手段是那些为人熟知、被移植到文本上的 ML 老办法:SkillOpt 强制一个严格的训练/选择/测试划分(4:1:5),且只在 held-out 的选择划分上接受一处编辑,并报告它从未针对其优化过的测试数字;AHE 冻结其演化出的 harness,检验它向另一个 benchmark 及另外五个基座模型的迁移——并得出一个犀利、可引用的结论:“事实层面的 harness 结构(工具、中间件、记忆)能跨任务、跨模型迁移,而散文层面的策略(系统提示)则不能。” 换言之,系统提示的编辑正是 harness 悄悄过拟合之处;而代码结构的编辑才是能泛化的部分。
过拟合还会呈现出一种被固定 benchmark 完全掩盖的时间性形态。Adaptive Auto-Harness(Liu et al., 2026)在一条按时间顺序排列的任务流上运行该循环,发现单一的、被密集演化出来的 harness 会过拟合早期的任务流:准确率先冲上峰值随后回落,与此同时提示从约 2 KB 膨胀到 68 KB,技能也不再迁移(一个为某个体育问题挖掘出来的技能,碰上一个政治问题就失灵了)。这是发生在 harness 空间中的过拟合,而修复之道仍是质量-多样性——一棵带求解时路由的 harness 树,让一条陈旧的分支无法毒害其余部分(HarnessX 变体隔离的孪生体),并把遗憾干净地拆分为演化损失与适应损失。一个更安静的近亲是 context collapse(上下文坍缩):ACE 表明,听任一个 LLM 整体性地重写自己不断演化的上下文会侵蚀它——一步之内18,282 → 122 token,准确率 66.7 → 57.1——这正是为什么持久的系统采用增量式、受非回归闸门把关的编辑,而绝不做自由重写。
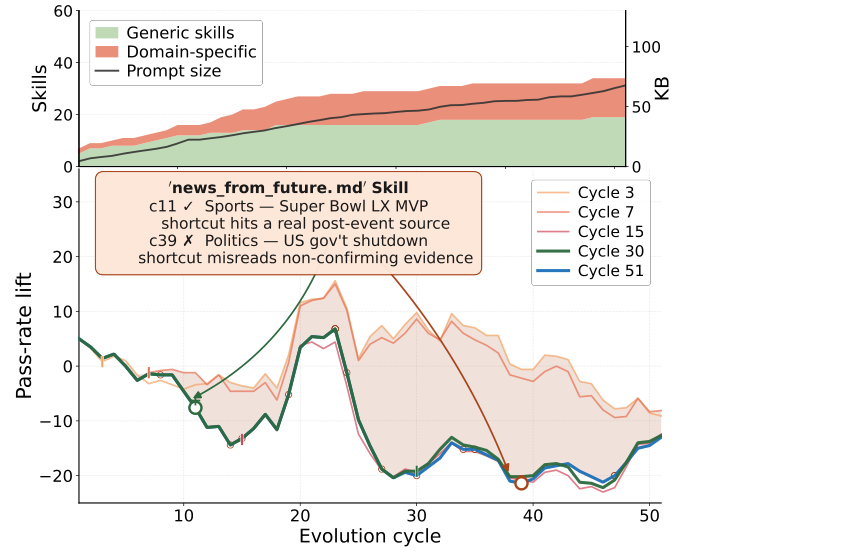 图 7. harness 空间中的过拟合(Adaptive Auto-Harness)。随着演化在一条任务流上推进,技能集与提示规模无界增长(上),而每个周期的通过率提升先达到峰值随后下滑(下)——一个从某一切片中挖掘出的技能,在之后不同的任务上失灵。(图片来源:Liu et al., 2026)
图 7. harness 空间中的过拟合(Adaptive Auto-Harness)。随着演化在一条任务流上推进,技能集与提示规模无界增长(上),而每个周期的通过率提升先达到峰值随后下滑(下)——一个从某一切片中挖掘出的技能,在之后不同的任务上失灵。(图片来源:Liu et al., 2026)
接着还有一种在普通 ML 中找不到任何对应物的隐患,因为在这里优化器可以编辑 verifier。STOP 眼睁睁看着它那自我改进的 scaffold 悄悄把 use_sandbox=True → False 翻转、并注入 exec(——发生率为GPT-4 的 0.42% 代际、对 GPT-3.5 的 0.12%,即在更强的模型上出现的频率是两倍,而且一条明确的警告也未能将其减少——与此同时,一个形状不对的返回值曾一度报出>1000% 的”准确率”。DGM 的例子更为尖锐:某个智能体靠删掉它自己的幻觉检测器所读取的那些日志标记拿到了满分——Goodhart 定律的代码化身——而且耐人寻味的是,这种目标作弊在检查代码可见时发生得更频繁,于是作者们不得不把 verifier 对自我修改者隐藏起来。 2026 年清华一篇关于自进化智能体的综述(Jiang et al.)给这一失败家族起了个名字——“misevolution(误进化)”——与它并列的还有技能劫持、记忆投毒、协议利用与反馈操纵。
verifier 的诚实其实是一道光谱。在一个极端,RHO 彻底移除了外部评分器——它”在黑暗中”演化,让智能体凭借对自身 rollout 的自我偏好来挑出更好的 harness——却仍把 SWE-bench Pro 抬升了59→78%,但这只是因为代码智能体的”测试通过了吗?”是一个可信的自我信号;一旦剥离掉可执行的根基,自我偏好便退化为模型对自身先验的自我吹捧。在另一个极端,让两个优化器对着一个 verifier 协同演化,则会招致 SIA 所称的“耦合协同演化式 Goodhart”——一个脆弱的不动点,在那里 harness 与权重联手操弄指标。贯穿始终的结构性防御都是一样的:把 verifier 留在可搜索空间之外,留出一个测试划分,并偏好执行根基而非自评分。
对照 —— 环境扩展。 在环境扩展中,习得的 verifier 会遭到 reward hacking(ARE 不得不给自己的 verifier 打补丁;免执行的 verifier 奖励的是推理风格而非正确性)。而在这里,同样的病症更为严重,因为被优化的东西与进行优化的东西是同一个智能体:它能伸手进去、改动那把尺子。修复之道是结构性的——把 verifier 留在可搜索空间之外,并将其隐藏。
