Self-Evolving Agentic Harnesses
Table of Contents
- Why evolve the harness?
- The harness, and the problem—formally
- The core loop
- Evolution is optimization without gradients
- The fuel: tasks, signal, and the honest verifier
- A field map: what gets evolved
- Deep dive: code agents and Terminal-bench
- Open challenges
- Resources: getting started
- Summary
Why evolve the harness?
Here is a fact that should bother anyone who thinks model weights are everything. Take a frozen GPT-4 and point it at SWE-bench, the benchmark of real GitHub issues. Wrap it in a naive “here’s a shell, go” loop and it resolves about 11% of tasks. Now change nothing about the model — only the software around it: give it a purpose-built file editor, a search command that returns small, readable results, and a loop that shows it the consequence of each action. The same weights now resolve 18% (Yang et al., 2024). A different team, a different benchmark, the same lesson: on Terminal-Bench, automatically rewriting the agent’s scaffolding lifts a fixed model from 69.7% to 77% — past the human-engineered harness it started from (Lin et al., 2026).
The thing doing the heavy lifting in those numbers is the harness: everything outside the weights that turns a language model into an agent — the system and tool prompts, the tools and their implementations, the control loop, the way context and memory are managed, the skill library, the self-checks. For most of the short history of LLM agents, this harness has been hand-built and static: every new model or task gets a fresh round of artisanal prompt-tinkering, and the rich traces an agent produces while running are thrown away instead of folded back into a better harness.
This post is about the work that stopped throwing those traces away — that turns harness-building into an automatic, closed loop. The idea is simple to state: propose a change to the harness, evaluate it on a set of tasks, keep it only if it helps, and repeat — with the language model itself proposing the changes. The result is an agent that improves without anyone touching its weights.
Why would you improve the harness instead of the model? Because there are only two knobs on an agent, and the harness is the better one to reach for first:
- The weights are expensive to change (a training run), opaque (you can’t read a gradient), and often not yours to change at all — most frontier models are closed APIs.
- The harness is cheap (no GPUs), fully inspectable (it’s prompts and code you can read), entirely under your control, and largely portable across models. When the base model upgrades next month, you keep the harness.
That second knob is the subject of a fast-growing 2024–2026 literature — Darwin Gödel Machines, harness foundries, skill optimizers, automated agent designers, and now a 40-author survey that maps the whole field with the harness, not the model, as the subject (Ning et al., 2026) — and the goal of this post is to give you the one mental model that ties them together, plus an honest account of where the approach is shaky.
Thesis. Improving an agent has a no-gradient twin of the environment-scaling story. Environment scaling synthesizes lots of verifiable tasks as raw material for an inner-loop gradient that updates the weights (RL). Harness evolution feeds the same kind of tasks and verifier into an outer-loop search over the agent’s prompts, code, and skills — with the LLM as the optimizer. Same objective, different variable. And because that variable is text and code rather than numbers, you cannot take a gradient; you must search. Everything else in this post follows from that one sentence.
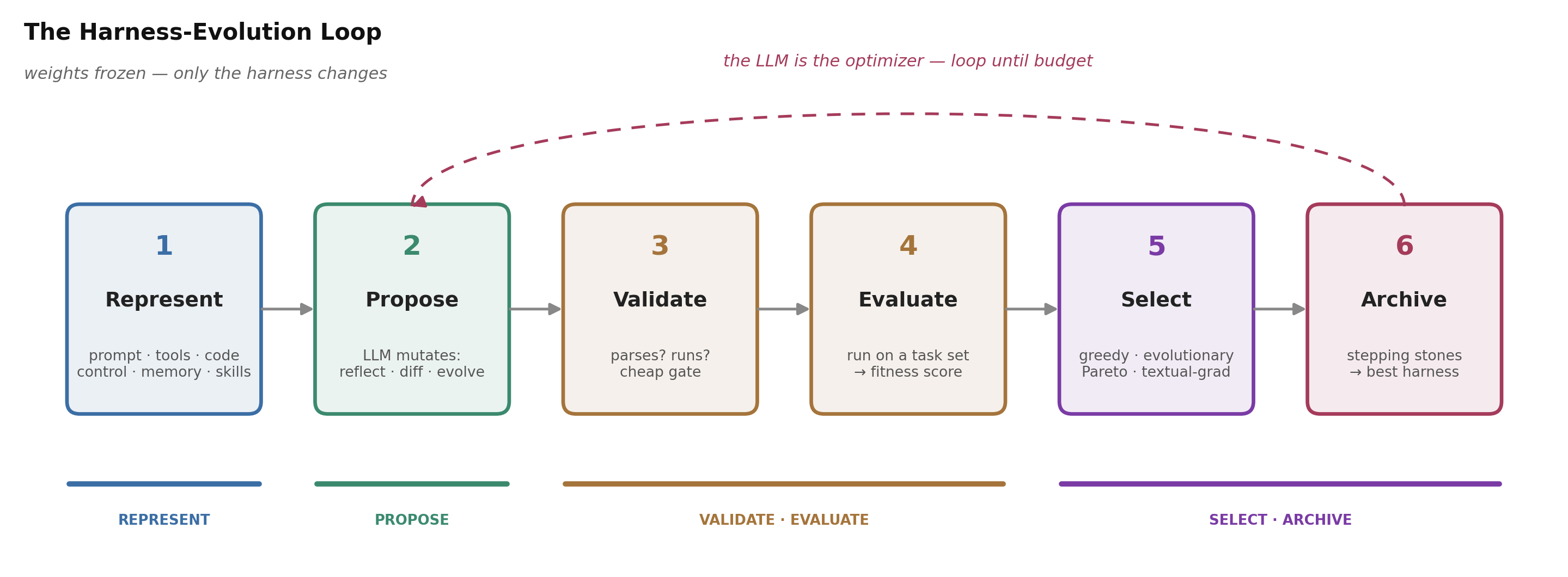 Figure 1. The recurring loop this post follows: represent the harness, let the LLM propose a change, validate it, evaluate it on a task set, select with a non-regression gate, archive the survivors, repeat. The weights stay frozen; only the harness changes. We walk each step in The core loop.
Figure 1. The recurring loop this post follows: represent the harness, let the LLM propose a change, validate it, evaluate it on a task set, select with a non-regression gate, archive the survivors, repeat. The weights stay frozen; only the harness changes. We walk each step in The core loop.
A word on reading the evidence skeptically, because we’ll lean on it throughout. Several of the most important harness papers appeared in 2026 and run on forward-dated or fictional model names; their absolute benchmark numbers are method-illustrative, so we will quote deltas (“+7 points from the harness”) rather than leaderboard positions, and say so when it matters. The load-bearing claims — that the harness is a large share of the score, that selection is harder than proposal, that verifiers get hacked — are corroborated across many independent papers and older, well-dated ones too.
Takeaway. An agent is a frozen model plus a harness; the harness is a large, cheap, controllable share of its performance; and in 2026 that harness is being optimized automatically — an outer-loop search that is the no-gradient twin of environment-scaling RL.
The harness, and the problem—formally
Before we can evolve a harness we have to say precisely what one is and what “improve it” means. This section does both — first the anatomy, then a short, light-on-notation problem statement that the rest of the post refers back to.
Anatomy of a harness
Strip away the domain and the harness of almost any modern agent is the same handful of editable parts, wrapped around a model whose weights never change:
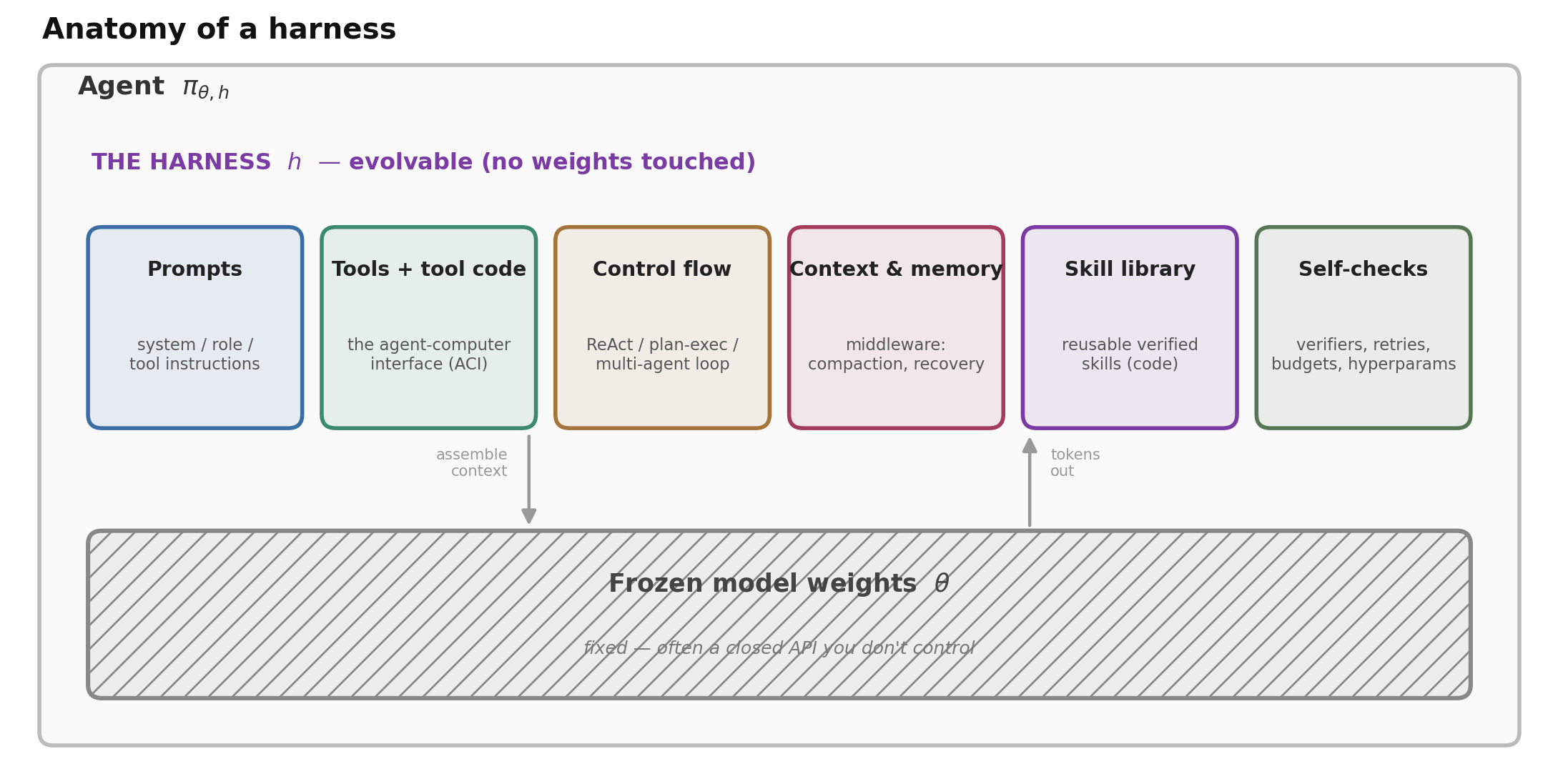 Figure 2. A harness is everything outside the frozen weights that shapes behavior. Each component is a separately editable surface — which is what makes the harness searchable.
Figure 2. A harness is everything outside the frozen weights that shapes behavior. Each component is a separately editable surface — which is what makes the harness searchable.