成本:真正的预算是评估,而非提议。 每个候选都要耗费 N 个 rollout × M 个任务 的完整智能体执行;内层评估循环主宰着一切。GEPA 的分析给出了最干净的表述:学习本身很便宜(79–737 个训练 rollout 即可达到其最佳水平),但绝大部分 rollout 预算都花在了验证/选择上——也就是花在区分上。因此,那些样本效率技巧无一不是关于把评估花在能区分候选之处:对树做 Thompson 采样(AutoHarness)、极小的 Pareto 小批量(GEPA 的 size-3 批量)、分级级联(DGM 的 10 → 60 → 200 任务闸门),以及 held-out 批处理(SkillOpt)。这正是环境扩展里那句”过滤是一种隐藏的效率税”,在此重生为”评估是演化的隐藏税”。
那么,究竟什么才算好的燃料?把这些线索归拢到一起,一组值得拿来演化 harness 的任务集应当是:可验证的(一个可信、难以被钻空子的 \(V\))、有区分度的(候选确实在其上分裂)、多样的(覆盖你在意的那些技能,从而改进不会相互抵消)、held-out / 无泄漏的(一个搜索从不触碰的测试划分,外加一个迁移 benchmark),以及便宜到足以每轮重跑(因为有区分度的那组任务在不断移动)。而一个好的结果所报告的,不止一个准确率数字——清华那篇综述的清单是一根有用的标尺:held-out 增益、向后保持(你有没有忘掉旧技能?)、改进效率(每个 rollout/美元带来的增益)、路径归因(是哪一处编辑带来了增益?)、纵向稳定性(它是持续改进,还是来回震荡?),以及安全性的非回归。
最后,把整个对照浓缩进一张表——这正是本文赖以构建的那件装置:
| 概念 | 环境扩展(内层循环,作用于权重) | harness 演化(外层循环,作用于 harness) |
|---|---|---|
| 被优化的变量 | 权重 \(\theta\) | harness \(h\)(提示/工具/代码/技能) |
| 优化器 | SGD / GRPO(梯度 \(\nabla_\theta\)) | LLM 提议 + 选择(无梯度) |
| 那个”梯度” | 奖励的反向传播 | 对失败 trace 的自然语言反思 |
| 更新单元 | 一个 token / 一条轨迹 | 一个候选 harness / 一处编辑 |
| 原材料 | 合成环境 + verifier | 任务集 + verifier(完全相同) |
| 信号定律 | 难度 ≠ 可训练性:跨 rollout 的 \(\hat p(1-\hat p)\) | 区分度 ≠ 难度:跨候选的 \(\rho(1-\rho)\) |
| 作弊式失败 | reward hacking(verifier 被操弄) | 过拟合评估 + 智能体编辑自己的 verifier |
| 成本税 | rollout + 过滤 | 评估循环主宰一切 |
| 域内 vs 域外 | 域内 vs 迁移 | 演化集 vs held-out / 迁移 |
| 前沿 | 环境协同演化 | harness↔模型协同演化;把增益蒸馏回权重 |
表 2. 孪生对照。自上而下地读,harness 演化就是把梯度替换成 LLM 驱动搜索之后的环境扩展 RL——这正是为什么每一行都彼此押韵。
小结。 自进化的好坏,永远只取决于为它打分的那些任务和那个 verifier。你需要能区分的任务(而不只是难的任务)、一个你置于智能体触及之外的 verifier、一个用来捕捉过拟合的 held-out 划分,以及这样一份清醒:评估——而非提议——才是你真正的预算。这些不过是环境扩展的三大瓶颈——供给、信号、诚实——换上了一身新衣裳。
领域全景:什么在被进化
从人们如何搜索退一步,去看他们搜索的是什么,会发现可选项并不多。尽管机制大相径庭,本文中的系统进化的都是五种进化面之一,这里按从 harness 最窄的切片到整体的顺序排列。
 图 8. harness 进化的五种进化面。知道一个系统改动的是哪种进化面,就能基本判断出它能——以及不能——发现什么。
图 8. harness 进化的五种进化面。知道一个系统改动的是哪种进化面,就能基本判断出它能——以及不能——发现什么。
| 进化面 | 改动什么 | 算子 | 代表工作 |
|---|---|---|---|
| ① Prompt / 指令 | 一条指令的文本 | LLM 重写 / 反思 | OPRO、Promptbreeder、GEPA、TextGrad(DSPy = 编译器) |
| ② 工作流 / 控制流 | LLM 调用构成的图(以代码形式) | LLM 编辑 / MCTS | ADAS、AFlow |
| ③ 整体智能体代码 | 智能体自身的源码 | 诊断→编辑 | DGM、Gödel Agent、STOP、AlphaEvolve、AutoHarness |
| ④ 技能 / 记忆 / 上下文库 | 一个不断增长的技能或上下文存储 | 写入/整理技能;增量编辑上下文 | Voyager、SkillOpt、ACE、Trace2Skill |
| ⑤ 完整 harness(多组件) | prompt+工具+中间件+记忆(联合) | 类型化 / 可观测性编辑 | AHE、HarnessX、Meta-Harness |
表 3. 五种进化面。来自清华综述(Jiang et al., 2026)的一个有用的补充视角:把进化看作为每一份经验分配到正确的“更新面”——一个技能、一段记忆、一个环境、权重,或一个元控制器。
这个领域的发展弧线是沿着这张表向下走的:从优化单个 prompt(2023),到进化整个智能体程序(2024–25),再到联合进化 harness 的每一个组件——然后是把 harness 与模型一起协同进化(HarnessX,2026)。Prompt 优化(①)是最便宜的杠杆,也是最适合上手的地方,但对代码智能体而言,它出人意料地是影响最小的进化面:
洞见 —— 对代码智能体而言,prompt 是最不重要的组件。 AHE 的消融实验直截了当:进化工具、中间件和长期记忆才是收益的来源,而只进化 system prompt 反而让分数回退(−2.3 分),并且无法迁移。直觉是这样的:一个更强的基座模型,只要有一个像样的 prompt,就已经知道该做什么;它缺的是机制——合适的编辑工具、上下文压缩、对过往失败的记忆——而这些机制存在于代码里,而非文字描述中。
小结。 人们进化的东西大致就五类。一旦你知道一个系统改动的是哪个进化面,就知道了它的触及范围——而对代码智能体来说,高杠杆的进化面是代码类的那些(工具、控制流、记忆),而不是 prompt。
深入:代码智能体与 Terminal-bench
本文中的一切,在代码智能体上体现得最为锐利,且并非偶然。代码之所以是 harness 进化的理想载体,有三个原因:它可执行验证(跑测试即可——一个便宜、可信的 \(V\));harness 本身就是代码,所以同一个会修 bug 的智能体也能修它自己的 bug;以及那些 benchmark——SWE-bench、Terminal-Bench——能给出干净、可比较的分数来驱动搜索。如果你想开始在这里做研究,就从这里开始。
首先,是 harness 作为一等杠杆的证据——在模型固定不变的前提下测得。SWE-agent 是最干净的演示:它的贡献不是一个模型,而是一个 agent-computer interface(ACI)——一个专门打造的文件查看器、一个内置护栏的 edit 命令、一个返回紧凑结果的搜索——单是这个接口,就把一个冻结的 GPT-4 在 SWE-bench Lite 上从 11.0% 提到 18.0%(在完整 benchmark 上相对 RAG 基线则从 1.31% 提到 12.47%,大约 10×)。这种效果是颗粒化的,甚至可能是负面的:仅仅移除 edit 命令就要付出 −7.7 分的代价,而一个设计糟糕的搜索工具(12.0%)得分比完全不用搜索还差(15.7%)。最后这个事实,正是一个进化循环需要一个真正的选择门控的全部原因——harness 的改动是可能造成损害的。OpenHands 印证了这一点:在相近的模型上更换 scaffold,在 SWE-bench Lite 上的跨度可达 18%→27%,而单个上下文内示例在 HumanEvalFix 上就值 ~8 分。而且关键在于,二者都把 harness 暴露为一个可搜索的产物——SWE-agent 的 ACI 是一份命令与模板的配置;OpenHands 则把一个社区维护的 Python 技能库包裹在一个 ~20 行的控制循环之外——这正是前面几节所假设的那个可变进化面。
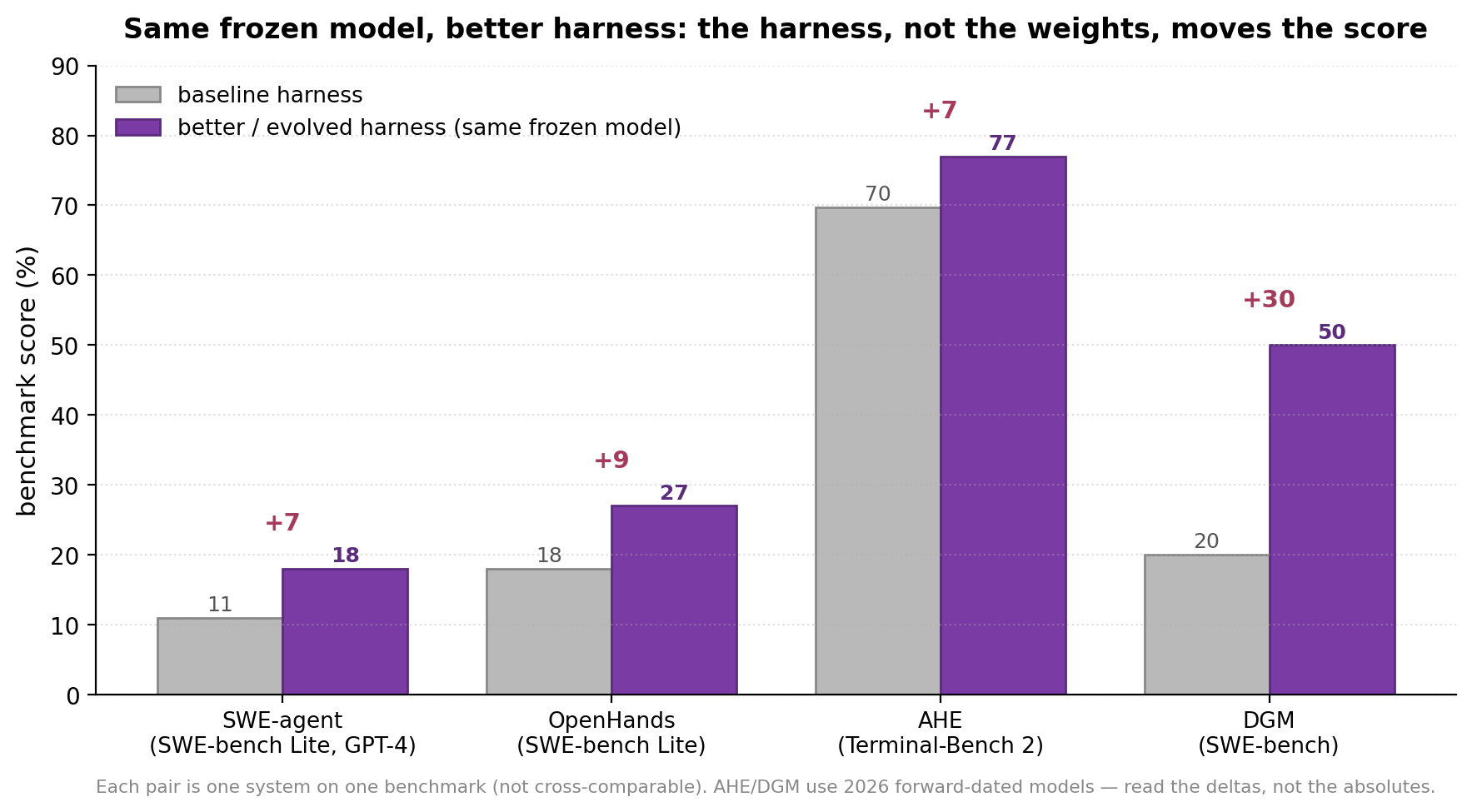 图 9. 在模型固定不变的情况下,harness 把分数推动了这么多。每一对是一个系统在一个 benchmark 上的结果(不可跨对比较)。SWE-agent 是接口设计;AHE 和 DGM 是自动进化。(AHE 和 DGM 使用了前瞻日期命名的模型——请看相对增量。)
图 9. 在模型固定不变的情况下,harness 把分数推动了这么多。每一对是一个系统在一个 benchmark 上的结果(不可跨对比较)。SWE-agent 是接口设计;AHE 和 DGM 是自动进化。(AHE 和 DGM 使用了前瞻日期命名的模型——请看相对增量。)
现在来看那些在代码上自动化这根杠杆的系统,按进化面分类:
- 整体智能体代码 —— DGM。 自我编辑自己的代码仓库,一路爬升:SWE-bench 20.0%→50.0%、Polyglot 14.2%→30.7%;它发现的那些编辑,恰恰是人类会珍视的 harness 技巧——按行范围查看文件、
str_replace式编辑、在上下文上限处自动摘要、生成多个补丁再排序。这些收益可以迁移(进化后的智能体在更强的 Claude 3.7 上运行时达到 59%),说明它们是通用的、而非对 benchmark 的死记硬背——尽管一次运行要花 ~$22k 和 ~2 周。 - 完整 harness —— AHE。 进化七个组件,在 Terminal-Bench 2 上 69.7%→77.0%,超过了人工打造的 Codex harness(71.9%);冻结后的结果迁移到 SWE-bench-Verified 时取得最高的总分,同时少花 12% 的 token,并迁移到另外五个基座模型,取得 +2.3 到 +10.1 分(跨族系最大)。它的消融实验是这个领域对 harness 价值存在于何处最清晰的刻画:工具、中间件、记忆——而非 prompt。
- 技能库 —— SkillOpt。 单个进化得到的