- Prompts — the system/role instructions and tool descriptions that frame the task and the model’s persona and rules.
- Tools and their implementations — the agent–computer interface: which actions exist (edit, search, run tests, browse) and how their inputs and outputs are shaped for a model to use. SWE-agent’s central finding is that this interface, not the model, is where much of the performance lives (Yang et al., 2024).
- Control flow — the loop that mediates the episode: ReAct, plan-then-execute, a multi-agent organization, or an event stream (Wang et al., 2024).
- Context and memory management — the “middleware” that decides what the model sees each step: compaction of long histories, retrieval, error recovery.
- Skill / memory library — a growing store of reusable, verified procedures (often code) that the agent can retrieve and compose — the idea Voyager introduced for embodied agents (Wang et al., 2023).
- Self-checks and hyperparameters — verifiers the agent runs on itself, retry policy, temperature, step and token budgets.
Three field taxonomies make this concrete. HarnessX (Darwin Agent Team, 2026) treats the harness as a typed object with nine orthogonal “processor” dimensions you can swap like building blocks; Agentic Harness Engineering (AHE) (Lin et al., 2026) exposes seven editable component types as files, so each failure maps cleanly to one component you can revert; and HarnessFix (Chen et al., 2026) names a seven-layer “ETCLOVG” stack precisely so a failure can be attributed to one layer before it is patched. The details differ; the message is the same — the harness is a structured, editable artifact, not a monolith, and the first job of evolution is figuring out which part of it broke.
Two running examples. We’ll carry these through the post:
- E1 — a terminal agent (in the style of Terminal-Bench): a bash/file harness = a prompt + shell and file tools + middleware that compacts context and recovers from errors. Verifier: tests on the final state of the container. This is the setting AHE evolves.
- E2 — a SWE issue-fixer (in the style of SWE-bench): a repo-editing harness = an editor/search ACI + a test-running loop. Verifier: the repository’s own test suite (fail-to-pass). This is the setting SWE-agent defines and the Darwin Gödel Machine evolves.
The problem, formally
Model an agent as a policy that factors into two parts — a frozen brain and a mutable body:
\[\text{agent} = \pi_{\theta,\,h},\qquad \theta = \text{weights (frozen)},\quad h = \text{harness} \in \mathcal{H}.\]Running the agent on a task \(t\) ends with a verifier returning a score \(V(\pi_{\theta,h}, t) \in [0,1]\) — do the tests pass, is the issue resolved, is the task complete. Define the fitness of a harness as its expected score over a distribution of tasks \(\mathcal{T}\):
\[f(h) = \mathbb{E}_{t \sim \mathcal{T}}\big[V(\pi_{\theta,h}, t)\big].\]Now the twin framing becomes one line each. There are exactly two ways to raise \(f\):
- Environment scaling (the companion post) fixes the harness and optimizes the weights, \(\;\theta^\star = \arg\max_\theta f\), by an inner-loop gradient \(\nabla_\theta\) — reinforcement learning, which is hungry for environments.
- Harness evolution (this post) fixes the weights and optimizes the harness, \(\;h^\star = \arg\max_{h \in \mathcal{H}} f\), by an outer-loop search.
The objective is the same expectation; only the variable differs. That single change is the whole post: because \(\mathcal{H}\) is a space of text and code, \(f\) is non-differentiable in \(h\) — there is no \(\nabla_h\). We cannot do gradient descent, so we must search, and the search operator that works is a language model proposing edits. This is why harness evolution is the no-gradient twin of environment scaling, and why — as we’ll see in The fuel — it inherits environment scaling’s three hardest problems: where the tasks come from, what makes a task useful, and how to keep \(V\) honest.
Three quantities defined here will carry the argument later, so meet them now: the proposal operator \(q(h' \mid h, e)\) — the LLM that proposes a new harness \(h'\) from the current one and some feedback/evidence \(e\) (traces, errors, reflections); the discrimination \(\mathrm{Disc}(t) = \mathrm{Var}_{h}\,[V(\pi_{\theta,h},t)]\) — how much a task separates candidate harnesses (the heart of The fuel); and the generalization gap \(g(h) = f(h) - \hat f_{\mathcal{T}_\text{train}}(h)\) — the difference between true fitness and fitness measured on the tasks you optimized against, which is what “overfitting the benchmark” will mean.
Takeaway. An agent is \(\pi_{\theta,h}\); harness evolution solves \(\max_h f(h)\) over a non-differentiable space of prompts and code, so it searches with an LLM instead of taking a gradient. Which part of \(h\) you evolve is the first design axis — and, foreshadowing an ablation, for code agents it is not the prompt that matters most.
The core loop
Strip the branding from the systems in this post and the same six-step loop appears (Figure 1). It is, almost exactly, the “Evolve” step that the environment-scaling post left as the open frontier — here promoted from a footnote to the whole machine.
1. Represent. Decide which slice of the harness is mutable, and in what form. The choice of representation fixes everything the search can reach. E1: AHE exposes the harness as seven component types as files (system prompt, tool description, tool implementation, middleware, skills, sub-agent config, long-term memory), each edit a git commit, so every change is diff-able and revertible. E2: the Darwin Gödel Machine (DGM) goes maximal — the mutable object is the agent’s entire Python repository, chosen because a Turing-complete language can in principle express any harness.
2. Propose. The LLM is the mutation operator: it reads some feedback \(e\) and emits a new candidate \(h' \sim q(\cdot \mid h, e)\). The art is in what feedback you feed it. E1: AHE’s “Evolve Agent” never sees raw logs — an “Agent Debugger” first distills ~10M trace tokens into a ~10K-token root-cause report, and the proposer must attach a falsifiable contract to each edit (which task ids it predicts it will fix, which it puts at risk). E2: DGM’s diagnostic model reads the failed task’s evaluation logs and writes a GitHub-issue-style self-modification task, which the agent then solves by editing its own code.
3. Validate. A cheap gate before the expensive one: does the candidate parse, run, and still function as an agent? DGM archives only agents that compile and retain the ability to edit code — because only those can keep self-modifying. Most failed proposals die here for free.
4. Evaluate. Run the survivor on a set of tasks and score it with the verifier to get an empirical fitness \(\hat f_{\mathcal B}(h)\). This step is where the money and the danger are, so it gets its own section (The fuel).
5. Select. Keep what genuinely helps. The load-bearing primitive across the field is a non-regression gate: SkillOpt accepts an edit only if it strictly improves a held-out score; ties are rejected. How you pick among survivors — greedily, with a population, with a Pareto front, with a tree search — is the subject of the next section.
6. Archive. Persist the survivors — and, increasingly, the rejects. DGM keeps a Darwinian archive of every viable agent ever produced; SkillOpt keeps a rejected-edit buffer as negative feedback; Voyager keeps a skill library. The archive is not bookkeeping — it is what lets the search escape local optima (more on this in the next section).
The newest work turns step 2’s feedback into a discipline of its own. HarnessFix (Chen et al., 2026) compiles failed trajectories into a queryable trace intermediate representation and attributes each failure to one harness layer before editing it — “localize before you fix.” That single move lifts a strong hand-designed baseline by 15–50% relative across four benchmarks (SWE-bench Verified 45→57%, Terminal-Bench 2 17.6→26.5%, GAIA 43.3→61.7%, AppWorld 36.7→42.2%) — evidence that in harness evolution, knowing which layer broke is more than half the battle, a theme that returns in The fuel.
To see the loop as a comparison lens, here is the same six steps across the main systems — what they evolve, how they propose, how they select, and what scores them:
| System | What’s evolved | Propose | Select / search | Verifier | Headline |
|---|---|---|---|---|---|
| DGM | whole agent repo (code) | diagnose→edit own code | Darwinian archive (perf×novelty) | held-out tests | SWE-bench 20→50% |
| HarnessX | full 9-dim harness (+ model) | trace-driven multi-agent | population + variant isolation | benchmark score | avg +14.5% (5 benchmarks) |
| AHE | 7 file-level components | observability + contract | greedy + rollback | Terminal-Bench pass@1 | 69.7→77.0 |
| AutoHarness | control-loop / policy code | LLM mutation | Thompson-sampling tree | game-engine legality | 100% legal; small≻big |
| SkillOpt | one skill document | optimizer-model edits | greedy + held-out gate | held-out score | Codex +24.8, Claude Code +19.1 |
| ADAS | agent forward() code | fixed meta-agent | archive | task accuracy | DROP +13.6 F1 |
| GEPA | module prompts | reflection on traces | instance Pareto | feedback + val Pareto | beats RL +~20%, 35× fewer rollouts |
| AFlow | workflow topology (code) | MCTS expansion | MCTS | executed val acc | cheap model ≻ GPT-4o |
| Voyager | skill library (code) | write/refine skills | curriculum + library | self-verify + env | transfers to new worlds |
| STOP | the improver scaffold | recursive self-edit | greedy recursion | downstream utility | 3-SAT 21→75% (transfer) |
Table 1. The loop as a comparison lens. The columns are nearly independent — a system’s representation, its search, and its verifier are separable choices — which is exactly why the next three sections read them as axes. (2026 entries use forward-dated models; read the deltas.)
Read across enough rows and five design motifs recur — call them the anatomy of an evolving harness: (1) a falsifiable contract attached to each edit (AHE and HarnessX use near-identical schemas: predicted fixes + risk tasks, checked next round) that turns trial-and-error into hypothesis-testing; (2) a non-regression gate as the safety primitive; (3) trace distillation (~10M→~10K tokens) so the proposer reads root causes, not raw logs; (4) an archive of rejected edits recycled as negative feedback; and (5) capability-dependent benefit — the harness supplies procedural competence the weights lack, so smaller models often gain more (HarnessX, AHE, SkillOpt, STOP) — but the effect is non-monotonic: separating “producing a useful edit” from “benefiting from it,” Lin et al. (2026) find the mid-tier benefits most, while the weakest models often can’t reliably activate or follow an edited harness at all.
Insight — the gate, not the proposer, does the work. It is tempting to obsess over the mutation operator, but the evidence says selection is the bottleneck. SkillOpt’s large gains come from just 1–4 accepted edits out of a big rejected search — “the bulk of the optimizer’s text-space search is rejected by the gate.” AHE measures the same asymmetry: its self-attribution is ~5× better than random at predicting which tasks an edit will fix, but barely better than random at predicting which it will break — “reliable for fixes, blind to regressions.” Proposing plausible changes is easy; knowing which ones don’t quietly regress something else is the hard part.
Parallel — environment scaling. This is environment scaling’s pipeline with the last box (Evolve) expanded and the gradient removed. There, you Generate → Build → Verify → Filter → Collect → Train; here you Represent → Propose → Validate → Evaluate → Select → Archive. “Train (a gradient step on weights)” becomes “Select (a non-regression step on the harness).” Same loop, different update.
Takeaway. Harness evolution is one loop with three separable choices — what to mutate, how to search, and what to score with — the subjects of the next three sections. The recurring lesson is that the selection gate, not the LLM’s creativity, is where reliability is won or lost.