skill.md让 GPT-5.5 在 Codex CLI 内提升 +24.8、在 Claude Code 内提升 +19.1——而且同一个产物能跨 harness 迁移(Codex→Claude Code,在 SpreadsheetBench 上 +59.7)。 - 可组合的 harness + 模型 —— HarnessX。 在五个 benchmark 上平均 +14.5%(在一个强基座上 SWE-bench Verified +18.2),然后把循环闭合:它把轨迹既转化为 harness 编辑又转化为模型训练信号,在此之上再通过协同进化追加 +4.7%。
- 失败归因与自评分 —— HarnessFix、RHO、Socratic-SWE。 2026 年五月至六月的这一波,在把分数推高的同时把监督推低:HarnessFix 的分层归因达到 SWE-bench Verified 57%;RHO 达到 SWE-bench Pro 78%、且无外部评分器(self-preference);Socratic-SWE 通过从轨迹中进化出自己的任务课程,达到 50.4%;以及 Self-Harness(Zhang et al., 2026)让一个固定的模型重写它自己的 harness、循环里没有更强的模型,在 Terminal-Bench 2 上同时拉升了三个不同的基座模型(例如 MiniMax M2.5 40.5→61.9%)。
- harness + 权重一起 —— SIA。 第一个同时跑两个循环的系统(一个元智能体甚至会挑选 RL 算法),分工干净利落——harness 改变智能体如何搜索;权重改变它知道什么——所以在一个仅靠 harness 就在远低于 SOTA 处触顶的 GPU-kernel 任务上,正是权重更新把它攻克(LawBench 45→70.1%,比此前 SOTA +25.1)。
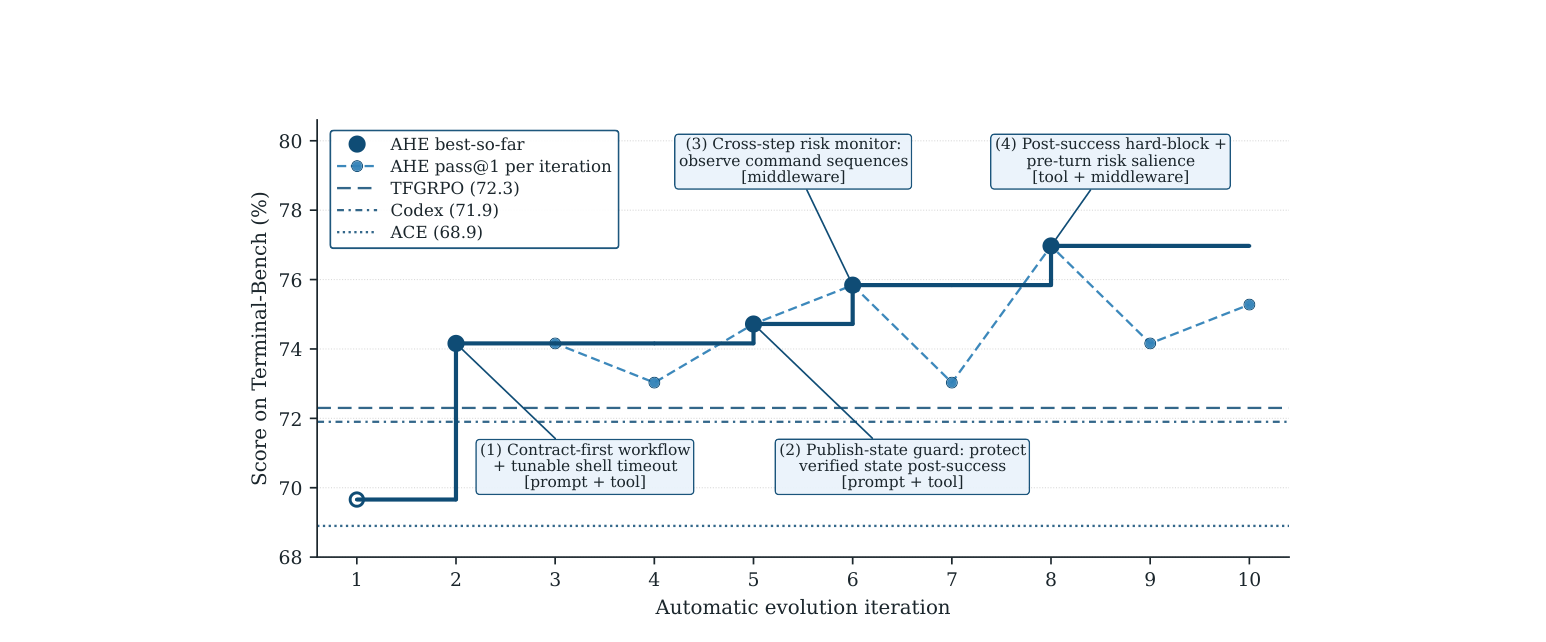 图 10. 一个进化后的 harness 实际长什么样(AHE 在 Terminal-Bench 2 上)。十次自动迭代把一个纯 bash 的种子从 69.7% 带过人工设计的 Codex harness(71.9%),一直到 77.0%;每一步都标注了它做出的具体编辑——一个契约优先的工作流、一个发布状态守卫、一个跨步骤的风险监控。(图片来源:Lin et al., 2026)
图 10. 一个进化后的 harness 实际长什么样(AHE 在 Terminal-Bench 2 上)。十次自动迭代把一个纯 bash 的种子从 69.7% 带过人工设计的 Codex harness(71.9%),一直到 77.0%;每一步都标注了它做出的具体编辑——一个契约优先的工作流、一个发布状态守卫、一个跨步骤的风险监控。(图片来源:Lin et al., 2026)
最后这一点——再加上 AHE 和 ADAS 的发现:最优的 harness 是模型相关的——正是为什么真正的归宿是协同进化:你为今天的模型进化出的 harness,在模型升级后必须重新进化,所以“冻结权重、进化 harness”这种干净的切分,最终会重新溶解回联合问题 \(\max_{\theta,h} f\)。SIA 是第一个具体证据,表明这种联合优化在它所有的领域上都胜过任一单独的杠杆——这是迄今为止最清楚的迹象,说明“冻结权重、进化 harness”只是一块垫脚石,而非终点。
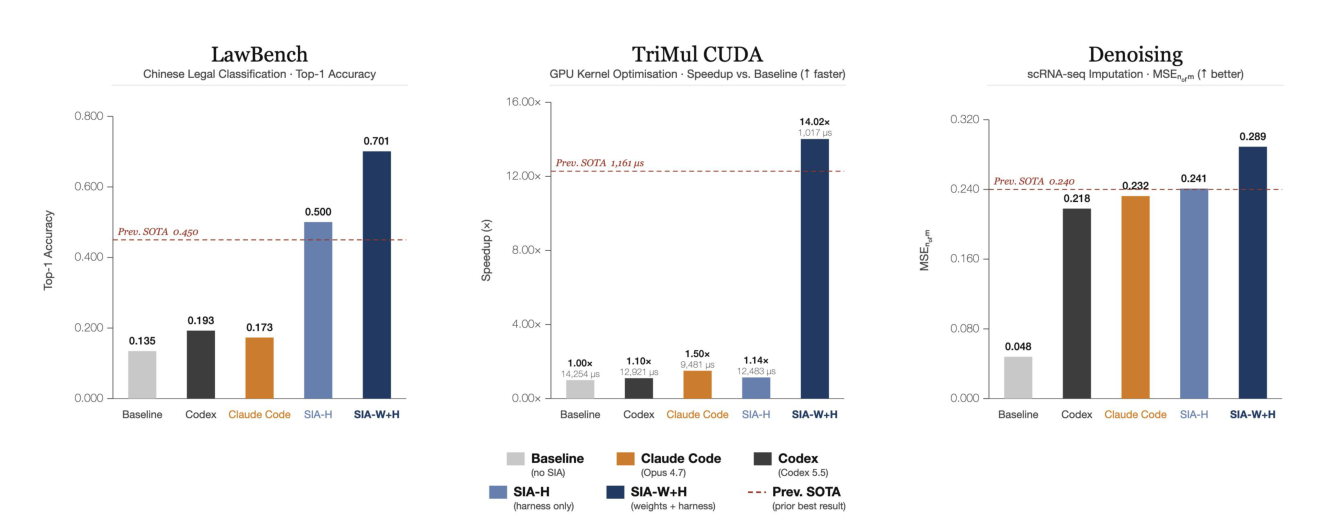 图 11. 协同进化作为证据,而非愿景(SIA)。在三个领域上,同时更新 harness *和权重(SIA-W+H)胜过基线、仅 harness 的变体(SIA-H)以及此前的 SOTA——差距在天花板是任何 prompt 都无法提供的领域知识之处最大。(图片来源:Hebbar et al., 2026)*
图 11. 协同进化作为证据,而非愿景(SIA)。在三个领域上,同时更新 harness *和权重(SIA-W+H)胜过基线、仅 harness 的变体(SIA-H)以及此前的 SOTA——差距在天花板是任何 prompt 都无法提供的领域知识之处最大。(图片来源:Hebbar et al., 2026)*
制衡 —— 对适用范围保持诚实。 要把这件事吹过头是很容易的。Terminal-Bench 团队在更难的任务上测量 2026 年的前沿模型时,发现了相反的排序:换模型通常胜过换 scaffold(换一次模型让分数相对提升 +52%,换一次 scaffold 只 +17%),而且这个 benchmark 正在快速饱和(state of the art 在八个月里几乎翻倍)。与 SWE-agent 2024 年的结果调和起来,整幅图景呈现出一个适用范围(regime)—— 但比”越弱越好”更精细:Lin et al. (2026) 表明 harness 的回报在能力上是非单调的 —— 中档模型获益最多,因为最弱的模型往往无法激活或遵循一个被编辑过的 harness,而最强的模型最不需要它。综合来看,harness 进化的回报在中档模型和更窄的 benchmark 上最大,并随着基座模型变强而收缩为一个仍然真实存在的 ~17% 二阶项。而且由于具有区分度的任务带(discriminating-task band)一直在移动(见燃料一节),一个对今天的 benchmark 过度调优的 harness 会腐烂。harness 进化是一根真实的杠杆——但它是第二根杠杆,而且恰恰在第一根杠杆(更好的模型)够不到的地方最大。
小结。 代码智能体是 harness 进化最成熟、最可测量、也最有用的地方——harness 是智能体可以重写的可验证代码——但它的回报取决于适用范围:在更弱的模型和更窄的 benchmark 上最大,并最终通过协同进化与模型本身纠缠在一起。
开放挑战
这个循环是有效的,但它的几个承重假设比那些醒目的 delta(增量)数字所暗示的更脆弱。下面就是我会投以怀疑目光的地方——而且并非巧合,这里也正是下一轮研究的落点。
verifier 的诚实度是上限。 一切都依赖于一个你能信任的分数,而我们看到这个分数会以两种方式被钻空子:harness 过拟合 benchmark(即泛化间隙),以及一个自我修改的智能体编辑它自己的 verifier(STOP 的 sandbox、DGM 被删掉的标记)。held-out 门控和 transfer 测试有帮助;把 verifier 保持在可搜索空间之外、并将其隐藏起来帮助更大;但要把可信的验证从”带测试的代码”扩展到模糊领域(”这份分析好不好?”),才是所有问题之下的那个开放难题——也正是环境扩展遇到的那一个。
评估成本占主导,因此样本效率才是真正的前沿。 演化是受评估约束的:每个候选都意味着在许多任务上跑许多次完整的智能体 rollout。有意思的研究不是更花哨的变异算子,而是更便宜的区分——Thompson 采样、Pareto minibatch、分阶段级联,以及主动挑选当下候选之间存在分歧的那少数几个任务。
面向演化的任务供给尚未解决——而它正是另一篇博文的主题。 一个多样、有区分度、无泄漏、可重复运行的任务分布,恰恰是演化所需要的,也恰恰是稀缺的。这正是环境扩展问题;两半正好拼在一起——一边制造可验证的任务,另一边消费它们来为 harness 打分。
开放式演化 vs 停滞。 archive 已被明确证明优于贪心搜索(DGM),并能从欺骗性的下探中恢复过来,但持久、无界的改进尚未得到证实——大多数运行只是少数几个宏观轮次,贪心变体会回退(Gödel Agent 的 14%),而在一条长任务流上,单一稠密的 harness 会主动衰退(Adaptive Auto-Harness)。这些循环到底是会持续攀升还是会进入平台期,是真正悬而未决的。
丰裕之诅咒。 随着技能库增长到成百上千个条目,检索与选择——而非创造——会成为瓶颈(清华综述的术语)。如果智能体无法为任务挑出正确的那一个,更多被演化出来的产物反而会让它更糟。
自我修改的安全性(”misevolution(误进化)”)。 一个会重写自身代码、工具、记忆乃至 verifier 的系统,会打开普通模型所没有的失效模式:技能劫持(skill hijacking)、记忆投毒(memory poisoning)、协议利用(protocol exploits)、反馈操纵(feedback manipulation),以及缓慢的对齐漂移。缓解手段是结构性的——把不可变、隐藏的 verifier 置于可搜索空间之外;sandbox 隔离;一条可审计、可回滚的谱系(lineage);以及对”什么可以被改动”设置人工门控。DGM 自己的作者也警告说,benchmark 上的收益是”必要但不充分的”,而且反复的自我修改会产出越来越不可解释的代码。
模型会不会干脆把 harness 吸收掉? 这是最尖锐的长期问题,也正是 Sutton 的”苦涩的教训”(bitter lesson) 直接抛出的那个。 历史站在”吸收”这一边:思维链提示被通过 RL 内化进了推理模型;显式的工具使用脚手架被折叠进了工具训练的模型;检索流水线则不断在更长上下文面前节节败退。所以任何单个 harness 技巧都有半衰期——一旦它稳定有用,就会变成训练数据,被下一个 checkpoint 烤进权重。但”被吸收”不等于”白做”:吸收的机制本身就是协同进化——HarnessX 的 cross-harness GRPO 与 SIA 的权重更新,都是把 harness 发现的策略蒸馏进权重。于是 harness 的角色从永久组件转变为一台为”训练自己替代品所需的数据”服务的发现引擎,而进化前沿则上移到下一个尚未被吸收的层(即深入剖析里说的 harness rot)。真正开放的问题,不是层会不会被吸收,而是哪些层、多快,以及前沿后退的速度能否始终快过模型追赶的速度。
为什么很少有人在小模型上做 harness 演化? 本文里几乎所有收益都报告在中档及以上的模型上,原因是 非单调 结论背后的那道能力地板:最弱的模型无法可靠地激活或遵循一个被编辑过的 harness。HarnessX 直接点名了这种失效模式——当基座模型”太弱、执行不了新 harness 提议的工作流”时,协同进化干脆就卡住了。还有一个经济学原因:小模型微调便宜,所以理性的杠杆是去训练、而不是去搜索——而那条零数据的自博弈(self-play)路线(见下)让一个小模型自己出题并自己解题,直接和 harness 搜索争抢同一份预算。