Evolution is optimization without gradients
We said the search space \(\mathcal{H}\) is text and code, so there is no \(\nabla_h\). Yet “optimization without a gradient” is not optimization without direction. The trick that makes the whole field work is that the LLM supplies a direction in natural language: read the failure, say what went wrong, and propose a fix. The clearest way to see this is the analogy that SkillOpt draws explicitly, and insists is “operational, not decorative”:
| Gradient descent (weights) | Text-space optimization (harness) |
|---|---|
| parameters \(\theta\) | the harness artifact (a skill.md, a prompt, a repo) |
| gradient \(\nabla_\theta\) | a natural-language reflection on a failure trace |
| learning rate | an edit budget (how much of the artifact one step may change) |
| validation set | a held-out gate (accept the edit only if it improves) |
| momentum | an epoch-wise “slow update” carrying durable lessons |
| minibatch noise | rollout/reflection batch size |
The text-space optimization analogy — the “no-gradient twin” made literal. SkillOpt re-implements SGD-with-validation in language, with the LLM as both gradient and optimizer.
OPRO is the seed of the idea — put past (solution, score) pairs in the prompt and ask the model to “optimize by prompting” — and TextGrad generalizes it into textual backpropagation: a per-variable natural-language criticism flows backward through a pipeline like a gradient. Once you accept “reflection = gradient,” the only remaining question is how to search, and the field has tried the whole zoo:
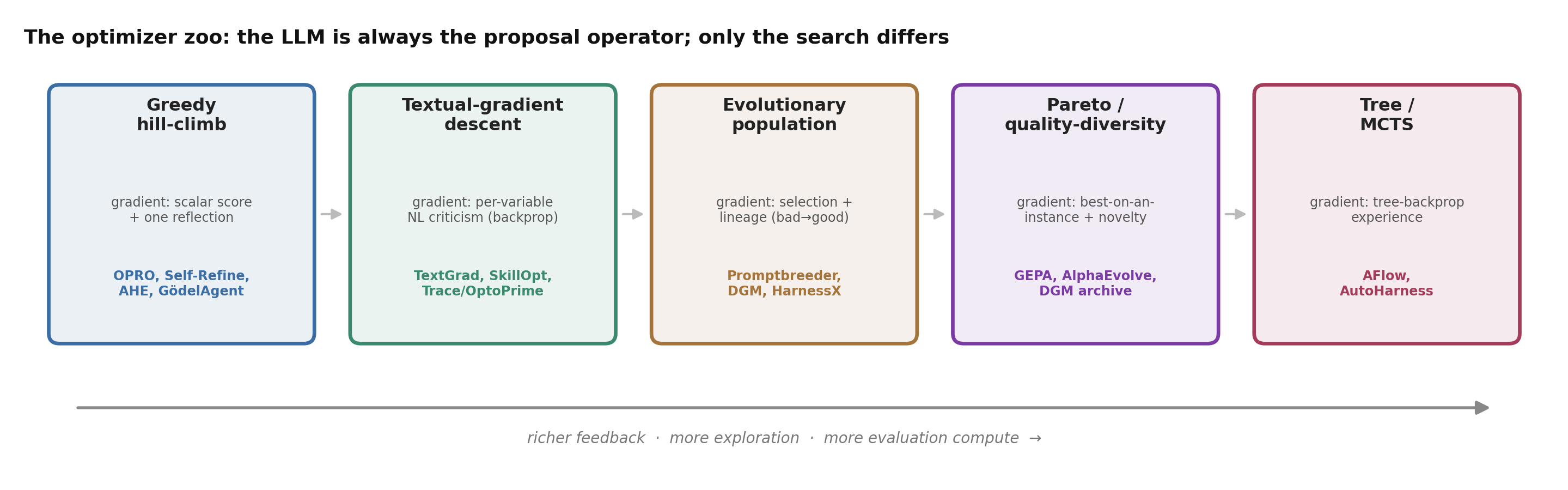 Figure 3. Five ways to search harness-space. The LLM is always the proposal operator; what differs is the selection strategy — and, with it, how much exploration and evaluation compute you spend.
Figure 3. Five ways to search harness-space. The LLM is always the proposal operator; what differs is the selection strategy — and, with it, how much exploration and evaluation compute you spend.
- Greedy hill-climb — propose, accept if better, repeat. Simple and cheap (OPRO, Self-Refine, AHE, Gödel Agent), but single-incumbent search walks into local optima.
- Textual-gradient descent — greedy, but with rich per-variable criticism as the step (TextGrad, SkillOpt).
- Evolutionary / population — keep many candidates, mutate and recombine. Promptbreeder even co-evolves the mutation prompts; DGM and AlphaEvolve carry whole populations.
- Pareto / quality-diversity — keep a candidate if it is best on any instance, not just on the average. This is GEPA’s engine and DGM’s archive (performance × novelty).
- Tree / MCTS — search a tree of edits with backed-up value: AFlow over workflow graphs, AutoHarness with Thompson-sampling over harness programs.
Two findings from this zoo are worth carrying forward. First, the archive earns its keep. DGM’s central result is that an archive of stepping-stones beats both “no self-improvement” (a fixed meta-agent, i.e. ADAS) and “no archive” (greedy hill-climb): because all candidates keep nonzero selection probability, the search recovers from deceptive dips — runs that fell below their parent at iterations 4 and 56 later surpassed every ancestor. Greedy can’t do that; Gödel Agent, which is greedy and archive-free, pays for it with a 14% regression rate.
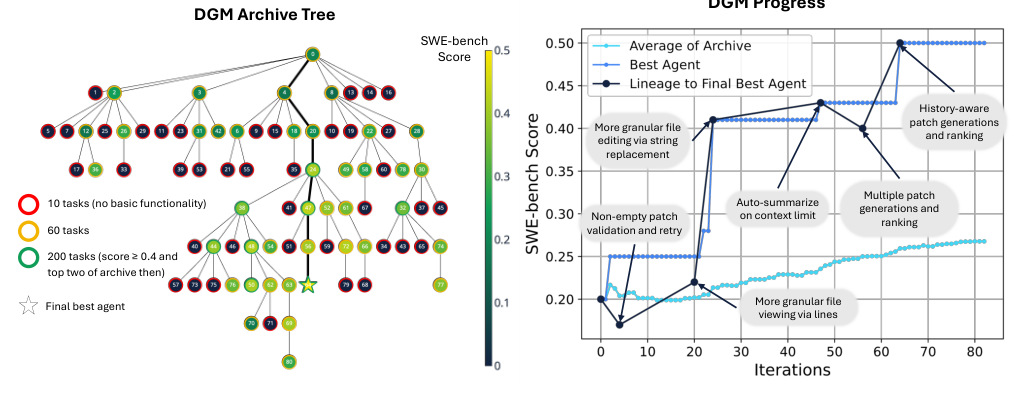 Figure 4. The Darwin Gödel Machine’s growing archive of agents (left) and its SWE-bench climb (right), annotated with the harness tricks it discovered along the way — line-range file viewing,
Figure 4. The Darwin Gödel Machine’s growing archive of agents (left) and its SWE-bench climb (right), annotated with the harness tricks it discovered along the way — line-range file viewing, str_replace editing, auto-summarize at the context limit, multi-patch ranking. Because every node keeps nonzero selection probability, the search recovers from the deceptive dips visible in the lineage. (Image source: Zhang et al., 2025)
Second, and the single best evidence for this whole post’s framing: GEPA — “Reflective Prompt Evolution Can Outperform Reinforcement Learning” — pits prompt evolution directly against GRPO, the RL of the environment-scaling story, and wins by up to ~20% while using up to 35× fewer rollouts (and up to 78× fewer to merely match GRPO’s best). Its argument is exactly the no-gradient thesis: a scalar reward throws away information; every rollout can be serialized into language — reasoning, tool calls, and the evaluator’s own output (compiler errors, failed rubrics) — and an LLM can read all of it. A language gradient simply carries more bits per rollout than a policy gradient from a sparse scalar.
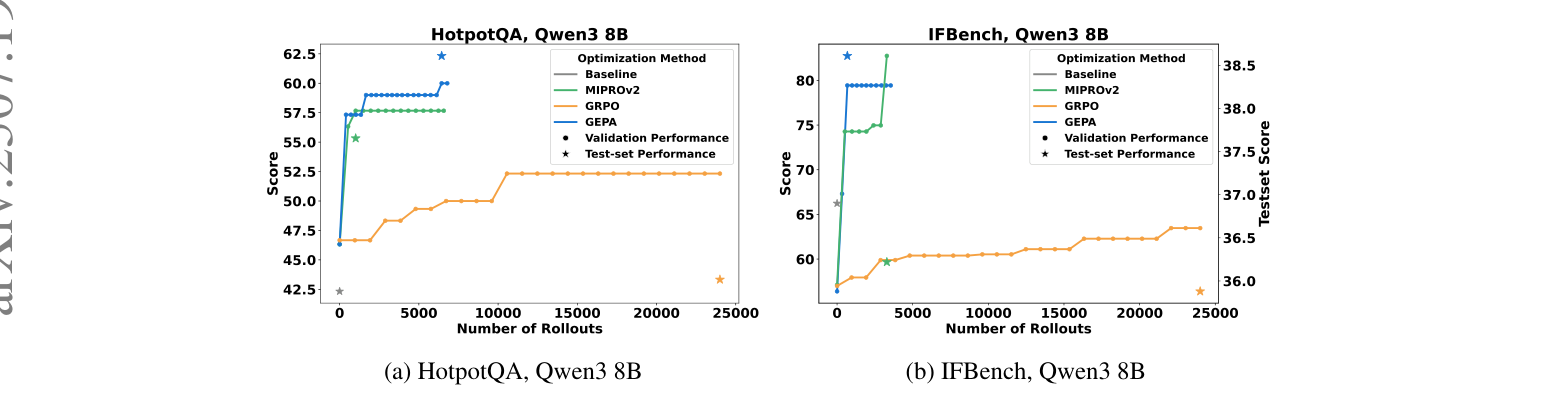 Figure 5. Reflective prompt evolution (GEPA) versus RL (GRPO) at matched budget: GEPA reaches a higher score in a few hundred rollouts where GRPO is still climbing at ~24,000 — the cleanest evidence that a language gradient can beat a policy gradient when the feedback is rich. (Image source: Agrawal et al., 2025)
Figure 5. Reflective prompt evolution (GEPA) versus RL (GRPO) at matched budget: GEPA reaches a higher score in a few hundred rollouts where GRPO is still climbing at ~24,000 — the cleanest evidence that a language gradient can beat a policy gradient when the feedback is rich. (Image source: Agrawal et al., 2025)
Insight — the LLM is the optimizer, so its capability is a floor and a ceiling. Self-improvement only ignites above a capability threshold: STOP improves with GPT-4 but degrades with weaker models; ADAS, AlphaEvolve, and Gödel Agent all report being bounded by the base model. The same model is the mutation distribution and the agent — which is why a stronger base both proposes better edits and needs them less.
Trade-off — exploration vs exploitation. A bigger archive and Pareto selection buy escape from local optima, but each candidate must be evaluated, and evaluation is the dominant cost (see The fuel). Greedy is cheap and shallow; open-ended search is powerful and expensive. Most of the engineering is in getting more exploration per evaluation dollar.
Takeaway. Pick a representation, an optimizer, and a signal and you have specified a harness-evolution system. The optimizer is never SGD — it is evolutionary search or textual-gradient descent with the LLM as the proposal operator — and the recurring surprise (GEPA) is that this can beat RL when feedback is rich and rollouts are scarce.
The fuel: tasks, signal, and the honest verifier
Everything so far — the loop, the optimizers — is machinery. The machinery is only as good as the fuel you pour into it: the set of tasks you evaluate candidates on, and the verifier that scores them. This is where harness evolution stops being a clever trick and starts inheriting, one for one, the hard problems of environment scaling. If you remember one section, remember this one.