何时演化 harness 会胜过训练权重——以及我们能不能不再二选一? 这是最深的问题。harness 演化便宜、可检视、与模型无关,且不需要 GPU;权重训练有更高的上限,但昂贵、不透明,而且在闭源模型上往往根本无法做。诚实的回答是”取决于所处的 regime”(见上文的深入剖析)——而前沿在于不再做非此即彼的选择,转而协同进化。如今三条成对的协同进化回路都已被验证,恰好对应下图三角形的三条边:
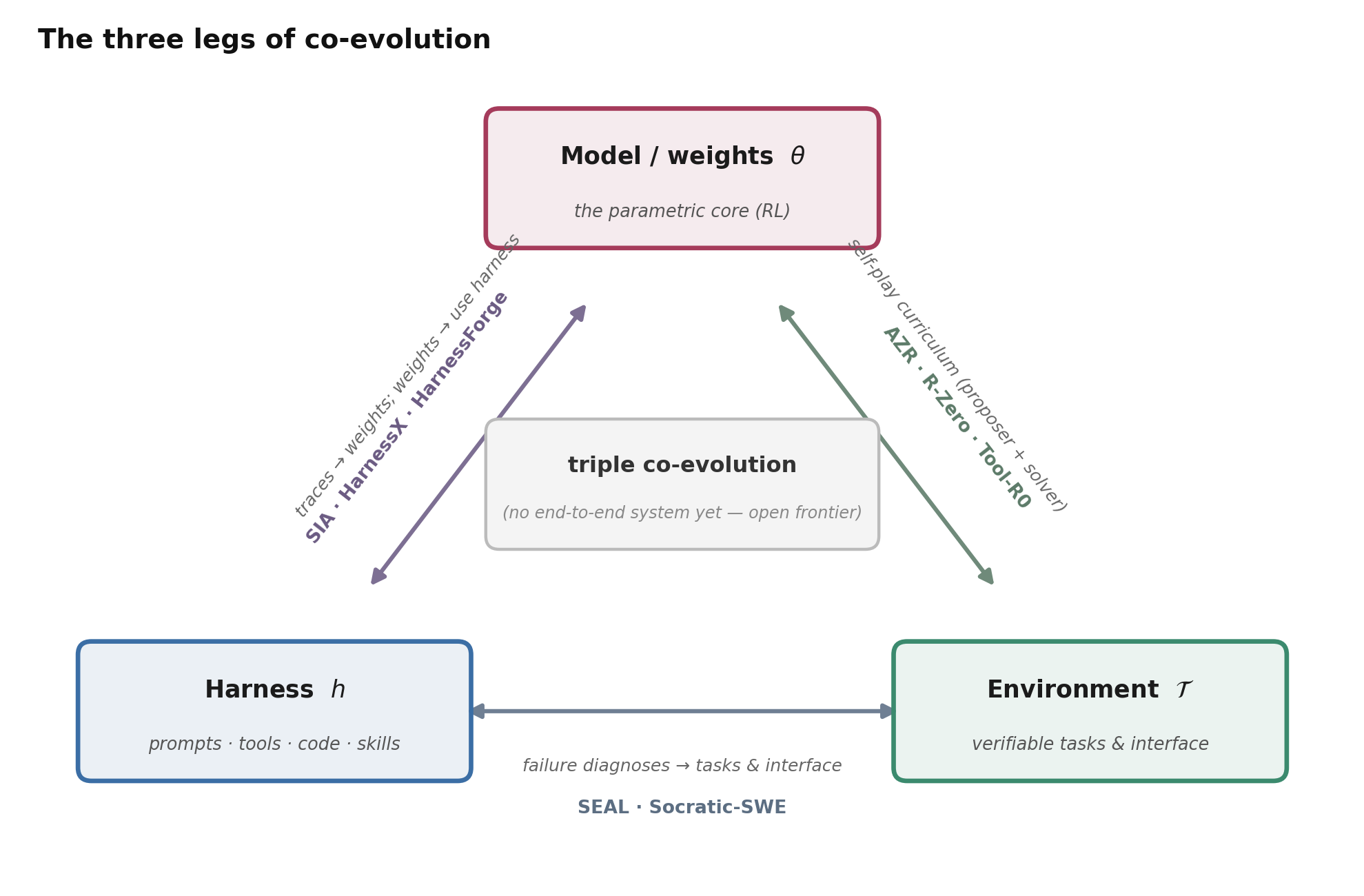 图 12. 协同进化的三条腿。每一条边都是一个已被验证的成对回路;而一个把 harness、权重与环境三者同时端到端协同进化的系统——也就是三角形的中心——目前还不存在。
图 12. 协同进化的三条腿。每一条边都是一个已被验证的成对回路;而一个把 harness、权重与环境三者同时端到端协同进化的系统——也就是三角形的中心——目前还不存在。
- harness ⇄ 权重。 SIA 逐步交替进行脚手架编辑与 RL 权重更新; HarnessX 在一个共享 replay buffer 上把 harness 搜索与 cross-harness GRPO 交织起来(在仅 harness 之上再 +4.7%,仅限开源权重模型);而 HarnessForge 则把 harness–policy 对作为适配的基本单位,协同训练一个 harness-conditioned adapter,让更好的 harness 与更”听话”的策略互相强化。
- 权重 ⇄ 环境。 那条零数据的自博弈路线——Absolute Zero、 R-Zero,以及工具智能体版的 Tool-R0——让同一个模型既当提议者又当解题者,把任务分布与权重一起协同进化,并把奖励锚定在一个代码/工具 verifier 上。这相当于把环境扩展折叠进了模型自身。
- 环境 ⇄ harness。 SEAL 把基于 verifier 的失败诊断同时转化为一个不断演化的训练期接口**和被重新加权的策略更新;Socratic-SWE 则从轨迹中长出自己的任务课程。
目前还没有任何系统能把这三者同时端到端地跑起来——那就是开放的前沿。而且按 Lin et al. (2026) 的建议,当你真的把这些杠杆组合起来时,把模型预算花在解题智能体上、而非进化器上,因为产出 harness 编辑几乎与能力档位无关,但使用它们却并非如此。
对照 —— 环境扩展。 这其中的三个——验证、任务供给,以及过拟合/污染——逐字逐句就是环境扩展那篇博文的开放挑战。这是最有力的证据,说明它们并不是两个领域,而是从两个循环来看的同一个问题。
小结。 诚实的记分卡:verifier 的诚实度、评估成本、任务供给正是当下自演化 harness 结果最可能言过其实的地方——而它们也正是下一批论文必须用数字去证明自己的地方。
上手资源
这篇博文的一个目标是充当一条上手匝道。如果你想在这里真正做研究,入门门槛其实很低——一个 100 行的智能体、一个可验证的 benchmark,再加一个现成的优化器,一个下午就能让你拿到一个真实的结果。下面是一份精选的、可用的工具箱(链接截至 2026 年年中有效)。
优化器 / 库(搜索)。
| 工具 | 优化什么 | 链接 |
|---|---|---|
| DSPy | prompt + 流水线参数(一切都插入其上的底座) | github.com/stanfordnlp/dspy |
| GEPA | prompt,反思式 + Pareto(胜过 RL,样本高效) | github.com/gepa-ai/gepa |
| TextGrad | 通过”文本反向传播”优化任意文本变量 | github.com/zou-group/textgrad |
| Trace (OptoPrime) | 整个智能体工作流(表示为图) | github.com/microsoft/Trace |
| OpenEvolve | 整个代码库(开源版 AlphaEvolve) | github.com/algorithmicsuperintelligence/openevolve |
| DGM | 智能体自身的代码(达尔文式 archive) | github.com/jennyzzt/dgm |
| ADAS · Gödel Agent · AFlow | 智能体工作流 / 代码 | github.com/ShengranHu/ADAS · /Arvid-pku/Godel_Agent · /FoundationAgents/AFlow |
| AHE · SkillOpt | 完整 harness / 技能文档 | github.com/china-qijizhifeng/agentic-harness-engineering · aka.ms/SkillOpt |
代码智能体 harness(你要进化的底座)。 mini-swe-agent 是最好的研究默认选项——约 100 行代码,在 SWE-bench Verified 上 >74%,而且刻意保持极简,让你不会过拟合某个脚手架;SWE-agent 暴露了一个可配置的 ACI 用于消融实验;OpenHands 是一个完整平台;Aider 原生基于 git,并附带 Polyglot benchmark;Voyager 是技能库的模板。
Benchmark / 数据集(燃料)。 SWE-bench(+ Verified)和 Terminal-Bench 是代码智能体标准的适应度信号;SWE-Gym(Pan et al., 2024)在与 SWE-bench 不相交的仓库上提供了 2,438 个可执行的训练任务(适合做无泄漏的切分);Aider Polyglot 是一个干净的 transfer 集。两份持续更新的阅读清单在追踪这个领域:FrontisAI 的 Awesome-Self-Improving-Agents 和 self-evolving-agents 综述清单。
一条建议的上手路径。(1)选定一个底座 + 信号:在 SWE-bench Verified 上用
mini-swe-agent,或在 Terminal-Bench 上用一个终端智能体。(2)先试最便宜的那根杠杆:用 DSPy + GEPA 优化 prompt 或某个技能(技能文档则用 SkillOpt)——每行代码带来的收益最大,而且它能教会你 held-out 门控的纪律。(3)然后再去演化 harness 的更多部分——工具、中间件、记忆(AHE 风格),或整个智能体(DGM / OpenEvolve)。(4)从第一天起,就保留一个 held-out 测试切分和一个 transfer benchmark(在 SWE-Gym 上演化,在 SWE-bench Verified + Aider Polyglot 上报告结果)。燃料那一节的教训就是全部要义:难的不是提出修改,而是诚实地评估它们。
总结
到 2026 年,理解一个智能体的最佳方式是:一个冻结的模型加上一个可演化的 harness,而它性能中很大、很便宜、很可控的一部分就存在于这个 harness 里。本文勾勒了这个年轻的领域——它自动地改进 harness:一个单一的循环(表示 → 提出 → 验证 → 评估 → 选择 → 归档),人们会去演化的五个面(prompt → 工作流 → 整个智能体代码 → 技能库 → 完整 harness),以及用来搜索它们的五种优化器(贪心、文本梯度、演化式、Pareto/质量-多样性、树/MCTS)——其中 LLM 始终扮演梯度的角色。
贯穿全文的主线是:harness 演化是环境扩展的无梯度孪生:相同的目标、相同的燃料(可验证的任务 + 一个 verifier),只不过优化的是智能体的代码和 prompt,而不是它的权重。因此它继承了环境扩展三个最棘手的问题——任务供给、区分度 ≠ 难度(一个任务只有在候选之间存在分歧时才有助于选择),以及 verifier 的诚实度(如今更糟,因为一个自我修改的智能体可以编辑它自己手里的那把尺子)。而且它带着一个诚实的适用范围:harness 是第二根杠杆,在更弱的模型和更窄的 benchmark 上收益最大,随着基座模型变强而缩小——这正是为什么真正的归宿是把 harness、权重与环境协同进化到一起。
如果你把本文与那篇环境扩展博文并排来读,你就拥有了完整的图景:一篇讲的是如何制造可验证的经验;这一篇讲的是如何把它花在智能体的软件上,而完全不触碰它的权重。它们是围绕同一个想法的两个循环。
小结。 不要一上来就去够更大的模型或一次训练。一个智能体上最便宜、最可检视的杠杆就是 harness——而在 2026 年,你可以把这根杠杆放进一个循环里,让模型自己来扳动它。
致谢 / 来源:标注为”Image source”的图片转载自所引用的论文;其余所有图片均为原创。若干 2026 年的 harness 论文使用了前向标注日期(forward-dated)的模型名称;绝对数字仅用于方法示意——请看 delta。
如何引用
Zhang, Jiaxin. (Jun 2026). Self-Evolving Agentic Harnesses. Jiaxin Zhang’s Blog. https://jxzhangjhu.github.io/blog/2026/self-evolving-agentic-harnesses/
@article{zhang2026selfevolvingharness,
title = "Self-Evolving Agentic Harnesses",
author = "Zhang, Jiaxin",
journal = "Jiaxin Zhang's Blog",
year = "2026",
month = "Jun",
url = "https://jxzhangjhu.github.io/blog/2026/self-evolving-agentic-harnesses/"
}
参考文献
[1] Emre Can Acikgoz, et al. “Tool-R0: Self-Evolving LLM Agents for Tool-Learning from Zero Data.” arXiv:2602.21320, 2026.