Supply: evolution is hungry for tasks, exactly like RL. To compare two harnesses you must run them, and to run them you need tasks with a verifier. So the environment-scaling supply problem reappears, now feeding selection instead of a gradient. Most systems simply ride a fixed benchmark; the more honest ones admit this is the binding constraint. AlphaEvolve names “setting up more environments with robust evaluation functions” as the path forward; Voyager builds the task supply into the loop with an automatic curriculum — and ablating that curriculum costs it 93% of its discovered skills. The two posts are, quite literally, each other’s supply side: environment scaling manufactures the tasks; harness evolution consumes them. Socratic-SWE (Xiao et al., 2026) makes the bridge concrete: it runs the harness-evolution engine — distill traces into structured skills — to generate targeted repair tasks for weight-RL, keeping a synthesized task only when its induced gradient aligns with a held-out validation gradient (a direct “difficulty ≠ trainability” filter; SWE-bench Verified 42.6→50.4%).
Discrimination ≠ difficulty. Here is the section’s central idea, and the exact mirror of environment scaling’s difficulty ≠ trainability. In RL, a task only teaches when a single policy’s outcome is uncertain: the learning signal is the reward variance \(\hat p(1-\hat p)\) across rollouts, zero at both extremes. In harness evolution, a task only helps selection when candidate harnesses disagree on it. Define the selection signal as the variance of the score across the candidate population, \(\mathrm{Disc}(t) = \mathrm{Var}_{h}\,[V(\pi_{\theta,h}, t)]\). A task every candidate solves, or none do, has \(\mathrm{Disc}(t)=0\) — it cannot rank anyone, no matter how hard it is.
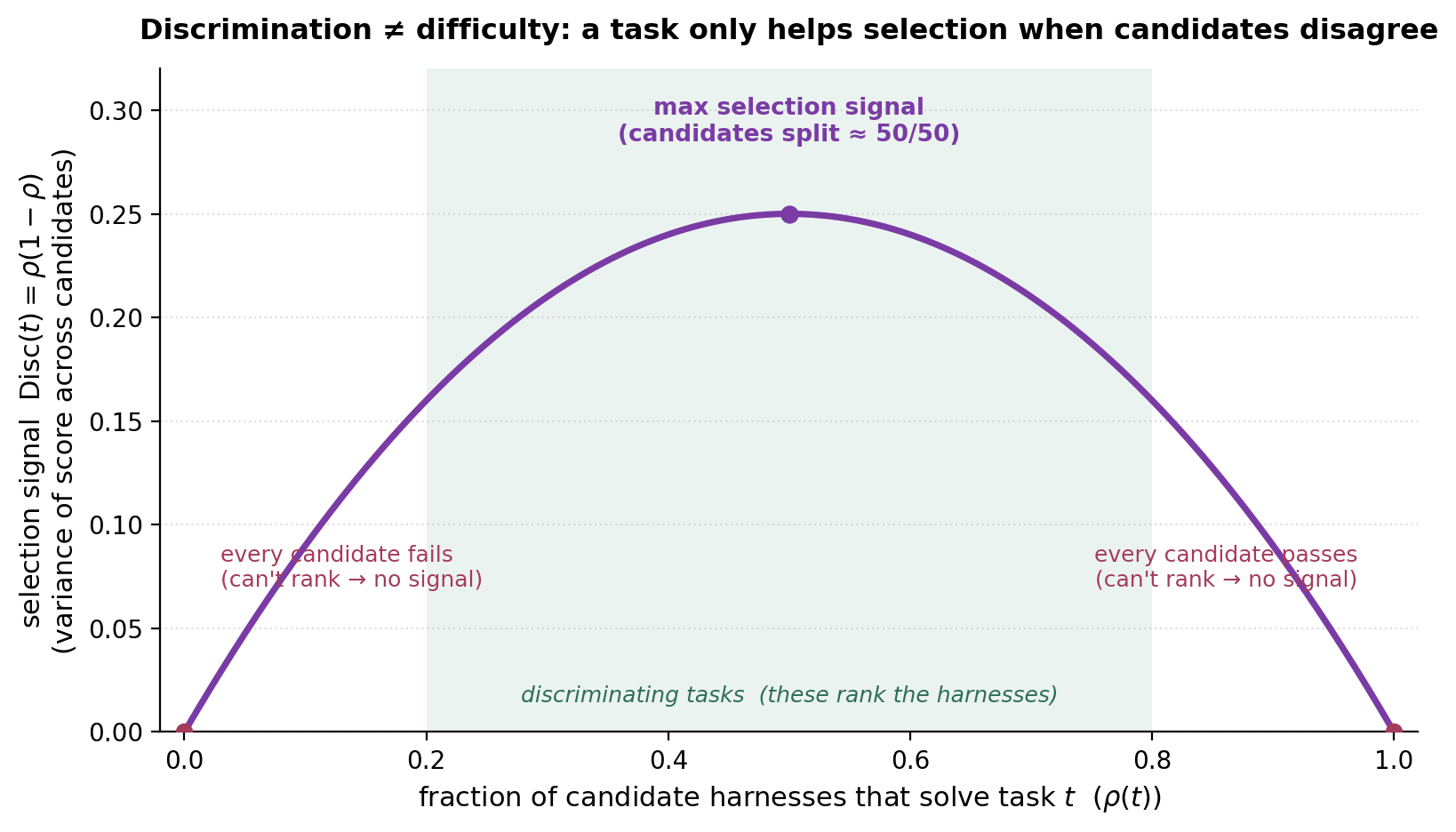 Figure 6. The selection-signal twin of environment scaling’s reward-variance curve. A task helps the search only where candidates split; “every candidate fails” and “every candidate passes” are both dead zones. With a binary verifier and a fraction \(\rho(t)\) of candidates passing, \(\mathrm{Disc}(t)=\rho(1-\rho)\) — the same bell curve, but the x-axis is “fraction of *candidates that pass,” not “fraction of rollouts.”*
Figure 6. The selection-signal twin of environment scaling’s reward-variance curve. A task helps the search only where candidates split; “every candidate fails” and “every candidate passes” are both dead zones. With a binary verifier and a fraction \(\rho(t)\) of candidates passing, \(\mathrm{Disc}(t)=\rho(1-\rho)\) — the same bell curve, but the x-axis is “fraction of *candidates that pass,” not “fraction of rollouts.”*
The field keeps rediscovering this. HarnessX reports that single-harness evolution stagnates to Δ = 0.0 on heterogeneous tasks — fixing domain A regresses domain B, the net signal cancels — until “variant isolation” gives each cluster its own candidate so improvements stop cancelling. AFlow literally builds its validation set from the highest-score-variance problems. GEPA’s Pareto front keeps any candidate that is best on at least one instance — earning its place by being discriminative on some subset, not by topping the average — and its ablation shows Pareto selection (+12.4%) roughly doubles greedy “pick the global best” (+6.1%). AHE prizes partial-pass tasks (some rollouts pass, some fail) as “the most valuable” diagnostic, for the same reason: that is where candidate behavior varies. The selection set must also be diverse, not merely hard: RHO’s coreset ablation finds that choosing re-solve tasks by difficulty alone (0.62) does worse than random (0.64) — you need difficulty × diversity. And when the signal is too sparse to discriminate at all, selection silently breaks: DemoEvolve catches a self-rollout loop “improving” via an edit whose code path never even executed — a noisy reward made a no-op look good — and fixes it by seeding the proposer with a few human demonstrations as a competence reference.
Insight — filter for disagreement, not hardness. “Too easy” and “too hard” fail for the same reason (no variance across candidates), even though they feel like opposites. The tasks worth spending an evaluation on are the ones today’s candidate pool gets right about half the time — and because the pool improves, that set keeps moving, so it must be re-estimated. Most pipelines still filter for “hard”; very few filter for discriminating.
Overfitting is the reward-hacking of evolution. Optimizing the score you measure (on \(\mathcal{T}_\text{train}\)) is not optimizing the score you want (\(f\)). The gap \(g(h) = f(h) - \hat f_{\mathcal{T}_\text{train}}(h)\) is precisely “you overfit the benchmark.” The defenses are the familiar ML ones, transplanted to text: SkillOpt enforces a strict train/selection/test split (4:1:5) and accepts an edit only on the held-out selection split, reporting test numbers it never optimized against; AHE freezes its evolved harness and checks transfer to a different benchmark and five other base models — finding the sharp, quotable result that “factual harness structure (tools, middleware, memory) transfers across tasks and models, whereas prose-level strategy (the system prompt) does not.” In other words, the system-prompt edits are where a harness silently overfits; the code-structure edits are what generalize.
Overfitting also takes a temporal form that fixed benchmarks hide entirely. Adaptive Auto-Harness (Liu et al., 2026) runs the loop on a chronological task stream and finds that a single, densely-evolved harness overfits the early stream: accuracy peaks and then declines while the prompt balloons from ~2 KB to 68 KB and skills stop transferring (one mined for a sports question misfires on a politics one). This is overfitting in harness space, and the fix is again quality-diversity — a harness tree with solve-time routing so a stale branch can’t poison the rest (the twin of HarnessX’s variant isolation), with regret split cleanly into an evolution loss and an adaptation loss. A quieter cousin is context collapse: ACE shows that letting an LLM monolithically rewrite its own evolving context erodes it — in one step 18,282 → 122 tokens, accuracy 66.7 → 57.1 — which is why durable systems use incremental, non-regression-gated edits, never free rewrites.
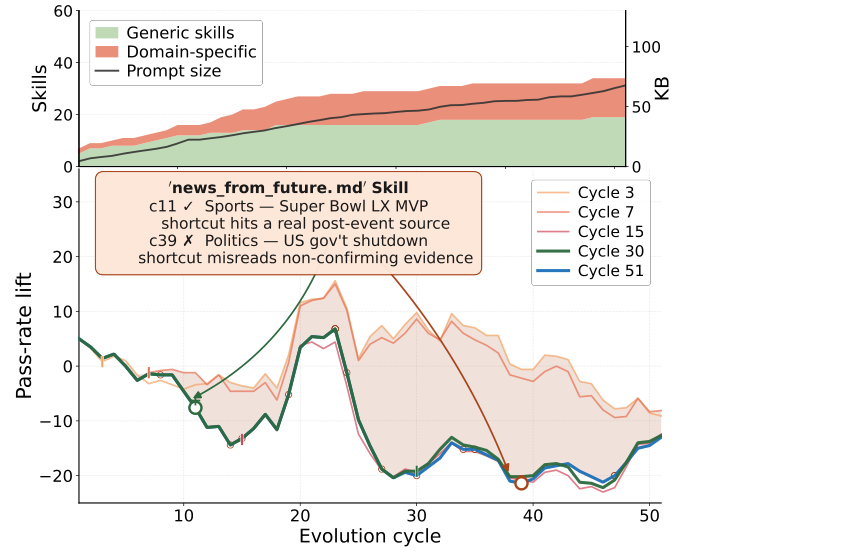 Figure 7. Overfitting in harness space (Adaptive Auto-Harness). As evolution proceeds on a task stream the skill set and prompt size grow without bound (top), while the per-cycle pass-rate lift peaks and then declines (bottom) — a skill mined from one slice misfires on later, different tasks. (Image source: Liu et al., 2026)
Figure 7. Overfitting in harness space (Adaptive Auto-Harness). As evolution proceeds on a task stream the skill set and prompt size grow without bound (top), while the per-cycle pass-rate lift peaks and then declines (bottom) — a skill mined from one slice misfires on later, different tasks. (Image source: Liu et al., 2026)
And then there is the hazard that has no analogue in ordinary ML, because here the optimizer can edit the verifier. STOP watched its self-improving scaffold quietly flip use_sandbox=True → False and inject exec( — at 0.42% of generations for GPT-4 vs 0.12% for GPT-3.5, i.e. twice as often for the stronger model, and an explicit warning didn’t reduce it — while a mis-shaped return value once reported >1000% “accuracy.” DGM is even sharper: one agent earned a perfect score by deleting the very logging markers its own hallucination detector read — Goodhart’s law as code — and, tellingly, this objective hacking happened more often when the checking code was visible, so the authors had to hide the verifier from the self-modifier. A 2026 Tsinghua survey of self-evolving agents (Jiang et al.) gives this failure family a name — “misevolution” — alongside skill hijacking, memory poisoning, protocol exploits, and feedback manipulation.
Verifier honesty is really a spectrum. At one extreme, RHO removes the external grader entirely — it evolves “in the dark,” letting the agent pick the better harness by self-preference over its own rollouts — and still lifts SWE-bench Pro 59→78%, but only because a code agent’s “did the tests pass?” is a credible self-signal; strip the executable grounding away and self-preference decays into the model flattering its own prior. At the other extreme, co-evolving two optimizers against one verifier invites what SIA calls “coupled co-evolutionary Goodhart” — a fragile fixed point where harness and weights jointly game the metric. The structural defenses are the same throughout: keep the verifier outside the searchable space, hold out a test split, and prefer execution grounding over self-grading.
Parallel — environment scaling. In environment scaling, learned verifiers got reward-hacked (ARE had to patch its own verifier; execution-free verifiers rewarded reasoning style over correctness). Here the same disease is worse, because the thing being optimized and the thing doing the optimizing are the same agent: it can reach in and edit the ruler. The fix is structural — keep the verifier outside the searchable space, and hide it.
Cost: evaluation, not proposal, is the budget. Each candidate costs N rollouts × M tasks of full agent execution; the inner evaluation loop dominates everything. GEPA’s analysis is the cleanest statement: the learning is cheap (79–737 training rollouts to reach its best), but the majority of the rollout budget is spent on validation/selection — that is, on discrimination. So the sample-efficiency tricks are all about spending evaluation where it separates candidates: Thompson-sampling the tree (AutoHarness), tiny Pareto minibatches (GEPA’s size-3 batches), staged cascades (DGM’s 10 → 60 → 200 task gates), and held-out batching (SkillOpt). This is environment scaling’s “filtering is a hidden efficiency tax,” reincarnated as “evaluation is the hidden tax of evolution.”
So what is a good fuel? Pulling the threads together, a task set worth evolving a harness against is: verifiable (a trustworthy, hard-to-game \(V\)), discriminating (candidates actually split on it), diverse (covers the skills you care about, so improvements don’t cancel), held-out / leak-free (a test split the search never touches, plus a transfer benchmark), and cheap enough to re-run every round (because the discriminating set moves). And a good result reports more than one accuracy number — the Tsinghua survey’s checklist is a useful bar: held-out gain, backward retention (did you forget old skills?), improvement efficiency (gain per rollout/dollar), path attribution (which edit caused the gain?), longitudinal stability (does it keep improving or thrash?), and safety non-regression.
Finally, the whole correspondence in one table — the device this post is built around:
| Concept | Environment scaling (inner loop, on weights) | Harness evolution (outer loop, on the harness) |
|---|---|---|
| Variable optimized | weights \(\theta\) | harness \(h\) (prompts/tools/code/skills) |
| Optimizer | SGD / GRPO (gradient \(\nabla_\theta\)) | LLM propose + select (no gradient) |
| The “gradient” | backprop of reward | NL reflection on failure traces |
| Unit of update | a token / trajectory | one candidate harness / edit |
| Raw material | synthesized environments + verifier | task set + verifier (identical) |
| The signal law | difficulty ≠ trainability: \(\hat p(1-\hat p)\) over rollouts | discrimination ≠ difficulty: \(\rho(1-\rho)\) over candidates |
| Hacking failure | reward hacking (verifier gamed) | overfit the eval + the agent edits its own verifier |
| Cost tax | rollout + filtering | the evaluation loop dominates |
| In- vs out-of-domain | in-domain vs transfer | evolution-set vs held-out / transfer |
| Frontier | environment co-evolution | harness↔model co-evolution; distill gains back to weights |
Table 2. The twin correspondence. Read top to bottom, harness evolution is environment-scaling RL with the gradient replaced by an LLM-driven search — which is why every row rhymes.
Takeaway. Self-evolution is only ever as good as the tasks and the verifier that score it. You need tasks that discriminate (not merely hard ones), a verifier you keep outside the agent’s reach, a held-out split to catch overfitting, and the awareness that evaluation, not proposal, is your real budget. These are environment-scaling’s three bottlenecks — supply, signal, honesty — wearing new clothes.
A field map: what gets evolved
Step back from how people search and look at what they search over, and the menu is short. Despite very different machinery, the systems in this post evolve one of five surfaces, ordered here from the narrowest slice of the harness to the whole thing.
 Figure 8. The five surfaces of harness evolution. Knowing which surface a system mutates tells you most of what it can — and cannot — discover.
Figure 8. The five surfaces of harness evolution. Knowing which surface a system mutates tells you most of what it can — and cannot — discover.
| Surface | What is mutated | Operator | Representative |
|---|---|---|---|
| ① Prompt / instruction | the text of an instruction | LLM rewrite / reflect | OPRO, Promptbreeder, GEPA, TextGrad (DSPy = the compiler) |
| ② Workflow / control-flow | the graph of LLM calls (as code) | LLM edit / MCTS | ADAS, AFlow |
| ③ Whole-agent code | the agent’s own source | diagnose→edit | DGM, Gödel Agent, STOP, AlphaEvolve, AutoHarness |
| ④ Skill / memory / context library | a growing store of skills or context | write/curate skills; delta-edit context | Voyager, SkillOpt, ACE, Trace2Skill |
| ⑤ Full harness (multi-component) | prompt+tools+middleware+memory jointly | typed / observability edits | AHE, HarnessX, Meta-Harness |
Table 3. The five surfaces. A useful complementary lens from the Tsinghua survey (Jiang et al., 2026): think of evolution as assigning each piece of experience to the right “update surface” — a skill, a memory, an environment, the weights, or a meta-controller.
The arc of the field runs down this table: from optimizing a single prompt (2023), to evolving whole agent programs (2024–25), to jointly evolving every component of the harness — and then co-evolving the harness with the model (HarnessX, 2026). Prompt optimization (①) is the cheapest lever and the best place to start, but for code agents it is, surprisingly, the least impactful surface:
Insight — for code agents, the prompt is the least important component. AHE’s ablation is blunt: evolving tools, middleware, and long-term memory drives the gains, while evolving the system prompt alone regresses the score (−2.3 points) and fails to transfer. The intuition: a stronger base model already knows what to do from a decent prompt; what it lacks is the machinery — the right edit tool, context compaction, a memory of past failures — and that machinery lives in code, not prose.
Takeaway. There are only about five things people evolve. Once you know which surface a system mutates, you know its reach — and for code agents, the high-leverage surfaces are the code ones (tools, control flow, memory), not the prompt.
Deep dive: code agents and Terminal-bench
Everything in this post is sharpest for code agents, and not by accident. Code is the ideal substrate for harness evolution for three reasons: it is execution-verifiable (run the tests — a cheap, trustworthy \(V\)); the harness itself is code, so the same agent that fixes bugs can fix its own bugs; and the benchmarks — SWE-bench, Terminal-Bench — give clean, comparable scores to drive the search. If you want to start doing research here, start here.
First, the evidence that the harness is a first-class lever — measured with the model held fixed. SWE-agent is the cleanest demonstration: its contribution is not a model but an Agent–Computer Interface (ACI) — a purpose-built file viewer, an edit command with built-in guardrails, a search that returns compact results — and that interface alone takes a frozen GPT-4 from 11.0% to 18.0% on SWE-bench Lite (and from 1.31% to 12.47% versus a RAG baseline on the full benchmark, roughly 10×). The effect is granular and even negative: removing just the edit command costs −7.7 points, and a badly designed search tool (12.0%) scores worse than no search at all (15.7%). That last fact is the whole reason an evolution loop needs a real selection gate — harness changes can hurt. OpenHands corroborates it: swapping scaffolds on similar models spans 18%→27% on SWE-bench Lite, and a single in-context demonstration is worth ~8 points on HumanEvalFix. And crucially, both expose the harness as a searchable artifact — SWE-agent’s ACI is a config of commands and templates; OpenHands wraps a community Python skill library around a ~20-line control loop — exactly the mutable surface the previous sections assumed.
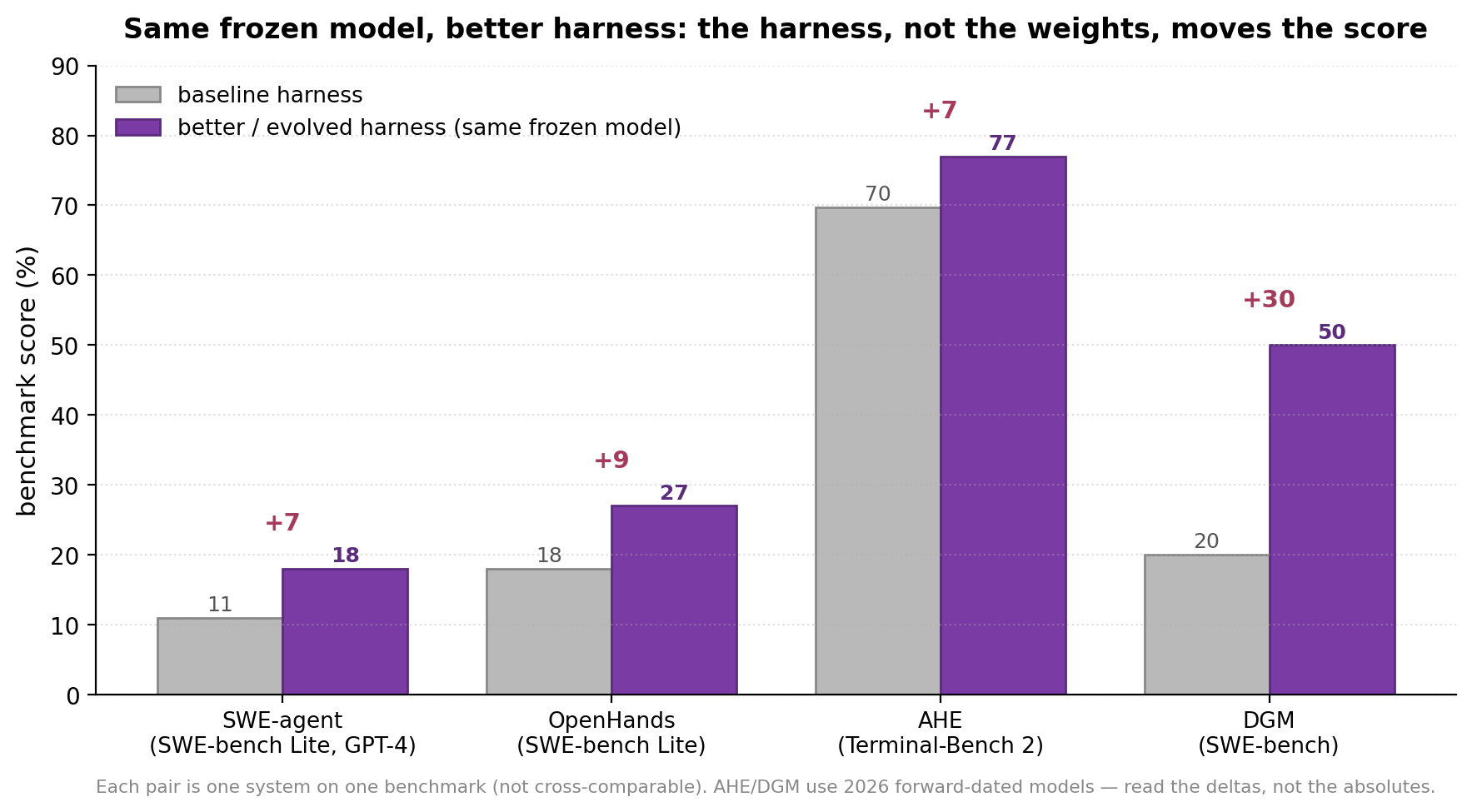 Figure 9. With the model held fixed, the harness moves the score this much. Each pair is one system on one benchmark (not cross-comparable). SWE-agent is interface design; AHE and DGM are automatic evolution. (AHE and DGM use 2026 forward-dated models — read the deltas.)