[2] Lakshya A. Agrawal, et al. “GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning.” arXiv:2507.19457, 2025.
[3] Lirong Che, et al. “DemoEvolve: Overcoming Sparse Feedback in Agentic Harness Evolution with Demonstrations.” arXiv:2605.24539, 2026.
[4] Mengzhuo Chen, et al. “From Failed Trajectories to Reliable LLM Agents: Diagnosing and Repairing Harness Flaws (HarnessFix).” arXiv:2606.06324, 2026.
[5] Mingju Chen, et al. “HarnessForge: Joint Harness and Policy Evolution for Adaptive Agent Systems.” arXiv:2606.01779, 2026.
[6] Ching-An Cheng, et al. “Trace is the Next AutoDiff: Generative Optimization with Rich Feedback, Execution Traces, and LLMs.” arXiv:2406.16218, 2024.
[7] Darwin Agent Team. “HarnessX: A Composable, Adaptive, and Evolvable Agent Harness Foundry.” arXiv:2606.14249, 2026.
[8] Chrisantha Fernando, et al. “Promptbreeder: Self-Referential Self-Improvement Via Prompt Evolution.” arXiv:2309.16797, 2023.
[9] Huan-ang Gao, Jiayi Geng, et al. “A Survey of Self-Evolving Agents: What, When, How, and Where to Evolve.” arXiv:2507.21046, 2025.
[10] Prannay Hebbar, et al. “SIA: Self Improving AI with Harness & Weight Updates.” arXiv:2605.27276, 2026.
[11] Shengran Hu, Cong Lu, Jeff Clune. “Automated Design of Agentic Systems.” arXiv:2408.08435, 2024.
[12] Yihao Hu, et al. “SEAL: Synergistic Co-Evolution of Agents and Learning Environments.” arXiv:2605.24426, 2026.
[13] Chengsong Huang, et al. “R-Zero: Self-Evolving Reasoning LLM from Zero Data.” arXiv:2508.05004, 2025.
[14] Che Jiang, Jincheng Zhong, et al. “Self-Improving Agents in the Era of Experience: A Survey of Self- to Meta-Evolution.” Tsinghua University / Frontis.AI, 2026.
[15] Carlos E. Jimenez, John Yang, et al. “SWE-bench: Can Language Models Resolve Real-World GitHub Issues?” arXiv:2310.06770, 2023.
[16] Omar Khattab, et al. “DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines.” arXiv:2310.03714, 2023.
[17] Yoonho Lee, et al. “Meta-Harness: End-to-End Optimization of Model Harnesses.” arXiv:2603.28052, 2026.
[18] Jiahang Lin, Shichun Liu, et al. “Agentic Harness Engineering: Observability-Driven Automatic Evolution of Coding-Agent Harnesses.” arXiv:2604.25850, 2026.
[19] Minhua Lin, et al. “Harness Updating Is Not Harness Benefit: Disentangling Evolution Capabilities in Self-Evolving LLM Agents.” arXiv:2605.30621, 2026.
[20] Zewen Liu, et al. “Adaptive Auto-Harness: Sustained Self-Improvement for Agentic System Deployment on Open-Ended Task Streams.” arXiv:2606.01770, 2026.
[21] Xinghua Lou, Miguel Lázaro-Gredilla, et al. “AutoHarness: Improving LLM Agents by Automatically Synthesizing a Code Harness.” arXiv:2603.03329, 2026.
[22] Aman Madaan, et al. “Self-Refine: Iterative Refinement with Self-Feedback.” arXiv:2303.17651, 2023.
[23] Mike A. Merrill, et al. “Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces.” arXiv:2601.11868, 2026.
[24] Jingwei Ni, et al. “Trace2Skill: Distill Trajectory-Local Lessons into Transferable Agent Skills.” arXiv:2603.25158, 2026.
[25] Xuying Ning, et al. “Code as Agent Harness: Toward Executable, Verifiable, and Stateful Agent Systems.” arXiv:2605.18747, 2026.
[26] Alexander Novikov, et al. “AlphaEvolve: A Coding Agent for Scientific and Algorithmic Discovery.” arXiv:2506.13131, 2025.
[27] Jiayi Pan, Xingyao Wang, et al. “Training Software Engineering Agents and Verifiers with SWE-Gym.” arXiv:2412.21139, 2024.
[28] Wenbo Pan, et al. “Evolving Agents in the Dark: Retrospective Harness Optimization via Self-Preference over Trajectory Rollouts (RHO).” arXiv:2606.05922, 2026.
[29] Noah Shinn, et al. “Reflexion: Language Agents with Verbal Reinforcement Learning.” arXiv:2303.11366, 2023.
[30] Guanzhi Wang, et al. “Voyager: An Open-Ended Embodied Agent with Large Language Models.” arXiv:2305.16291, 2023.
[31] Xingyao Wang, et al. “OpenHands: An Open Platform for AI Software Developers as Generalist Agents.” arXiv:2407.16741, 2024.
[32] Chuan Xiao, et al. “Socratic-SWE: Self-Evolving Coding Agents via Trace-Derived Agent Skills.” arXiv:2606.07412, 2026.
[33] Chengrun Yang, et al. “Large Language Models as Optimizers (OPRO).” arXiv:2309.03409, 2023.
[34] John Yang, Carlos E. Jimenez, et al. “SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering.” arXiv:2405.15793, 2024.
[35] Yifan Yang, et al. “SkillOpt: Executive Strategy for Self-Evolving Agent Skills.” arXiv:2605.23904, 2026.
[36] Xunjian Yin, et al. “Gödel Agent: A Self-Referential Agent Framework for Recursive Self-Improvement.” arXiv:2410.04444, 2024.
[37] Mert Yuksekgonul, et al. “TextGrad: Automatic ‘Differentiation’ via Text.” arXiv:2406.07496, 2024.
[38] Eric Zelikman, et al. “Self-Taught Optimizer (STOP): Recursively Self-Improving Code Generation.” arXiv:2310.02304, 2023.
[39] Hangfan Zhang, et al. “Self-Harness: Harnesses That Improve Themselves.” arXiv:2606.09498, 2026.
[40] Jenny Zhang, Shengran Hu, et al. “Darwin Gödel Machine: Open-Ended Evolution of Self-Improving Agents.” arXiv:2505.22954, 2025.
[41] Jiayi Zhang, et al. “AFlow: Automating Agentic Workflow Generation.” arXiv:2410.10762, 2024.
[42] Qizheng Zhang, et al. “Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models (ACE).” arXiv:2510.04618, 2025.
[43] Andrew Zhao, et al. “Absolute Zero: Reinforced Self-play Reasoning with Zero Data.” arXiv:2505.03335, 2025.