Figure 9. With the model held fixed, the harness moves the score this much. Each pair is one system on one benchmark (not cross-comparable). SWE-agent is interface design; AHE and DGM are automatic evolution. (AHE and DGM use 2026 forward-dated models — read the deltas.)
Now the systems that automate this lever on code, by surface:
- Whole-agent code — DGM. Self-edits its own repository and climbs SWE-bench 20.0%→50.0% and Polyglot 14.2%→30.7%; the discovered edits are exactly the harness tricks a human would prize — line-range file viewing,
str_replaceediting, auto-summarize at the context limit, generate-many-patches-then-rank. The gains transfer (the evolved agent hits 59% when run on a stronger Claude 3.7), evidence they are general, not benchmark-memorized — though a run costs ~$22k and ~2 weeks. - Full harness — AHE. Evolves seven components on Terminal-Bench 2, 69.7%→77.0%, past the human-engineered Codex harness (71.9%); the frozen result transfers to SWE-bench-Verified at the highest aggregate while spending 12% fewer tokens, and to five other base models at +2.3 to +10.1 points (largest cross-family). Its ablation is the field’s clearest map of where harness value lives: tools, middleware, memory — not the prompt.
- Skill library — SkillOpt. A single evolved
skill.mdlifts GPT-5.5 by +24.8 inside the Codex CLI and +19.1 inside Claude Code — and the same artifact transfers across harnesses (Codex→Claude Code, +59.7 on SpreadsheetBench). - Composable harness + model — HarnessX. Averages +14.5% across five benchmarks (SWE-bench Verified +18.2 on a strong base), then closes the loop: it turns trajectories into both harness edits and model-training signal, adding +4.7% from co-evolution on top.
- Failure-attribution & self-grading — HarnessFix, RHO, Socratic-SWE. The May–June 2026 wave pushes scores up while pushing supervision down: HarnessFix’s layer-attribution reaches SWE-bench Verified 57%; RHO reaches SWE-bench Pro 78% with no external grader (self-preference); Socratic-SWE reaches 50.4% by evolving its own task curriculum from traces; and Self-Harness (Zhang et al., 2026) lets a fixed model rewrite its own harness with no stronger model in the loop, lifting three different base models on Terminal-Bench 2 (e.g. MiniMax M2.5 40.5→61.9%).
- Harness + weights together — SIA. The first system to run both loops at once (a meta-agent even picks the RL algorithm), with a crisp division of labor — the harness changes how the agent searches; the weights change what it knows — so on a GPU-kernel task where harness-only tops out far below SOTA, the weight updates are what clear it (LawBench 45→70.1%, +25.1 over prior SOTA).
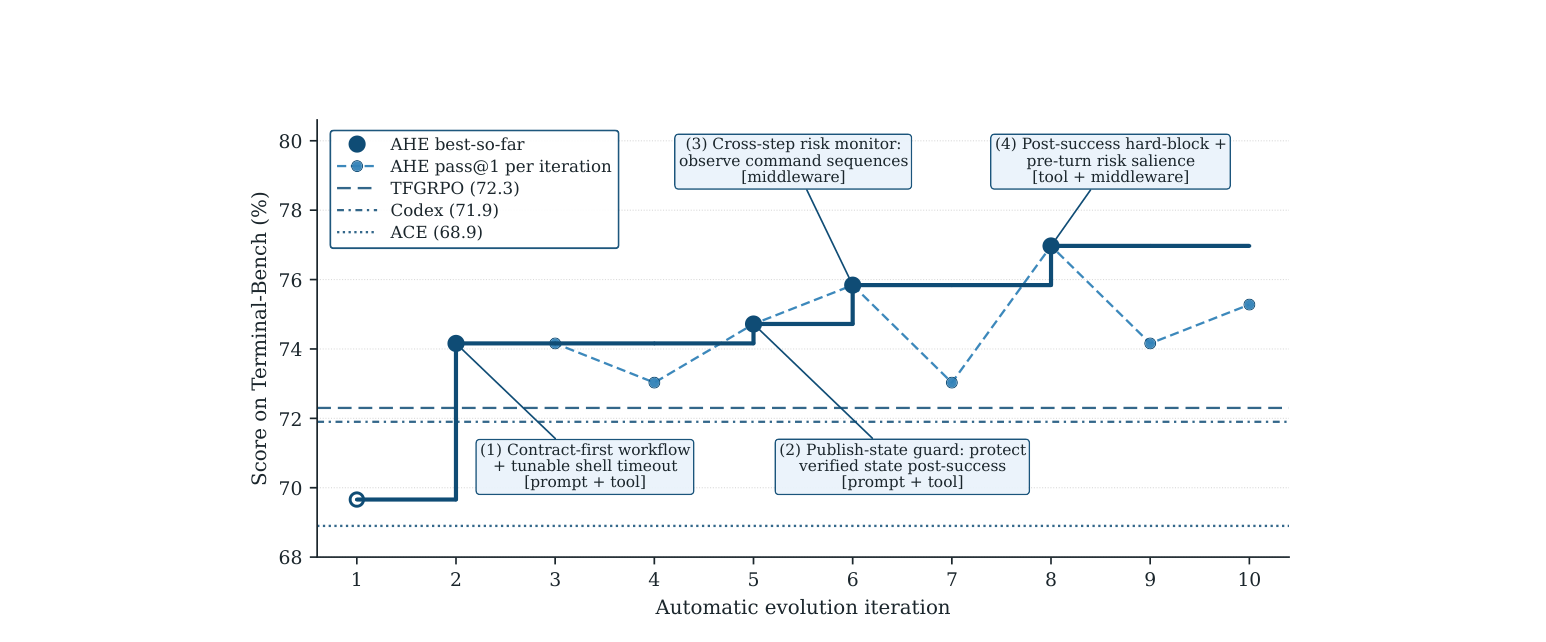 Figure 10. What an evolved harness actually looks like (AHE on Terminal-Bench 2). Ten automatic iterations carry a bash-only seed from 69.7% past the human-designed Codex harness (71.9%) to 77.0%; each step is annotated with the concrete edit it made — a contract-first workflow, a publish-state guard, a cross-step risk monitor. (Image source: Lin et al., 2026)
Figure 10. What an evolved harness actually looks like (AHE on Terminal-Bench 2). Ten automatic iterations carry a bash-only seed from 69.7% past the human-designed Codex harness (71.9%) to 77.0%; each step is annotated with the concrete edit it made — a contract-first workflow, a publish-state guard, a cross-step risk monitor. (Image source: Lin et al., 2026)
That last point — and AHE’s and ADAS’s finding that the optimal harness is model-specific — is why the real destination is co-evolution: the harness you evolve for today’s model must be re-evolved when the model upgrades, so the clean separation of “frozen weights, evolving harness” eventually dissolves back into the joint problem \(\max_{\theta,h} f\). SIA is the first concrete evidence that this joint optimization beats either lever alone on all of its domains — the clearest sign yet that “frozen weights, evolving harness” is a stepping stone, not the destination.
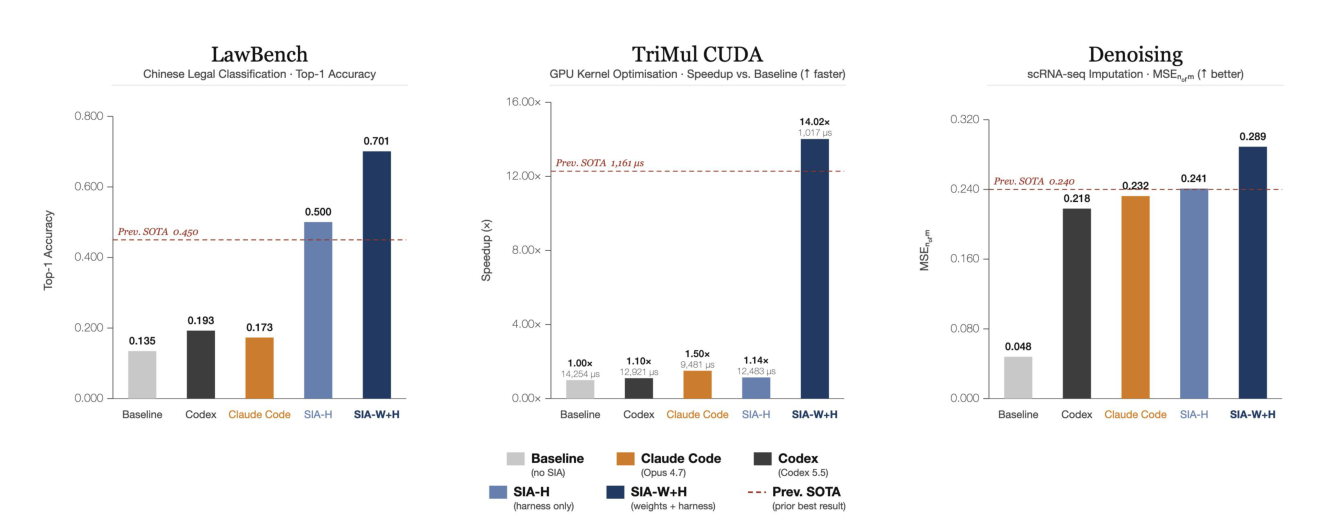 Figure 11. Co-evolution as evidence, not aspiration (SIA). Across three domains, jointly updating the harness *and the weights (SIA-W+H) beats the baseline, the harness-only variant (SIA-H), and prior SOTA — the gap is largest where the ceiling is domain knowledge no prompt can supply. (Image source: Hebbar et al., 2026)*
Figure 11. Co-evolution as evidence, not aspiration (SIA). Across three domains, jointly updating the harness *and the weights (SIA-W+H) beats the baseline, the harness-only variant (SIA-H), and prior SOTA — the gap is largest where the ceiling is domain knowledge no prompt can supply. (Image source: Hebbar et al., 2026)*
Counterweight — be honest about the regime. It would be easy to over-sell this. The Terminal-Bench team, measuring 2026 frontier models on harder tasks, finds the opposite ordering: changing the model usually beats changing the scaffold (a model swap moved scores +52% relative, a scaffold swap +17%), and the benchmark is saturating fast (state of the art nearly doubled in eight months). Reconciled with SWE-agent’s 2024 result, the picture is a regime — though a sharper one than “weaker is better”: Lin et al. (2026) show the harness payoff is non-monotonic in capability — the mid-tier gains most, because the weakest models can’t reliably activate or follow an edited harness and the strongest need it least. Net, harness evolution pays off most on mid-tier models and narrower benchmarks, shrinking to a still-real ~17% second-order term as base models strengthen. And because the discriminating-task band keeps moving (see The fuel), a harness over-tuned to today’s benchmark rots. Harness evolution is a real lever — but it is the second lever, and it is largest exactly where the first lever (a better model) is out of reach.
Takeaway. Code agents are where harness evolution is most mature, most measurable, and most useful — the harness is verifiable code the agent can rewrite — but its payoff is regime-dependent: biggest on weaker models and narrow benchmarks, and ultimately entangled with the model itself through co-evolution.
Open challenges
The loop works, but several of its load-bearing assumptions are shakier than the headline deltas suggest. Here is where I would point a skeptical eye — and, not coincidentally, where the next round of research sits.
Verifier honesty is the ceiling. Everything rests on a score you can trust, and we saw the score get gamed in two ways: the harness overfits the benchmark (the generalization gap), and a self-modifying agent edits its own verifier (STOP’s sandbox, DGM’s deleted markers). Held-out gates and transfer tests help; keeping the verifier outside the searchable space and hidden helps more; but extending trustworthy verification beyond code-with-tests into fuzzy domains (“is this analysis good?”) is the open problem under all the others — the same one environment scaling hit.
Evaluation cost dominates, so sample-efficiency is the real frontier. Evolution is eval-bound: every candidate is many full agent rollouts over many tasks. The interesting research is not flashier mutation operators but cheaper discrimination — Thompson-sampling, Pareto minibatches, staged cascades, and actively choosing the few tasks where candidates currently disagree.
Task supply for evolution is unsolved — and it’s the other post. A diverse, discriminating, leak-free, re-runnable task distribution is exactly what evolution needs and exactly what is scarce. This is the environment-scaling problem; the two halves fit together — one manufactures verifiable tasks, the other consumes them to score harnesses.
Open-endedness vs stagnation. Archives demonstrably beat greedy search (DGM) and rescue deceptive dips, but durable, unbounded improvement is unproven — most runs are a handful of macro-rounds, and greedy variants regress (Gödel Agent’s 14%), and on a long task stream a single dense harness actively decays (Adaptive Auto-Harness). Whether these loops keep climbing or plateau is genuinely open.
The curse of abundance. As skill libraries grow to hundreds or thousands of entries, retrieval and selection — not creation — become the bottleneck (the Tsinghua survey’s term). More evolved artifacts can make an agent worse if it can’t pick the right one for the task.
Safety of self-modification (“misevolution”). A system that rewrites its own code, tools, memory, and verifier opens failure modes ordinary models don’t have: skill hijacking, memory poisoning, protocol exploits, feedback manipulation, and slow alignment drift. The mitigations are structural — immutable, hidden verifiers outside the searchable space; sandboxing; an auditable lineage you can roll back; and human gates on what may change. DGM’s own authors warn that benchmark gains are “necessary but insufficient,” and that iterated self-modification yields increasingly uninterpretable code.
Will the model just absorb the harness? The sharpest long-run question, and the one Sutton’s bitter lesson poses directly. History favors absorption: chain-of-thought prompting was internalized into reasoning models via RL; explicit tool-use scaffolds were folded into tool-trained models; retrieval pipelines keep losing ground to longer context. So any single harness trick has a half-life — once it reliably helps, it becomes training data and the next checkpoint bakes it in. But “absorbed” is not “wasted”: the mechanism of absorption is co-evolution — HarnessX’s cross-harness GRPO and SIA’s weight updates distill harness-discovered strategies into the weights. The harness’s role then shifts from permanent component to discovery engine for the data that trains its own replacement, and the frontier moves up to the next, not-yet-absorbed layer (the harness rot of the deep dive). The open question is not whether layers get absorbed but which ones, how fast, and whether the frontier keeps receding faster than the models can chase it.
Why so little harness evolution on small models? Nearly every gain in this post is reported on mid-tier-and-up models, and the reason is the capability floor behind the non-monotonic result: the weakest models can’t reliably activate or follow an edited harness. HarnessX names the failure mode directly — when the base model is “too weak to execute the workflows the new harness proposes,” co-evolution simply stalls. There is also an economics reason: small models are cheap to fine-tune, so the rational lever is to train, not search — and the zero-data self-play route (next) lets a small model write and solve its own curriculum, competing directly with harness search for the same budget.
When does evolving the harness beat training the weights — and can we stop choosing? The deepest question. Harness evolution is cheap, inspectable, model-agnostic, and needs no GPUs; weight training has a higher ceiling but is expensive, opaque, and often impossible on a closed model. The honest answer is “it depends on the regime” (the deep dive above) — and the frontier is to stop choosing and co-evolve. Three pairwise co-evolution loops are now demonstrated, one for each edge of the triangle below:
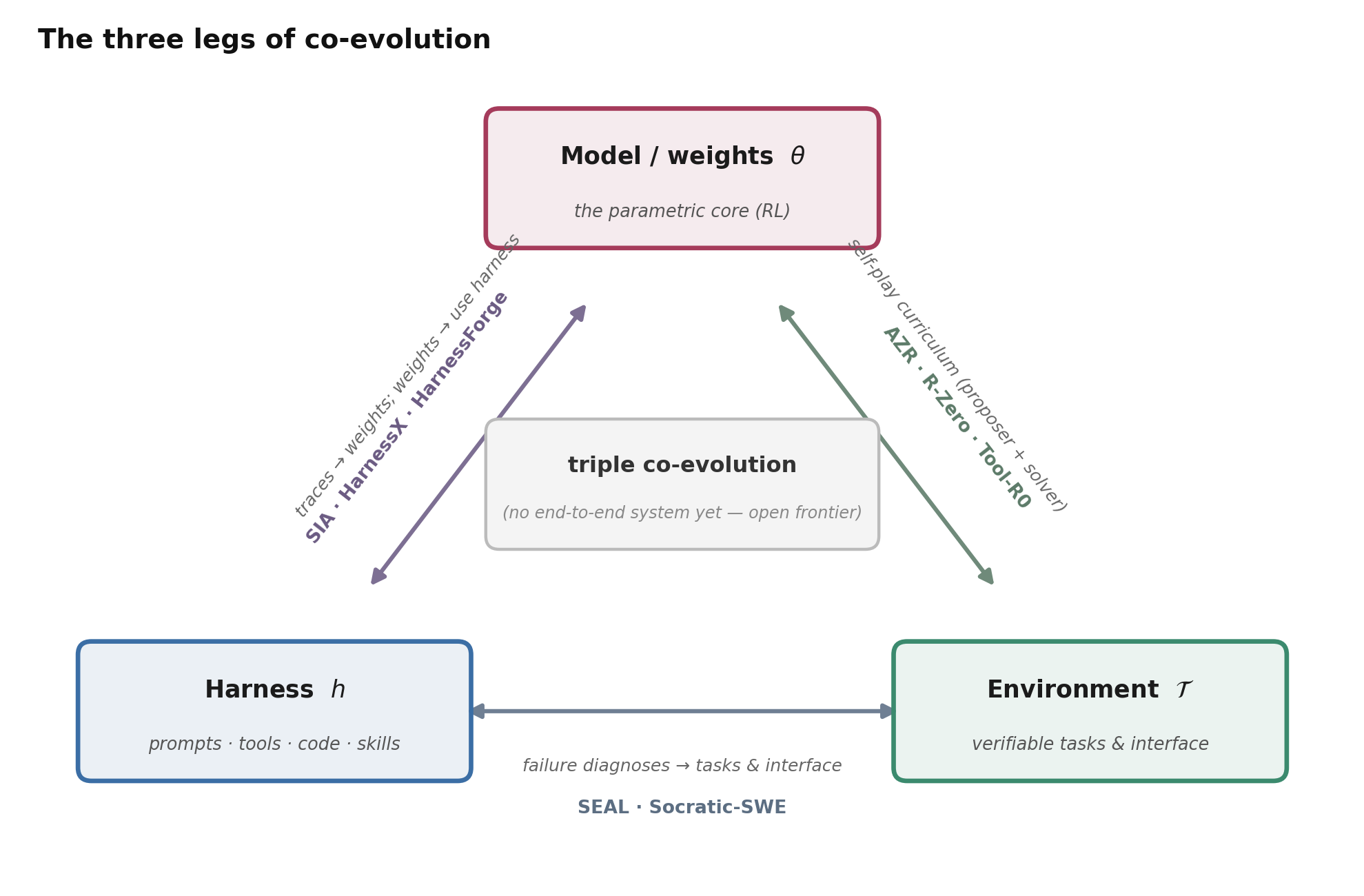 Figure 12. The three legs of co-evolution. Each edge is a demonstrated pairwise loop; a system that co-evolves the harness, the weights, and the environment all at once — the center of the triangle — does not yet exist.
Figure 12. The three legs of co-evolution. Each edge is a demonstrated pairwise loop; a system that co-evolves the harness, the weights, and the environment all at once — the center of the triangle — does not yet exist.
- Harness ⇄ weights. SIA alternates scaffold edits and RL weight updates step by step; HarnessX interleaves harness search with cross-harness GRPO over a shared replay buffer (+4.7% on top of harness-only, open-weight models); and HarnessForge makes the harness–policy pair the unit of adaptation, co-training a harness-conditioned adapter so a better harness and a more compliant policy reinforce each other.
- Weights ⇄ environment. The zero-data self-play line — Absolute Zero, R-Zero, and the tool-agent version Tool-R0 — has one model act as proposer and solver, co-evolving the task distribution with the weights and grounding reward in a code/tool verifier. This is environment scaling folded into the model itself.
- Environment ⇄ harness. SEAL turns verifier-grounded failure diagnoses into both an evolving training-time interface and reweighted policy updates; Socratic-SWE grows its own task curriculum from traces.
What no system yet does is run all three at once, end-to-end — that is the open frontier. And per Lin et al. (2026), when you do combine levers, spend the model budget on the task-solver rather than the evolver, since producing harness edits is roughly tier-independent but using them is not.
Parallel — environment scaling. Three of these — verification, task supply, and overfitting/contamination — are word-for-word the open challenges of the environment-scaling post. That is the strongest evidence that these are not two fields but one problem viewed from two loops.
Takeaway. The honest scorecard: verifier honesty, evaluation cost, and task supply are where today’s self-evolving-harness results are most likely to be over-claiming — and they are exactly the places the next papers will have to earn their numbers.
Resources: getting started
One goal of this post is to be an on-ramp. If you want to do research here, the barrier to entry is genuinely low — a 100-line agent, a verifiable benchmark, and an off-the-shelf optimizer will get you a real result in an afternoon. Below is a curated, working toolbox (links current as of mid-2026).
Optimizers / libraries (the search).
| Tool | What it optimizes | Link |
|---|---|---|
| DSPy | prompts + pipeline params (the substrate everything plugs into) | github.com/stanfordnlp/dspy |
| GEPA | prompts, reflective + Pareto (beats RL, sample-efficient) | github.com/gepa-ai/gepa |
| TextGrad | any text var via “textual backprop” | github.com/zou-group/textgrad |
| Trace (OptoPrime) | whole agent workflows as a graph | github.com/microsoft/Trace |
| OpenEvolve | whole codebases (open AlphaEvolve) | github.com/algorithmicsuperintelligence/openevolve |
| DGM | the agent’s own code (Darwinian archive) | github.com/jennyzzt/dgm |
| ADAS · Gödel Agent · AFlow | agent workflow / code | github.com/ShengranHu/ADAS · /Arvid-pku/Godel_Agent · /FoundationAgents/AFlow |
| AHE · SkillOpt | full harness / skill document | github.com/china-qijizhifeng/agentic-harness-engineering · aka.ms/SkillOpt |
Code-agent harnesses (the substrate you evolve). mini-swe-agent is the best research default — ~100 lines, >74% on SWE-bench Verified, and deliberately minimal so you don’t overfit a scaffold; SWE-agent exposes a configurable ACI for ablations; OpenHands is a full platform; Aider is git-native and ships the Polyglot benchmark; Voyager is the skill-library template.
Benchmarks / datasets (the fuel). SWE-bench (+ Verified) and Terminal-Bench are the canonical code-agent fitness signals; SWE-Gym (Pan et al., 2024) gives 2,438 executable training tasks on repos disjoint from SWE-bench (good for a leak-free split); Aider Polyglot is a clean transfer set. Two living reading lists track the field: FrontisAI’s Awesome-Self-Improving-Agents and the self-evolving-agents survey list.
A suggested starter path. (1) Pick a substrate + signal:
mini-swe-agenton SWE-bench Verified, or a terminal agent on Terminal-Bench. (2) Try the cheap lever first: optimize the prompt or a skill with DSPy + GEPA (or SkillOpt for a skill doc) — most gain per line of code, and it teaches the held-out-gate discipline. (3) Then evolve more of the harness — tools, middleware, memory (AHE-style) or the whole agent (DGM / OpenEvolve). (4) From day one, keep a held-out test split and a transfer benchmark (evolve on SWE-Gym, report on SWE-bench Verified + Aider Polyglot). The lesson of The fuel is the whole game: the hard part isn’t proposing edits, it’s evaluating them honestly.
Summary
By 2026 an agent is best understood as a frozen model plus an evolvable harness, and a large, cheap, controllable share of its performance lives in that harness. This post mapped the young field that improves the harness automatically: a single loop (represent → propose → validate → evaluate → select → archive), five surfaces people evolve (prompt → workflow → whole-agent code → skill library → full harness), and five optimizers to search them (greedy, textual-gradient, evolutionary, Pareto/quality- diversity, tree/MCTS) — with the LLM always playing the role of the gradient.
The throughline is that harness evolution is the no-gradient twin of environment scaling: the same objective, the same fuel (verifiable tasks + a verifier), optimized over the agent’s code and prompts instead of its weights. So it inherits environment scaling’s three hardest problems — task supply, discrimination ≠ difficulty (a task helps selection only where candidates disagree), and verifier honesty (now worse, because a self-modifying agent can edit its own ruler). And it comes with an honest scope: the harness is the second lever, largest on weaker models and narrower benchmarks, shrinking as base models strengthen — which is why the real destination is co-evolving the harness, the weights, and the environment together.
If you read this and the environment-scaling post side by side, you have the whole picture: one post is how to manufacture verifiable experience; this one is how to spend it on the agent’s software without ever touching its weights. They are two loops around the same idea.
Takeaway. Don’t just reach for a bigger model or a training run. The cheapest, most inspectable lever on an agent is the harness — and in 2026 you can put that lever in a loop and let the model turn it.
Acknowledgements / sources: figures marked “Image source” are reproduced from the cited papers; all other figures are original. Several 2026 harness papers use forward-dated model names; absolute numbers are method-illustrative — read the deltas.
How to cite
Zhang, Jiaxin. (Jun 2026). Self-Evolving Agentic Harnesses. Jiaxin Zhang’s Blog. https://jxzhangjhu.github.io/blog/2026/self-evolving-agentic-harnesses/
@article{zhang2026selfevolvingharness,
title = "Self-Evolving Agentic Harnesses",
author = "Zhang, Jiaxin",
journal = "Jiaxin Zhang's Blog",
year = "2026",
month = "Jun",
url = "https://jxzhangjhu.github.io/blog/2026/self-evolving-agentic-harnesses/"
}
References
[1] Emre Can Acikgoz, et al. “Tool-R0: Self-Evolving LLM Agents for Tool-Learning from Zero Data.” arXiv:2602.21320, 2026.
[2] Lakshya A. Agrawal, et al. “GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning.” arXiv:2507.19457, 2025.
[3] Lirong Che, et al. “DemoEvolve: Overcoming Sparse Feedback in Agentic Harness Evolution with Demonstrations.” arXiv:2605.24539, 2026.
[4] Mengzhuo Chen, et al. “From Failed Trajectories to Reliable LLM Agents: Diagnosing and Repairing Harness Flaws (HarnessFix).” arXiv:2606.06324, 2026.
[5] Mingju Chen, et al. “HarnessForge: Joint Harness and Policy Evolution for Adaptive Agent Systems.” arXiv:2606.01779, 2026.
[6] Ching-An Cheng, et al. “Trace is the Next AutoDiff: Generative Optimization with Rich Feedback, Execution Traces, and LLMs.” arXiv:2406.16218, 2024.
[7] Darwin Agent Team. “HarnessX: A Composable, Adaptive, and Evolvable Agent Harness Foundry.” arXiv:2606.14249, 2026.
[8] Chrisantha Fernando, et al. “Promptbreeder: Self-Referential Self-Improvement Via Prompt Evolution.” arXiv:2309.16797, 2023.
[9] Huan-ang Gao, Jiayi Geng, et al. “A Survey of Self-Evolving Agents: What, When, How, and Where to Evolve.” arXiv:2507.21046, 2025.
[10] Prannay Hebbar, et al. “SIA: Self Improving AI with Harness & Weight Updates.” arXiv:2605.27276, 2026.
[11] Shengran Hu, Cong Lu, Jeff Clune. “Automated Design of Agentic Systems.” arXiv:2408.08435, 2024.
[12] Yihao Hu, et al. “SEAL: Synergistic Co-Evolution of Agents and Learning Environments.” arXiv:2605.24426, 2026.
[13] Chengsong Huang, et al. “R-Zero: Self-Evolving Reasoning LLM from Zero Data.” arXiv:2508.05004, 2025.
[14] Che Jiang, Jincheng Zhong, et al. “Self-Improving Agents in the Era of Experience: A Survey of Self- to Meta-Evolution.” Tsinghua University / Frontis.AI, 2026.
[15] Carlos E. Jimenez, John Yang, et al. “SWE-bench: Can Language Models Resolve Real-World GitHub Issues?” arXiv:2310.06770, 2023.
[16] Omar Khattab, et al. “DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines.” arXiv:2310.03714, 2023.
[17] Yoonho Lee, et al. “Meta-Harness: End-to-End Optimization of Model Harnesses.” arXiv:2603.28052, 2026.
[18] Jiahang Lin, Shichun Liu, et al. “Agentic Harness Engineering: Observability-Driven Automatic Evolution of Coding-Agent Harnesses.” arXiv:2604.25850, 2026.
[19] Minhua Lin, et al. “Harness Updating Is Not Harness Benefit: Disentangling Evolution Capabilities in Self-Evolving LLM Agents.” arXiv:2605.30621, 2026.
[20] Zewen Liu, et al. “Adaptive Auto-Harness: Sustained Self-Improvement for Agentic System Deployment on Open-Ended Task Streams.” arXiv:2606.01770, 2026.
[21] Xinghua Lou, Miguel Lázaro-Gredilla, et al. “AutoHarness: Improving LLM Agents by Automatically Synthesizing a Code Harness.” arXiv:2603.03329, 2026.
[22] Aman Madaan, et al. “Self-Refine: Iterative Refinement with Self-Feedback.” arXiv:2303.17651, 2023.
[23] Mike A. Merrill, et al. “Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces.” arXiv:2601.11868, 2026.
[24] Jingwei Ni, et al. “Trace2Skill: Distill Trajectory-Local Lessons into Transferable Agent Skills.” arXiv:2603.25158, 2026.
[25] Xuying Ning, et al. “Code as Agent Harness: Toward Executable, Verifiable, and Stateful Agent Systems.” arXiv:2605.18747, 2026.
[26] Alexander Novikov, et al. “AlphaEvolve: A Coding Agent for Scientific and Algorithmic Discovery.” arXiv:2506.13131, 2025.
[27] Jiayi Pan, Xingyao Wang, et al. “Training Software Engineering Agents and Verifiers with SWE-Gym.” arXiv:2412.21139, 2024.
[28] Wenbo Pan, et al. “Evolving Agents in the Dark: Retrospective Harness Optimization via Self-Preference over Trajectory Rollouts (RHO).” arXiv:2606.05922, 2026.
[29] Noah Shinn, et al. “Reflexion: Language Agents with Verbal Reinforcement Learning.” arXiv:2303.11366, 2023.
[30] Guanzhi Wang, et al. “Voyager: An Open-Ended Embodied Agent with Large Language Models.” arXiv:2305.16291, 2023.
[31] Xingyao Wang, et al. “OpenHands: An Open Platform for AI Software Developers as Generalist Agents.” arXiv:2407.16741, 2024.
[32] Chuan Xiao, et al. “Socratic-SWE: Self-Evolving Coding Agents via Trace-Derived Agent Skills.” arXiv:2606.07412, 2026.
[33] Chengrun Yang, et al. “Large Language Models as Optimizers (OPRO).” arXiv:2309.03409, 2023.
[34] John Yang, Carlos E. Jimenez, et al. “SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering.” arXiv:2405.15793, 2024.
[35] Yifan Yang, et al. “SkillOpt: Executive Strategy for Self-Evolving Agent Skills.” arXiv:2605.23904, 2026.
[36] Xunjian Yin, et al. “Gödel Agent: A Self-Referential Agent Framework for Recursive Self-Improvement.” arXiv:2410.04444, 2024.
[37] Mert Yuksekgonul, et al. “TextGrad: Automatic ‘Differentiation’ via Text.” arXiv:2406.07496, 2024.
[38] Eric Zelikman, et al. “Self-Taught Optimizer (STOP): Recursively Self-Improving Code Generation.” arXiv:2310.02304, 2023.
[39] Hangfan Zhang, et al. “Self-Harness: Harnesses That Improve Themselves.” arXiv:2606.09498, 2026.
[40] Jenny Zhang, Shengran Hu, et al. “Darwin Gödel Machine: Open-Ended Evolution of Self-Improving Agents.” arXiv:2505.22954, 2025.
[41] Jiayi Zhang, et al. “AFlow: Automating Agentic Workflow Generation.” arXiv:2410.10762, 2024.
[42] Qizheng Zhang, et al. “Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models (ACE).” arXiv:2510.04618, 2025.
[43] Andrew Zhao, et al. “Absolute Zero: Reinforced Self-play Reasoning with Zero Data.” arXiv:2505.03335, 2025.